浅谈OLAP的起源,场景,关键技术,以及目前流行的OLAP系统。
本文主要参考:
常见开源OLAP技术架构对比 - 高英举的文章 - 知乎
关于OLAP数仓,这大概是史上最全面的总结!- 温正湖 大数据技术架构
概览OLAP——起源,概念及现状
OLAP AND BUSINESS INTELLIGENCE HISTORY – olap.com本文还参考了:
浅谈OLAP系统核心技术点 - neoReMinD的文章 - 知乎
数据仓库和OLAP技术回顾综述
BigData-‘基于代价优化’究竟是怎么一回事? - 范欣欣
TiDB 源码阅读系列文章(七)基于规则的优化 - TiDB Robot的文章 - 知乎
大数据OLAP系统(1)——概念篇 - 歌湾汐云
OLAP的类型延伸阅读:
Nanda A, Gupta S, Vijrania M. A Comprehensive Survey of OLAP: Recent Trends[C]//2019 3rd International conference on Electronics, Communication and Aerospace Technology (ICECA). IEEE, 2019: 425-430.
Dhanasree K, Shobabindu C. A survey on OLAP[C]//2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC). IEEE, 2016: 1-9.
主要内容
OLAP概念和起源
OLAP概念和场景
OLAP起源
OLAP类型细分
OLTP vs OLAP
浅谈OLAP关键技术
存储
计算
优化
主流OLAP系统简介
- Hive、Spark SQL、Flink SQL、ClickHouse、Elasticsearch、Impala、Doris、Druid、Kylin
OLAP概念和起源
什么是OLAP?
OLAP(OnLine Analytical Processing),即联机分析处理。OLAP对业务数据执行多维分析,并提供复杂计算,趋势分析和复杂数据建模的能力。它主要用于支持企业决策管理分析,是许多商务智能(BI)应用程序背后的技术。 OLAP使最终用户可以对多个维度的数据进行即席分析,从而获取他们所需知识,以便更好地制定决策。OLAP技术被定义为实现“快速访问共享的多维信息”的能力。
OLAP发展历史
数据库概念最初源于1962年Kenneth Iverson发表的名为“A Programming Language” (APL)的著作,第一次提出了处理操作和多维变量的的数学表达式,后来APL语言由IBM实现。
随后数据库之父Edgar F. Codd提出了著名的关系数据模型理论《A Relational Model of Data for Large Shared Data Banks 》,为后面数据库发展奠定基础。
第一款OLAP产品Express于1975年问世,随着被Oracle收购后繁荣发展了30余年,最后由继任者Oracle 9i替代。
1989年,SQL语言标准诞生,它可以从关系数据库中提取和处理业务数据。这可能是个转折点。在80年代,电子表格在OLAP应用中占绝对主导地位;而90年代以后,越来越多的基于数据库的OLAP应用开始出现。
OLAP这个名词是数据库之父Edgar F. Codd于1993年在文章《Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate》提出,他总结了OLAP产品的12个原则:
准则1 OLAP模型必须提供多维概念视图 Multidimensional conceptual view OLAP
- 分析用户能自然的视企业为一个多维模型,例如,利润可以按区域,产品,时间,或方案(如实际,预算或预测)查看。多维数据模型能让用户更直接和方便的操作数据,包括“切片和切块”
