这篇是学习徐文浩的大数据经典论文专栏所记。
摘要
随着数据量的不断增大,如何对于海量数据进行处理。Google在03,04,06年分别发表了被称为谷歌三驾马车的经典论文GFS、MapReduce和Bigtable,分别解决了海量数据场景下存储,计算和在线查询的问题。现在看来,这些经典的技术也存在各自的缺陷,因为MapReduce编程麻烦,出现了Hive;因为Bigtable缺少事务,出现了Megastore;因为执行引擎的延时很高,所以出现了Dremel;因为磁盘IO的性能问题,出现了Spark。
后来,随着实时计算的需求出现,批处理和流处理的概念兴起,Google 的 Dataflow 论文对于实时处理进行了总结,这对于 Spark 和 Flink 的实现有很大的影响。
大数据还有一个核心的概念是封装和抽象,是把数据中心当作一台计算机,提供一种服务的背后是一个集群,对于集群的通信和调度,存在一致性问题,为了解决这一问题,有Paxos协议,以及现在更流行的Raft协议。对于跨数据中心的问题,Google在12年发表的Spanner被很多人认为可以同时满足CAP。
过去对于集群的部署方式是一个计算集群占一系列的服务器,但很多时候这些服务器资源都是闲置的,对于占满硬件资源的需求,让Kubernetes大放光彩,现在有很多Spark on k8s的研究。
大数据的发展在过去二十年日新月异,前阵子看到有文章说,最近出现的开源爆款已经是3-4年前的事了,大数据是否进了停滞呢?我认为不是的,未来的数据量只会更大,到以后会不会有新的划时代技术出现呢?既然误打误撞走进了这条路,那就走好它吧!
三架马车和其缺点
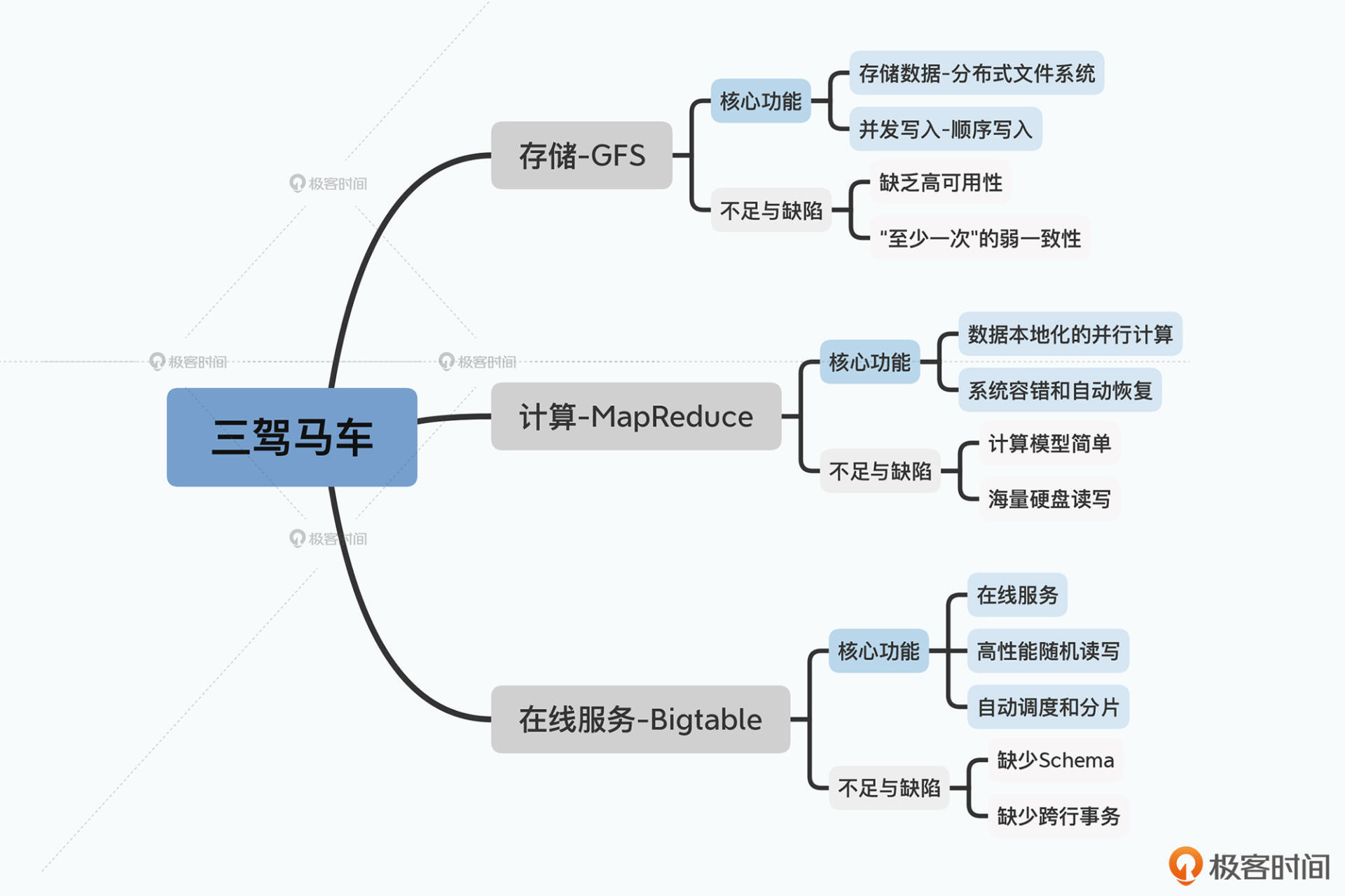
三驾马车都有对应的开源实现:
- GFS -> HDFS
- Google MapReduce -> MapReduce
- Bigtable -> HBase
很多人将大数据的开源视为03年开始的这三篇论文,但它们也依赖了之前的工作。
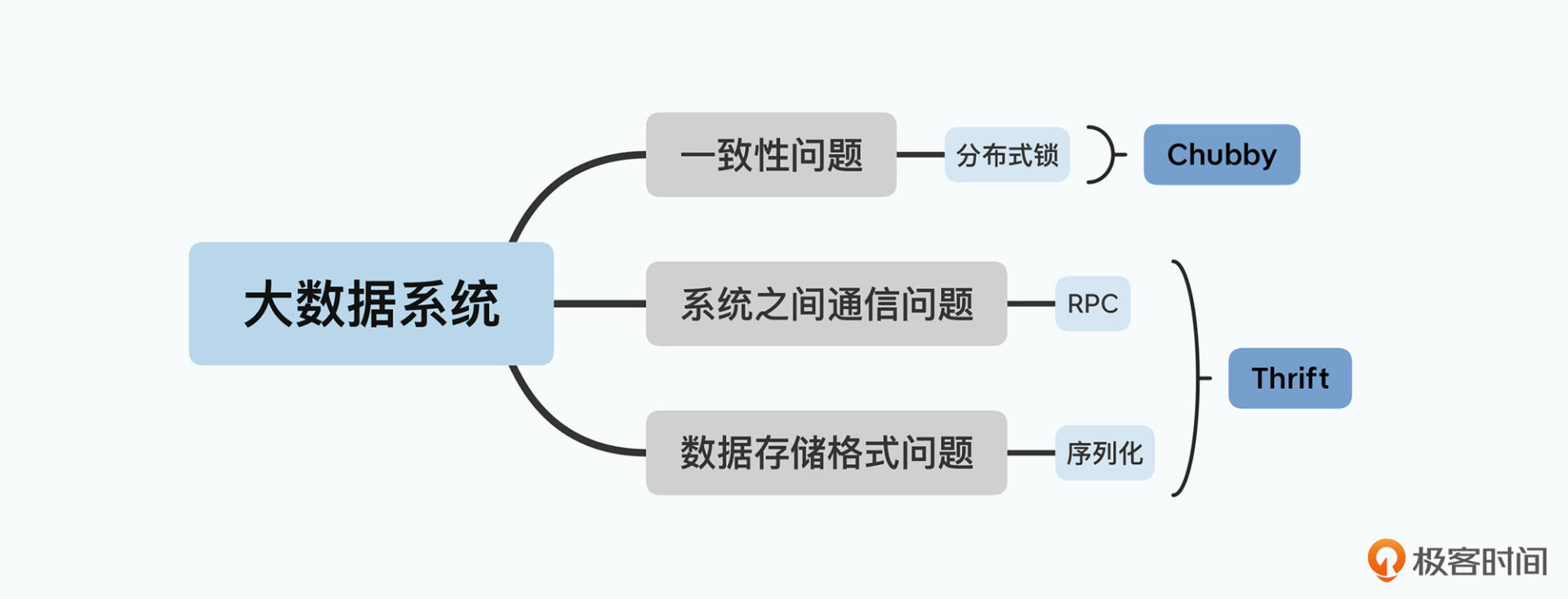
第一个是为了保障数据一致性的分布式锁。对于这个问题,Google 在发表 Bigtable 的同一年,就发表了实现了 Paxos 算法的 Chubby 锁服务的论文。
