本文摘自大数据经典解读专栏 - 徐文浩
在几个月前讨论班分享了浅谈OLAP,现在回过头来看那篇文,觉得还是太乱,没有一个脉络和章法,我想对大数据的知识点进行一个总体的梳理,但现在的我还没有实际的企业经验,希望一两年后自己能动笔写下,自己的感悟。
摘要
在学习的过程中,很容易一头钻进一个小领域,这样很容易迷失,尤其是在大数据这样知识点繁杂的领域,对其进行一个宏观的梳理,有助于构建一个完整的知识体系,也能明白自己需要往哪方面钻研。
从整体来看大数据技术,可以从三个维度来切入,“分布式系统”,“存储引擎”,“计算引擎”,这三部分是大数据的主要知识点。当然还有一些别的部分,比如安全认证,通信方式等,这些其实也可以划分到“系统”中去。对知识进行梳理,每个人的理解有些微区别不是事儿,主要是把握核心的脉络。
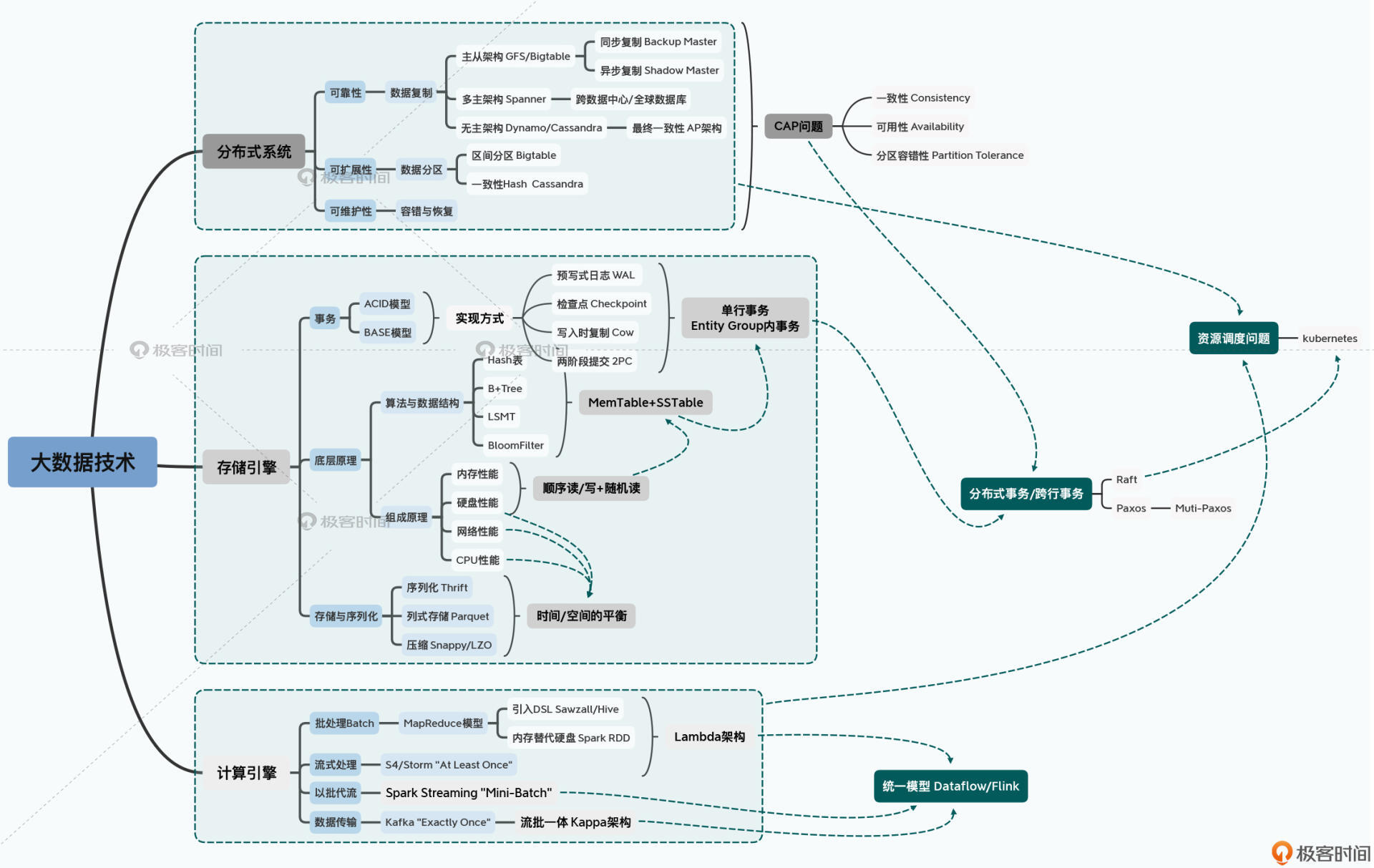
在我看来,现在流行的大数据引擎都较为专一化,往往是适用于某个场景,解决了某个问题,基于这样的考虑,那么其对应的存储引擎的数据结构就基本上定下了,分布式系统的CAP问题也基本上定下了(主要指一致性的问题),计算引擎是流式还是批式,或者其他的存储方式也差不多能决定。反过来说,当我们看到一个大数据引擎用的数据结构,架构,基本上就能知道它的适用场景了。
分布式系统
大数据系统都是分布式系统,这是毋庸置疑的,因为大数据就是在单机场景解决不了数据处理的问题才提出的概念。
1998年,加州大学的 Eric Brewer 提出了分布式系统有三个指标,也就是著名的CAP定律:
- Consistency
- Availability
- Partition tolerance
一般认为,这三个指标是不能同时满足的,主要是因为一致性和可用性不能同时满足,一些人认为Spanner是同时满足CAP的。这主要是因为通信可能会失败,而P是分布式一定会满足的,所以A和C往往需要权衡一下。
CAP指的是分布式系统,对于分布式数据系统,专栏中提到由三个特性,可靠性、可扩展性和可维护性,这三个特性是可以同时满足的喔,和CAP的不可能三角不一样。
数据的可靠性主要指备份,数据可能是丢失的,所以像HDFS这样的分布式文件系统一般都是三备份。这部分又有主从架构、多主架构以及无主架构的选择。
在最常见的主从架构里,我们根据复制过程,可以有同步复制和异步复制之分。同步复制的节点可以作为高可用切换的 Backup Master,而异步复制的节点只适合作为只读的 Shadow Master。很多人会采用这种方式做一个Mysql的高可用集群。
对于分布式系统,要根据系统的场景在这些选择中做出抉择。
单节点的存储引擎
事务
事务时OLTP系统所必须拥有的特性,事务也就是 ACID ,原子性(Atomic)、一致性(Consistency)、隔离性(Isolation)以及持久性(Durability)。在大数据领域,因为分布式的存在,经常会退化到一个 BASE 的状态,基本可用(Basically Available)、软状态(Soft State)以及最终一致性(Eventually Consistent)。