准则2 透明性准则 Transparency
- OLAP应该是开放系统体系结构的一部分,该体系结构可以嵌入到用户期望的任何位置,而不会影响宿主工具的功能。不应把OLAP工具的数据源暴露给用户,数据源可能是同构的或异构的。
准则3 存取能力准则 Accessibility
- OLAP工具应该能够应用自己的逻辑结构来访问异构数据源,并执行向用户呈现连贯视图所需的任何转换。工具(而不是用户)应关注物理数据的来源。
准则4 稳定的报表能力 Consistent reporting performance
- 随着维度数量的增加,OLAP工具的性能不会受到显著影响。
准则5 客户/服务器体系结构 Client/server architecture
- OLAP工具的服务器组件应该足够智能,各种客户端可以轻松地连接它。服务器应该能够在不同的数据库之间映射和合并数据。
准则6 维的等同性准则 Generic Dimensionality
- 每个数据维度的结构和操作能力都应相同。
准则7 动态的稀疏矩阵处理准则 Dynamic Sparse Matrix Handling
- OLAP服务器的物理结构应具有最佳的稀疏矩阵处理。
准则8 多用户支持能力准则 Multi-User Support
- OLAP工具必须提供并发检索和更新访问,完整性和安全性。
准则9 非受限的跨维操作 Unrestricted Cross-dimensional Operations
- 计算设施必须允许跨任意数量的数据维度进行计算和数据处理,并且不得限制数据单元之间的任何关系。
准则10 直观的数据操纵 Intuitive Data Manipulation
- 合并路径中固有的数据操作,例如向下钻取或缩小,应通过对分析模型单元的直接操作来完成,而不需要使用菜单或跨用户界面多次行程。
准则11 灵活的报表生成 Flexible Reporting
- 报告工具应以用户想要查看的任何方式显示信息。
准则12 不受限的维与聚集层次 Unlimited Dimensions and Aggregation Levels
OLAP场景的关键特性
这个关键特性是从ClickHouse官方摘的,比较适合ClickHouse的场景,但是不一定适合其它的OLAP系统,但是很多特性是相通的。
绝大多数是读请求
数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
已添加到数据库的数据不能修改。
对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
宽表,即每个表包含着大量的列
查询相对较少(通常每台服务器每秒查询数百次或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
事务不是必须的
对数据一致性要求低
每个查询有一个大表。除了他以外,其他的都很小。
查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
OLAP核心概念
维度(Dimension):维度是描述与业务主题相关的一组属性,单个属性或属性集合可以构成一个维。如时间、地理位置、年龄和性别等都是维度。
维的层次(Level of Dimension):一个维往往可以具有多个层次,例如时间维度分为年、季度、月和日等层次,地区维可以是国家、地区、省、市等层次。这里的层次表示数据细化程度,对应概念分层。后面介绍的上卷操作就是由低层概念映射到高层概念。概念分层除了可以根据概念的全序和偏序关系确定外,还可以通过对数据进行离散化和分组实现。
维的成员(Member of Dimension):若维是多层次的,则不同的层次的取值构成一个维成员。部分维层次同样可以构成维成员,例如“某年某季度”、“某季某月”等都可以是时间维的成员。
度量(Measure):表示事实在某一个维成员上的取值。例如开发部门汉族男性有39人,就表示在部门、民族、性别三个维度上,企业人数的事实度量。