第二个是数据怎么序列化以及分布式系统之间怎么通信。Google在论文中没有提到这一点,但HBase用了 Thrift 作为和外部多语言进行通信的协议。
MapReduce的发展
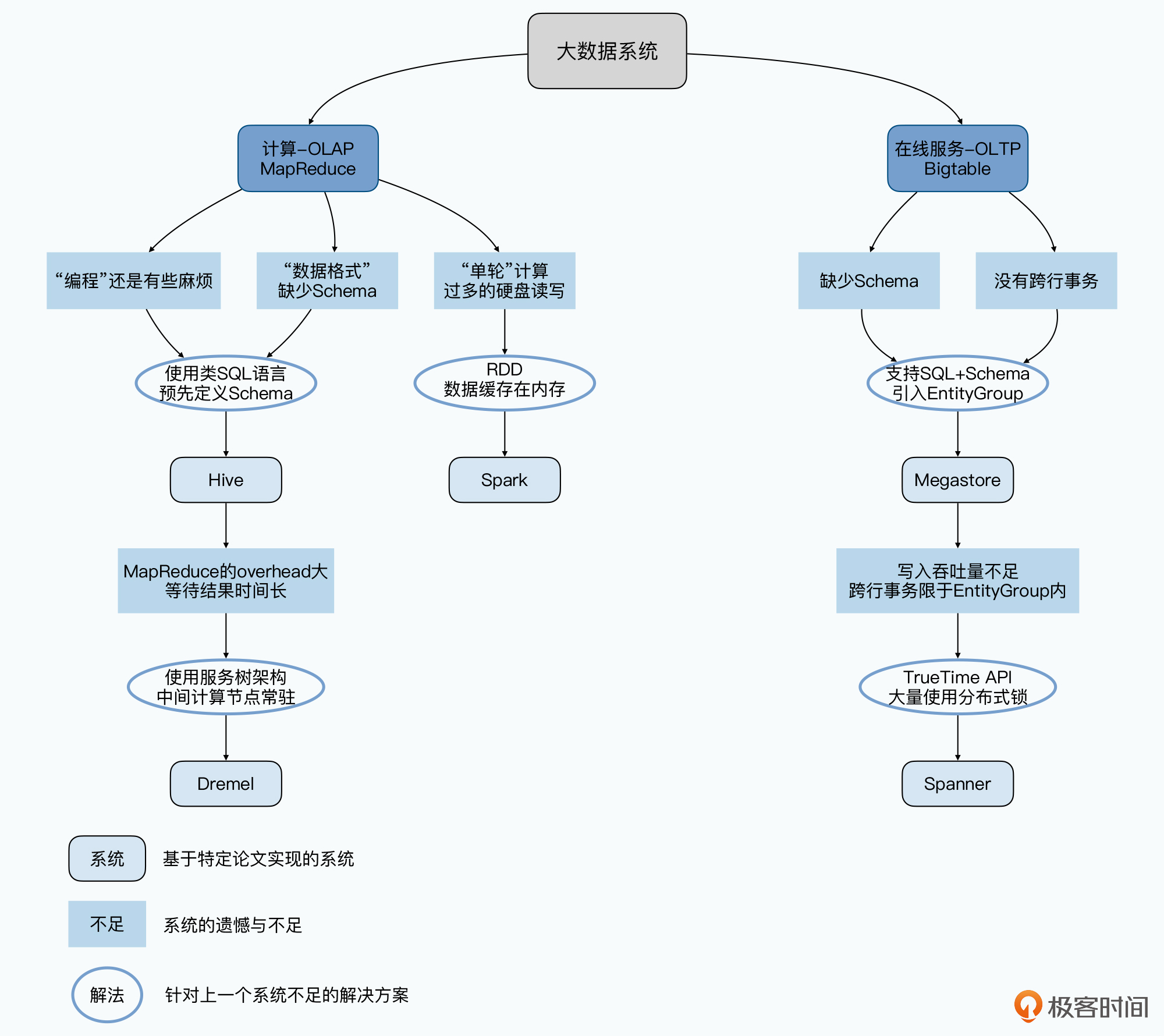
MapReduce虽然不需要工程师再去写分布式代码了,但仍然需要编程,对于数据分析人员来说不友好,它进化的方向就是通过一门 DSL,进一步降低写 MapReduce 的门槛。Google发表了Sawzall,Yahoo 实现了 Pig,但最终胜出的是FaceBook09年发表的Hive,写HQL和写SQL差不多,背后执行的还是多轮的MapReduce。
MapReduce还设计到落盘问题,实时性很差,也不能很好解决像机器学习这样的多轮迭代计算。
对于实时性,Google 在 2010 年,发表了 Dremel 这个交互式查询引擎的论文,采用数据列存储 + 并行数据库的方式。