无论是 ACID 还是 BASE,在单机上,预写日志(WAL)、快照(Snapshot)和检查点(Checkpoints)以及写时复制(Copy-on-Write)这些技术都是经常使用的。只要写入的数据记录是在单个分片上,我们就可以保障数据写入的事务性,所以我们很容易可以做到单行事务,或者是进一步的实体组(Entity Group)层面的事务。
如何写入和存储
关于存储,主要有几个方面的考虑:
- 顺序读写比随机读写快,这是计算机硬件特性决定的
- 内存比磁盘IO快
- 存储的数据结构也有影响,比如 Hash 表的时间复杂度是 O(1),B+ 树的时间复杂度是 O(logN)
这样,通过结合硬件性能、数据结构和算法特性,我们会看到分布式数据库最常使用的,其实是基于 LSM 树(Log-Structured Merge Tree)的 MemTable+SSTable 的解决方案。典型的就是 HBase。
数据序列化
出于存储空间和兼容性的考虑,我们会选用 Thrift 这样的二进制序列化方案。
为了在分析数据的时候尽量减少硬盘吞吐量,我们则要研究 Parquet 或者 ORCFile 这样的列存储格式,这些存储格式可以提供一些元数据以加速读取。
为了在 CPU、网络和硬盘的使用上取得平衡,我们又会选择 Snappy 或者 LZO 这样的快速压缩算法。
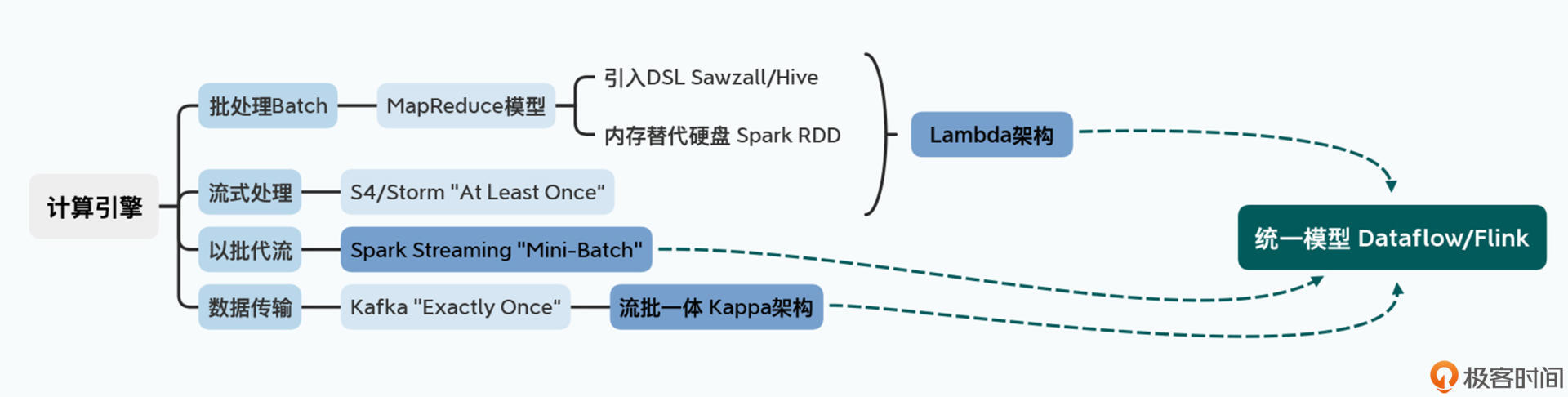
计算引擎
计算引擎是大数据领域进化和迭代最快的部分,也是不同引擎区别最大的地方。捋一下大数据处理引擎的进化过程:
- 我们先有了最原始粗糙的 MapReduce 来进行批数据处理,然后围绕它不断迭代出了让数据处理更快的 Spark 和让数据处理更容易的各种 DSL(比如 Sawzall/Pig 和 Hive)。
- 然后我们围绕着实时数据处理,有了“最少一次”的 S4/Storm,并把它和批处理综合到一起,产生了著名的 Lambda 架构。
- 紧接着有了“以批为流”,通过 Mini-Batch 来进行实时数据处理的 Spark Streaming,以及“流批一体”,能够做到“正好一次”的 Kafka 和 Kappa 结构。
- 最后,还是 Google 一锤定音,给出了统一的 Dataflow 模型,并伴随着有了 Apache Flink 和 Apache Beam 这两个开源项目。
随着 Dataflow 论文的发表,我们可以看到整个大数据的处理引擎,逐渐收敛成了一个统一的模型,大数据领域发展也算有了一个里程碑。
(真的统一了么?)
调度系统
总结来说,分布式系统、存储引擎和计算引擎就共同构成了大数据的核心技术。更进一步,随着多种分布式系统的混排,又产生了 Kubernetes 这样的资源管理和调度系统。而所有的这些技术之间,都不是各自独立,而是相互关联的。