举实际的例子:维度可以理解为一个字段,也就是一列,这列在存储的时候可以根据partition进行分区,比如CK中,建表的时候指定的分区键,或者hive的分桶表。

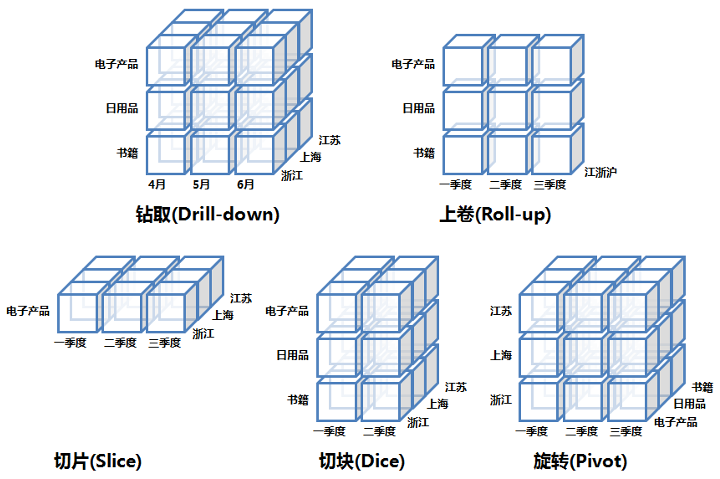
基本操作
下探(Drill down):维度是有层次的,下探表示进入维度的下一层,将汇总数据拆分到下一层所在细节数据信息,如下图从第二季度下探到看4、5、6月的明细数据。
上钻(Drill up): 下探的反向操作,回到更高汇聚层的汇总数据。
切片(Slice):切片可以理解成把立体按某一个维度进行切分,就可以看两维数据,如图中按电子产品切分,看到的是时间和地理位置关系的二维数据。
切块(Dice):相对于切片是按一个点切分,切块就是按一个范围(区间)来做切分。
旋转(Pivot):维的行列位置交换,换一个视角分析数据。
OLAP类型细分
多维 OLAP ( Multi-dimensional OLAP )
MOLAP的典型代表是:Druid,Kylin,MOLAP一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析。
优点
出色的性能:MOLAP多维数据集可用于快速信息检索, 是切片和切块操作的最佳选择。
可以执行复杂的计算:创建多维数据集时已预先生成所有评估。因此, 不仅可以进行复杂的计算, 而且可以快速返回。
缺点
它可以处理的信息量有限:由于所有计算都是在构建多维数据集时执行的, 因此不可能在多维数据集本身中包含大量数据。
关系型 OLAP ( Relational OLAP )
ROLAP的典型代表是:Presto,Impala,GreenPlum,ClickHouse,Elasticsearch,Hive,Spark SQL,Flink SQL
数据写入时,ROLAP并未使用像MOLAP那样的预聚合技术;ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,需要更高的资源和算力。
ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
优点
ROLAP 不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。
缺点
当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
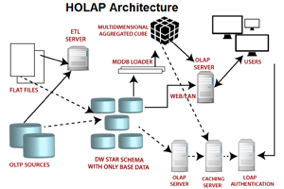
混合 OLAP ( Hybrid OLAP )
HOLAP将MOLAP和ROLAP的最佳功能集成到一个体系结构中。当聚合存储在预先计算的多维数据集中时, HOLAP系统会将大量的详细数据保存在关系表中。 HOLAP还可以从多维数据集向下钻取到关系表, 以获取描绘的数据。
优点
同时具备MOLAP和ROLAP的优点。
HOLAP平衡了磁盘空间需求, 因为它仅将聚合信息存储在OLAP服务器上, 而详细记录保留在关系数据库中。因此, 不会保留详细记录的重复副本。
缺点
HOLAP体系结构复杂, 因为它同时支持MOLAP和ROLAP服务器。
OLTP vs OLAP
本质上是设计目标的不同,也就是针对场景的不同。
OLTP(On-Line Transaction Processing),联机事务处理,一般用于业务系统。OLTP对事务性处理的要求非常高,一般都是高可用的在线系统,主要基于传统的关系型数据库。其上的应用,一般以小的事务以及小的查询为主。评估其系统的时候,一般看其每秒执行的Transaction以及SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction(增、删、改)往往达到几百上千个,select查询语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行交易系统、证券交易系统等。