对于多轮迭代,则是Spark大放异彩,Spark还提供了Mllib来实现机器学习,Spark SQL来实现Adhoc。
Bigtable的发展
Bigtable和HBase为了伸缩性放弃了关系型数据库的特性,不支持事务。Google 先是在 2011 年发表了 Megastore 的论文,在 Bigtable 之上,实现了类 SQL 的接口,提供了 Schema,以及简单的跨行事务。
其次是异地多活和跨数据中心问题。Google 在 2012 年发表的 Spanner,能够做到“全局一致性”。
流式处理数据
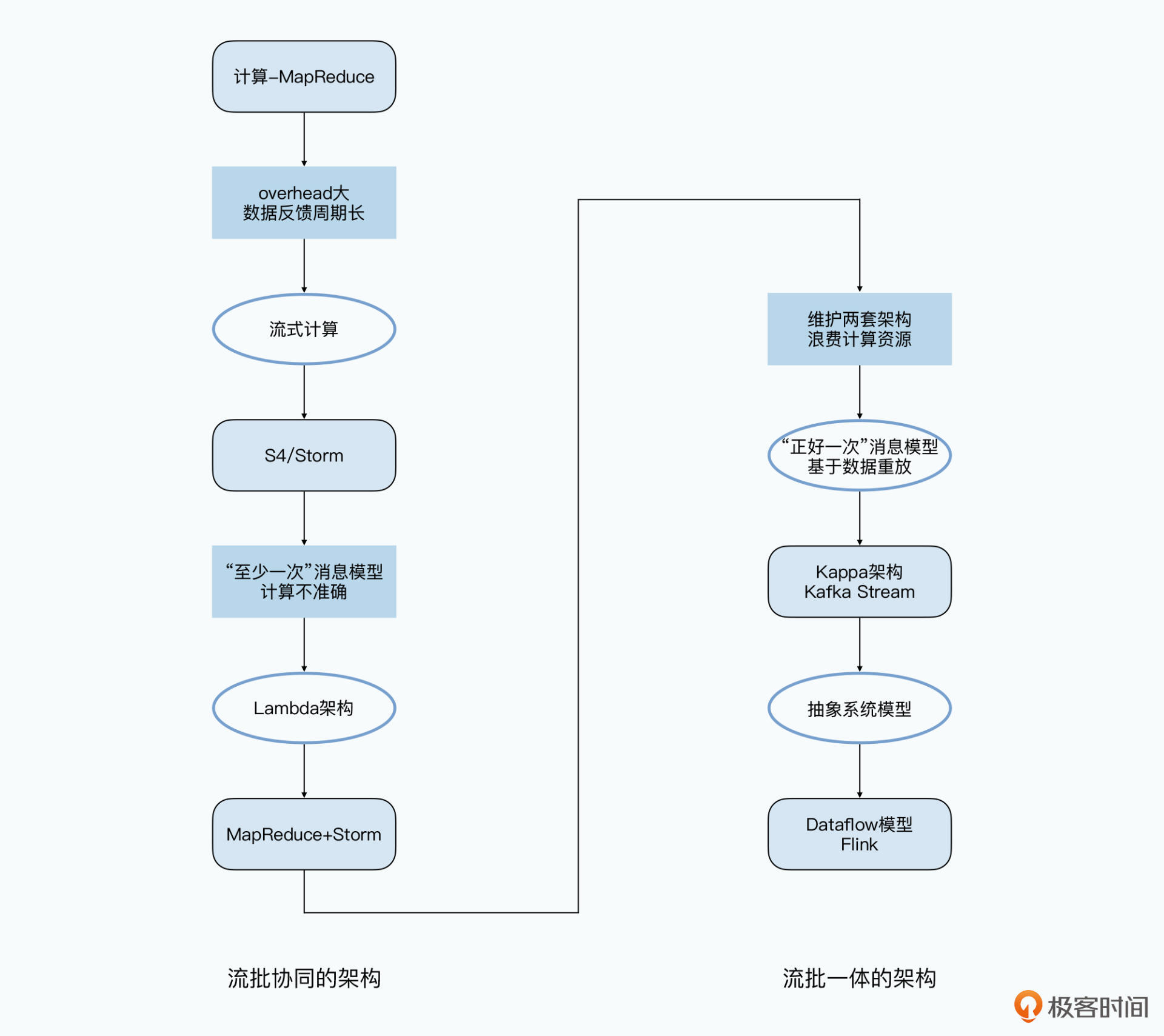
Hive和Spark主要是用来进行ETL的,允许几分钟乃至几个小时的延时,为了解决这一问题,流式数据出现。
经典的工作是Yahoo2010年的S4,Nathan Marz 开源的Storm,和 GFS 一样,Storm 还支持“至少一次”(At-Least-Once)的数据处理。Nathan 还基于基于 Storm 和 MapReduce 提出了 Lambda 架构,它可以称之为是第一个“流批协同”的大数据处理架构。
2011年,Kafka作为一个消息队列发布了,但是由于 Kafka 里发送的消息可以做到“正好一次”(Exactly-Once),所以大家就动起了在上面直接解决 Storm 解决不好的消息重复问题的念头。
2015 年,Google 发表的 Dataflow 的模型,可以说是对于流式数据处理模型做出了最好的总结和抽象。一直到现在,Dataflow 就成为了真正的“流批一体”的大数据处理架构。而后来开源的 Flink 和 Apache Beam,则是完全按照 Dataflow 的模型实现的了。
服务器资源的调度
一致性问题
分布式系统中,一致性是逃避不开的问题,特别是当服务器越来越多的时候,对于一致性的要求也更高。这一部分,绕不开Paxos,Raft,ZAB。
资源利用问题
过去搭一个集群,往往是用独占一些列的服务器,但是计算任务占的资源并不是一直很高,很多时候,我们的服务器资源都是闲置的。在集群规模很大的时候,这也会带来很大的浪费。这是 Kubernetes 近年来越来越火的原因。
开源大数据架构的 100 篇论文 - 推荐~