如何学习大数据知识
首先,是从第一性原理出发,尝试自己去设计系统和解决问题。
一篇篇的大数据论文,并不是教科书里的一个章节或者一个知识点,而是对于一个重要的系统问题的解决方案。在读论文之前,先尝试自己去思考和解决对应的问题,有助于你更深刻地理解问题和解决方案的重点。
比如,在学习 Megastore 的论文之前,你可以问一问自己下面这两个问题:
- 如果要在 Bigtable 上为数据表加上 Schema,我该怎么做?
- 如果我希望能够在 Bigtable 上,支持跨行事务,可以从哪里起步?
还可以再加一个问题:如果我要涉及一个符合这样场景的 / 解决这个问题的引擎,我要怎么做?
其次,是多做交叉阅读和扩展阅读。
论文本身往往只有 10 来页,非常精炼,对于很多知识点,往往就只有一个小片段,甚至只有一两句话,所以交叉阅读和扩展阅读少不了。根据你需要深入了解的知识点,你可能要回顾之前已经解读过的论文,也可能需要去阅读一些开源项目的代码,或者是一些计算机经典书籍中相关的章节,帮你彻底理解对应的问题。
比如,学习 Bigtable 论文的时候,论文里只告诉你底层的数据存储是 SSTable。而通过学习 LSM 树,或者是去读一下 LevelDB 的源码,你不仅可以理解 SSTable 的底层实现。还能帮助你深入理解针对硬件性能去设计数据结构,乃至系统中特定的组件。
是的,对于大数据知识,纸上得来终觉浅,还是要去代码看!
最后,是给自己制定一个明确的学习目标,然后围绕学习目标,进行泛读和精读、理论和实践的结合。
大数据的论文,是一个一个“点”,但是每一个点深挖下去,都可以串联到大量的理论和工程知识。而如果通过阅读论文追求学得“多”,其实意义并不大。最合适的学习方法,我认为是有针对性地针对自己的目标,来学习。
目标驱动行为!
如果你的工作就是开发和维护大数据系统中的某个项目,比如 HBase、Flink,那么你就精读对应的论文,泛读其他的相关论文,并对于你所关心的项目源码进行深入挖掘。搞清楚每一个设计背后选择的根本原因,搞清楚它为什么这么设计。
如果你原先是做后端应用开发,想要学习大数据知识,转向大数据领域的开发。那么,搞清楚每篇论文和每个系统的应用场景,尝试通过 Google Cloud 或者其他的云系统,多尝试用一用这些大数据系统,会更有帮助。
如果你就是想要提升自己的理论知识和架构能力,那么我建议你放慢节奏。搞清楚论文里每一个关键设计点的原理,尽量多阅读我给到的推荐阅读材料。甚至你不妨可以动手试一试,去实现其中的一些算法和组件,这是最有效的办法。
其实,归根到底,学习的成效不是表面知识知道得多,而是要真的掌握和理解这些知识。AngelList 的创始人纳瓦尔·拉威康(Naval Ravikant)说过这样一段话,听了之后让人觉得“与我心有戚戚焉”。

这些涉及的很多知识我都学过,但是没有深入,最主要的是缺乏实践,所以理解没有那么深刻。