OLAP,一般用于分析系统。一般以大数据量的查询为主,修改和删除的操作较少。在这样的系统中,SQL语句的执行量不是考核指标,因为一条语句的执行时间可能会很长,读取的数据也非常多。所以,评估其系统的时候,往往是看系统的吞吐量、复杂查询响应时间、数据装载性能等。
小结
OLTP 的主要操作是插入、更新和删除,而 OLAP 的主要操作是提取多维数据进行分析。
OLTP 具有较短但频繁的查询,而 OLAP 具有耗时较长且不太频繁的查询。 与 OLTP 相比,OLAP 事务的处理时间更长,查询也较为复杂。
OLTP 数据库中的表必须规范化(3NF),而 OLAP 数据库中的表可能未规范化。
OLTP 经常在数据库中执行事务,如果任何事务在中间失败,可能会损害数据的完整性, 因此必须注意数据完整性。 而在 OLAP 中,事务不太频繁,也不会太在意数据完整性。
浅谈OLAP关键技术
存储
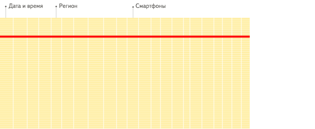
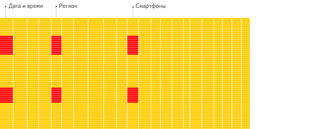
行式存储 vs 列式存储

下面是ClickHouse官网的对比,查询行的时候会涉及整行的数据,而列只需要特定字段即可。对于OLAP来说,查询的数据量特别大,用列存能减少IO。
压缩
优点:减少存储;减少IO
对于基本类型,例如数值、String等,列存可以使用合适的编码,减少数据体积,在C-Store论文中对于是否排序、NDV(Number of Distince Values)区分度,这4种排列组合,给出了一些方案,例如数值类型,无序且NDV小的,转成bitmap,然后bit-packing编码。
对于复杂类型,嵌套类型的可以使用Google Dremel论文提出Striping/Assembly算法(开源Parquet),使用Definition Level+Repetition Level做编解码。一些数值类型有时也可以尝试大一统的用bit shuffle做转换,配合压缩效果也不错,例如KUDU和Doris中有应用。在编码基础上,还可以进行传统的压缩,例如lz4、snappy、zstd、zlib等。
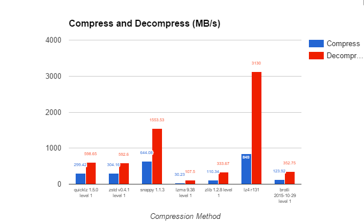
选择压缩算法的时候需要对于压缩速率和压缩率进行一个抉择,对于压缩速度较快的算法,其压缩率往往不高,压缩率高的算法往往压缩速率不高,需要根据场景选择合适的压缩算法,CK默认是LZ4压缩。
分区
数据分片是将数据分到不同的节点存储,数据分片的基础上,可以进行更细粒度的分区(partition),便于做分区剪枝(partition prune),直接跳过不需要扫描的文件。
分片(sharding)策略按照range,可以优化OLAP的范围查询和快速点查;按照hash分区,可以充分打散,有效解决hot spot热点。将二者结合,做二级分区(two-level),例如阿里云ADB、ClickHouse、KUDU,支持DISTRIBUTED BY HASH再PARTITION BY RANGE,而Doris一般先按时间一级分区,更好做冷热数据区分,二级分区分桶采用hash。
就我的理解,分区有两种,第一种是分区裁剪,其用途是减少数据的扫描,和列式存储目的类似。第二种是哈希分区,其目的是减少查询数据总去特定节点特定磁盘查询,和数据分片到不同的服务器类似。
计算
查询模型
SQL语言是OLAP的标配,一个完整的SQL查询步骤包括1)SQL词法解析,语法解析,2)形成抽象语法树(AST),3)校验检查,4)AST转成关系代数表达式(relational algebra),5)根据关系代数表达式生成执行计划,先生成逻辑执行计划(logical plan),6)经过优化器生成最优的执行计划,7)根据执行计划生成物理执行计划(physical plan),8)最终交由执行器执行并返回结果。
由SQL到AST的过程,类库和工具较多,C++可用Lex/Yacc,Java可用JavaCC/ANTLR,也可以自己手写实现。由AST到关系代数表达式,可以使用visitor模式遍历。
下面是一个Mysql的执行流程,和很多OLAP引擎是一样的。
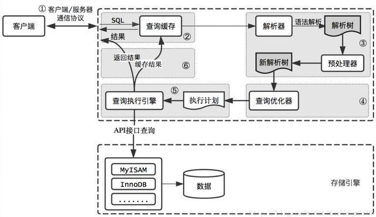
执行模型
Scatter-Gather执行模型:相当于MapReduce中的一趟Map和Reduce,没有多轮的迭代,而且中间计算结果往往存储在内存中,通过网络直接交换。Elasticsearch、Druid、Kylin都是此模型。
MapReduce:Hive是此模型,需要落盘。
MPP:MPP学名是大规模并行计算,其实很难给它一个准确的定义。宽泛一点,Presto、Impala、Doris、Spark SQL、Flink SQL这些都算。
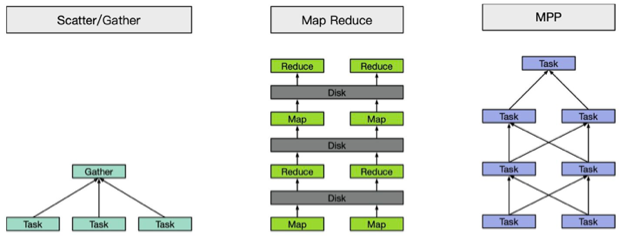
大部分OLAP系统采用的是MPP架构,因为其数据分到不同节点不同机器去存放,这样如果要对数据进行一个shuffle的话,多半就是MPP架构了,下面是Impala的执行流程:
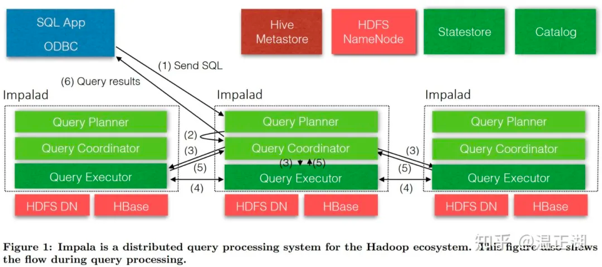
用户通过Impala提供的impala-shell或beeline等客户端/UI工具向Impala节点下发查询SQL;接收该SQL的Impala节点即为Coordinator节点,该节点负责进行SQL解析;
首先产生基于单节点的执行计划;再对执行计划进行分布式处理,比如将Join、聚合(aggregation)等并行化到各Impala Executor节点上。执行计划被切分为多个Plan Fragment(PF),每个PF又由一到多个Operator组成;
接着,下发经过优化后的执行计划的PF到对应的Executor节点,多个执行节点并行处理任务,缩短整个任务所需时间;
执行节点扫描HDFS/Hbase等存储上的数据,并逐层进行处理,比如进行跨节点的数据shuffe,Join等操作;
执行节点完成任务并将输出结果统一发送到Coordinator节点;
Coordinator节点汇总各个执行节点数据,做最后处理,最终返回给用户想要的结果集。
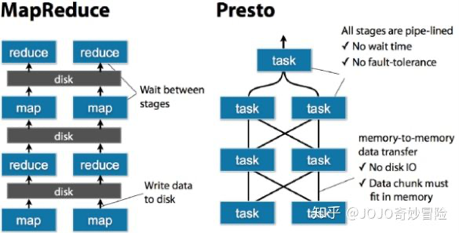
MPP比MR好的原因:
PF之间的数据交互(即中间处理结果)驻留在内存Buffer中不落盘(假设内存够大);
Operator和PF间基于流水线处理,不需要等上一个Operator/PF都完成后才进行下一个处理。上下游之间的关系和数据交互式预先明确的。
MPP可能出现的问题
中间结果不落盘,在正常情况下是利好,但在异常情况下就是利空,这意味着出现节点宕机等场景下,需要重新计算产生中间结果,拖慢任务完成时间;
扩展性没有MR等架构好,或者说随着MPP系统节点增多到一定规模,性能无法线性提升。有个原因是“木桶效应”,系统性能瓶颈取决于性能最差的那个节点。另一个原因是规模越大,出现节点宕机、坏盘等异常情况就会越频繁,故障率提高会导致SQL重试概率提升;
优化
基于规则的优化 RBO
会将原有表达式裁剪掉,遍历一系列规则(Rule),只要满足条件就转换,生成最终的执行计划。一些常见的规则包括分区裁剪(Partition Prune)、列裁剪、谓词下推(Predicate Pushdown)、投影下推(Projection Pushdown)、聚合下推、limit下推、sort下推、常量折叠(Constant Folding)、子查询内联转join等。
谓词下推:通过将数据处理的一些算子下推数据源端(离数据最近处)进行,来提高整体数据处理效率。
下面是openLooKeng下推的示意图,olk希望利用数据源本身的计算能力,在靠近数据源侧进行filter减少数据传输。
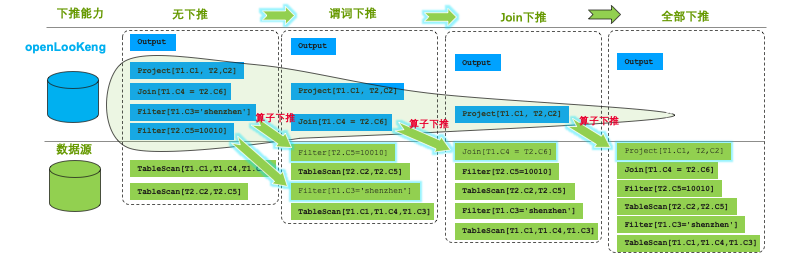
列裁剪:对于用不上的列,没有必要读取它们的数据,无谓的浪费 IO 资源。
比如说表 t 里面有 a b c d 四列。
执行:select a from t where b > 5
这个查询里面明显只有 a b 两列被用到了,所以 c d 的数据是不需要读取的。在查询计划里面,Selection 算子用到 b 列,下面接一个 DataSource 用到了 a b 两列,剩下 c 和 d 都可以裁剪掉,DataSource 读数据时不需要将它们读进来。
列裁剪的算法实现是自顶向下地把算子过一遍。某个结点需要用到的列,等于它自己需要用到的列,加上它的父亲结点需要用到的列。可以发现,由上往下的结点,需要用到的列将越来越多。
列裁剪主要影响的算子是 Projection,DataSource,Aggregation,因为它们跟列直接相关。Projection 里面会裁掉用不上的列,DataSource 里面也会裁剪掉不需要使用的列。
最大最小消除:对 Min/Max 语句进行改写。
实例SQL: select min(id) from t
换一种写法,可以做到类似的效果:select id from t order by id desc limit 1
前一个语句,生成的执行计划,是一个 TableScan 上面接一个 Aggregation,也就是说这是一个全表扫描的操作。后一个语句,生成执行计划是 TableScan + Sort + Limit。
在某些情况,比如 id 是主键或者是存在索引,数据本身有序, Sort 就可以消除,最终变成 TableScan 或者 IndexLookUp 接一个 Limit,这样子就不需要全表扫了,只需要读到第一条数据就得到结果。全表扫操作跟只查一条数据,性能上是天壤之别。
基于规则的优化还有很多,这里只是举例了三种。
基于代价的优化 CBO
基于统计信息 + 代价模型,尝试探索生成等价关系表达式,最终选取代价最小的执行计划。
优化器需要尽量的高效,高效的生成搜索空间、动态规划遍历搜索空间(top down、bottom up、depth-first等),高效的剪枝策略等都可以加速优化过程。
统计信息包括表数据大小,row count。查询列的trait metadata(min、max、cardinality等),sortness、可利用的索引,直方图(Histogram)分布统计等。
CBO的基本步骤:
第一步:采集参原始表基本信息
第二步:定义核心算子的基数推导规则
第三步:核心算子实际代价计算
第四步:选择最优执行路径(代价最小执行路径
下面是Impala关于是否采用基于CBO的性能对比,需要注意的是基于代价的优化不一定是最优的,但对于大部分查询是更优的。
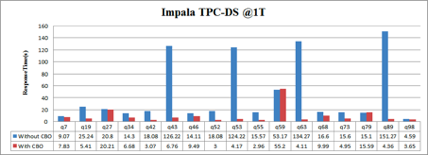
主流OLAP系统对比
Hive
Hive是一个分布式SQL on Hadoop方案,底层依赖MapReduce计算模型执行分布式计算。Hive擅长执行长时间运行的离线批处理,数据量越大,优势越明显。
近2年,随着ClickHouse的逐渐流行,对于一些总数据量不超过百PB级别的互联网数据仓库需求,已经有多家公司改为了ClickHouse的方案。 ClickHouse的优势是单个查询执行速度更快,不依赖hadoop,架构和运维更简单。
Spark
Apache Spark是用于大规模数据处理的统一分析引擎。它提供Java,Scala,Python和R中的高级API,以及支持常规执行图的优化引擎。它还支持一组丰富的更高级别的工具,包括Spark SQL用于SQL和结构化数据的处理,MLlib机器学习,GraphX用于图形处理,以及结构化流的增量计算和流处理。
从流处理的角度来讲,Spark基于微批量处理,把流数据看成是一个个小的批处理数据块分别处理,所以延迟性只能做到秒级。而Flink基于每个事件处理,每当有新的数据输入都会立刻处理,是真正的流式计算,支持毫秒级计算。由于相同的原因,Spark只支持基于时间的窗口操作(处理时间或者事件时间),而Flink支持的窗口操作则非常灵活,不仅支持时间窗口,还支持基于数据本身的窗口,开发者可以自由定义想要的窗口操作。
Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
数据可以被作为 无界 或者 有界 流来处理。
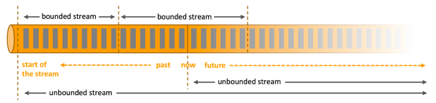
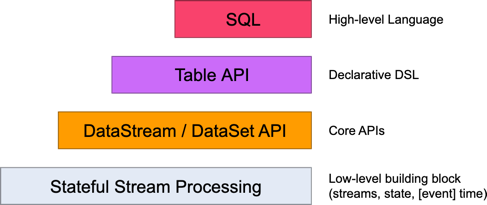
Flink 为流式/批式处理应用程序的开发提供了不同级别的抽象。
Flink API 最底层的抽象为有状态实时流处理。
Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)和 DataSet API(应用于有界数据集场景)两部分。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。
Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。
SQL 查询语句可以在 Table API 中定义的表上执行。
ClickHouse
ClickHouse部署架构简单,易用,不依赖Hadoop体系(HDFS+YARN)。
它比较擅长的地方是对一个大数据量的单表进行聚合查询。Clickhouse用C++实现,底层实现具备向量化执行(Vectorized Execution)、减枝等优化能力,具备强劲的查询性能。目前在互联网企业均有广泛使用,比较适合内部BI报表型应用,可以提供低延迟(ms级别)的响应速度,也就是说单个查询非常快。

ClickHouse也有它的局限性,在OLAP技术选型的时候,应该避免把它作为多表关联查询(JOIN)的引擎,也应该避免把它用在期望支撑高并发数据查询的场景,OLAP分析场景中,一般认为QPS达到1000+就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1000已经非常不容易。
例如Clickhouse,如果如数据量是TB级别,聚合计算稍复杂一点,单集群QPS一般达到100已经很困难了,所以它更适合企业内部BI报表应用,而不适合如数十万的广告主报表或者数百万的淘宝店主相关报表应用。ClickHouse的执行模型决定了它会尽全力来执行一个Query,而不是同时执行很多Query。
Elasticsearch
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎Apache Lucene 基础上的搜索引擎,它不仅包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索
实时分析的分布式搜索引擎
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
用Elasticsearch作为OLAP引擎,有几项优势:(1)擅长高QPS(QPS > 1K)、低延迟、过滤条件多、查询模式简单(如点查、简单聚合)的查询场景。(2)集群自动化管理能力(shard allocation,recovery)能力非常强。集群、索引管理和查看的API非常丰富。
用Elasticsearch作为OLAP引擎,有几项劣势:多维度分组排序、分页。不支持Join。在做aggregation后,由于返回的数据嵌套层次太多,数据量会过于膨胀。
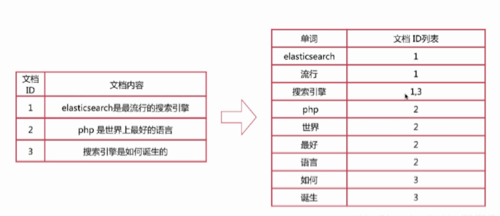
下图是倒排索引的例子:
Presto
Presto、Impala、GreenPlum均基于MPP架构,相比Elasticsearch、Druid、Kylin这样的简单Scatter-Gather模型,在支持的SQL计算上更加通用,更适合ad-hoc查询场景,然而这些通用系统往往比专用系统更难做性能优化,所以不太适合做对查询QPS(参考值QPS > 1000)、延迟要求比较高(参考值search latency < 500ms)的在线服务,更适合做公司内部的查询服务和加速Hive查询的服务。Presto还有一个优秀的特性是使用了ANSI标准SQL,并且支持超过30+的数据源Connector。
Impala
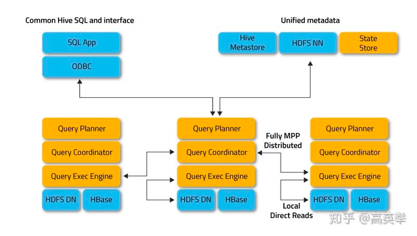
Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互SQL大数据查询工具,是CDH 平台首选的 PB 级大数据实时查询分析引擎。它拥有和Hadoop一样的可扩展性、它提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由Java和C++实现的,Java提供的查询交互的接口和实现,C++实现了查询引擎部分,除此之外,Impala还能够共享Hive Metastore,甚至可以直接使用Hive的JDBC jar和beeline等直接对Impala进行查询、支持丰富的数据存储格式。
Impala 没有使用 Hive+MapReduce 批处理,而是通过使用分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
Doris
Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。
Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
Doris是百度主导的,根据Google Mesa论文和Impala项目改写的一个大数据分析引擎,在百度、美团、京东的广告分析等业务有广泛的应用。
Doris的开发者后面还自己出来做了DorisDB,据其官网的测试,在单表上已经击败了ClickHouse,并且还提供了不错的多表Join能力。
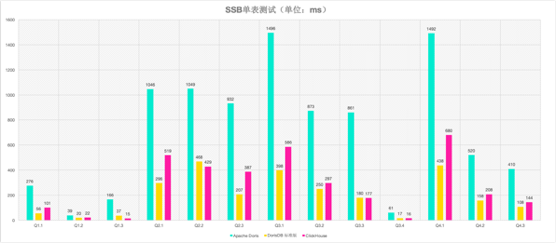
Druid
Druid 是一种能对历史和实时数据提供亚秒级别的查询的数据存储。Druid 支持低延时的数据摄取,灵活的数据探索分析,高性能的数据聚合,简便的水平扩展。Druid支持更大的数据规模,具备一定的预聚合能力,通过倒排索引和位图索引进一步优化查询性能,在广告分析场景、监控报警等时序类应用均有广泛使用。
与其他的时序数据库类似,Druid在查询条件命中大量数据情况下可能会有性能问题,而且排序、聚合等能力普遍不太好,灵活性和扩展性不够,比如缺乏Join、子查询等。
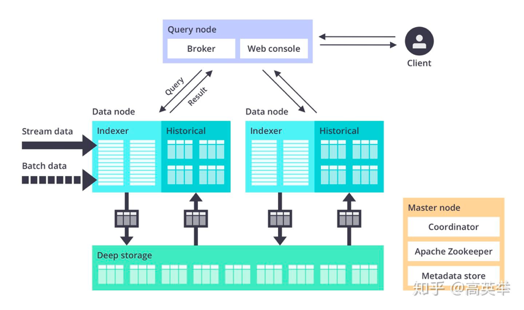
Kylin
Kylin自身就是一个MOLAP系统,多维立方体(MOLAP Cube)的设计使得用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体进行数据的预聚合。
适合Kylin的场景包括:
用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
每天有数G甚至数十G的数据增量导入
有10个以内较为固定的分析维度
简单来说,Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。
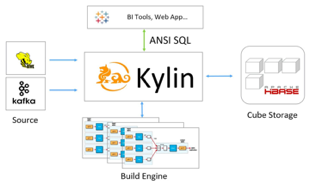
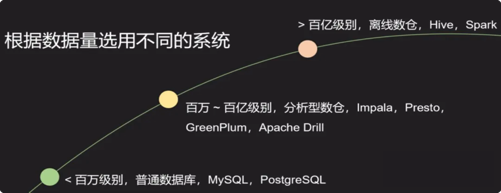
如何选择合适的OLAP系统?
OLTP or OLAP
离线 or 实时
查询模式是否固定
是否需要高并发查询
是否需要Join
是否已有Hadoop生态
是否愿意花钱
数据量大小