浅析Presto / openLooKeng / Trino的JDBC连接器实现
近期在社区对ClickHouse connector的开发进行了一次分享,在此简要梳理
Connector架构解析
openLooKeng实现跨数据源跨地域大数据分析是基于Connector实现的,不同的Connector提供了查询不同数据源的能力。
不同数据源的连接器只需要实现SPI对应的接口就可以被openLooKeng调用,如下图所示,不同连接器的地位是等同的。
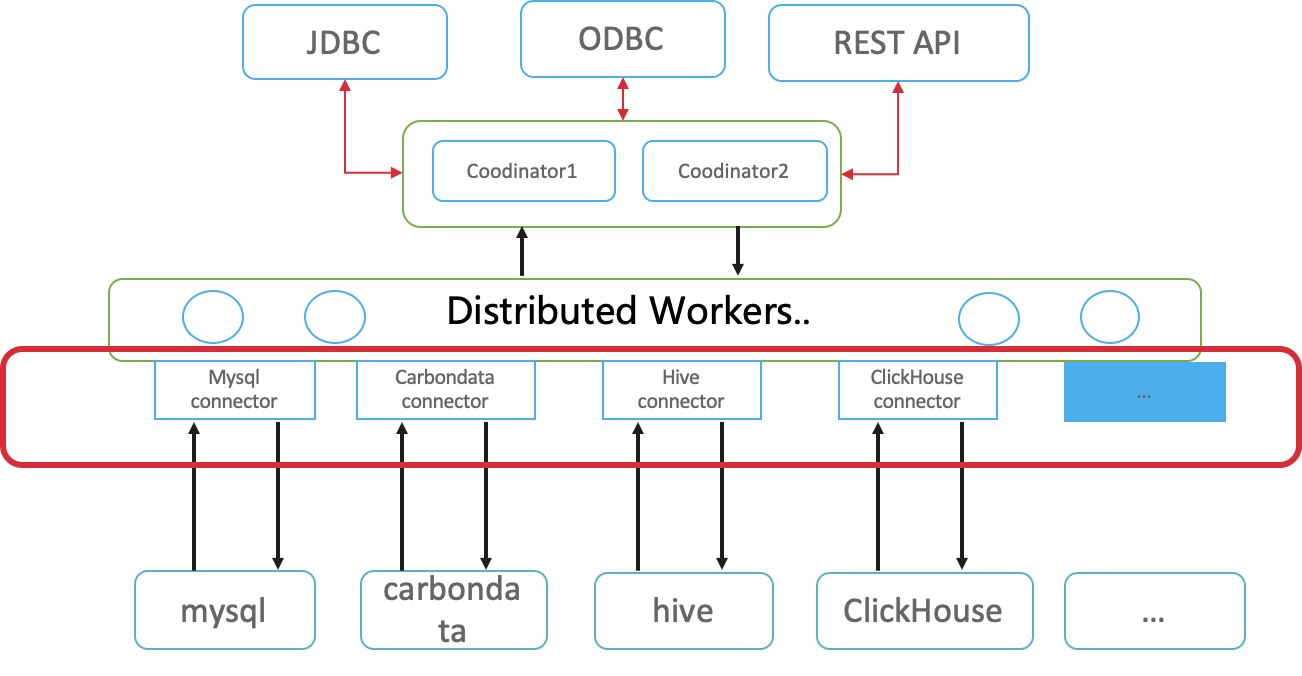
openLooKeng的整体架构分为coordinator和worker,coordinator负责任务的分割和管理worker节点,worker负责实际的任务执行,worker会调用connector去拉取不同数据源的数据。实际上,不止worker会调用connector,coordinator也会调用connector对sql进行优化,比如基于规则的算子下推,所以connector也被称为插件。
SPI机制
SPI是JDK内置的服务提供/发现机制,它通过在ClassPath路径下的META-INF/services/目录中定义的文件,自动加载文件里所定义的类。
SPI特点:
- SPI文件名为实现Service接口的全限定名
- SPI文件内容为实现该接口的具体文件
- 使用ServiceLoader.load(Class class)动态加载Service接口的实现类
- 如果SPI实现的类在外部Jar包中,则需要将该jar包放在当前程序的classpath下
- Service的实现类必须有无参构造方法
openLookeng中有一个presto-spi模块,该模块即定义了openLooKeng对外暴露的SPI接口,实现对应的接口即可实现连接器、类型、函数、系统访问控制等的功能。
特别的,openLooKeng的插件即实现了Plugin SPI的模块:
1 | io.prestosql.spi.Plugin |
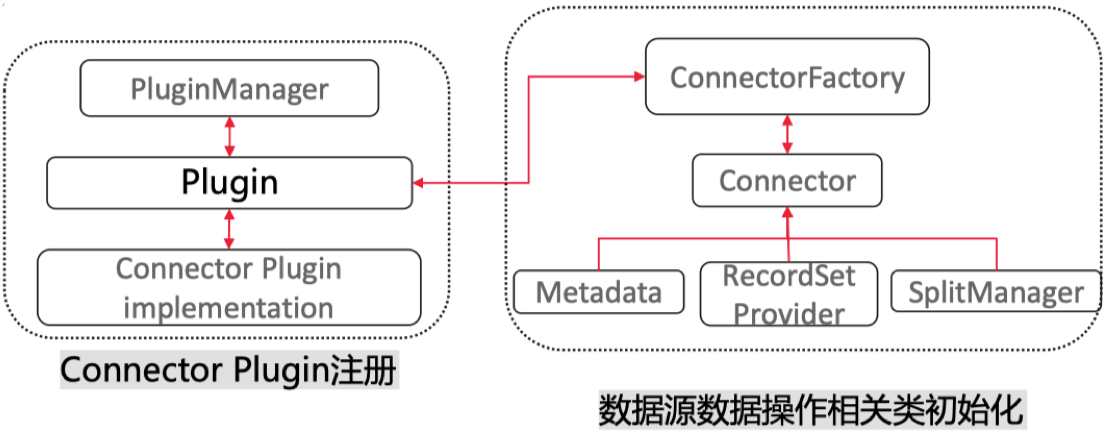
通过在META-INF/services/io.prestosql.spi.Plugin文件中列出实现io.prestosql.spi.Plugin接口的具体类,即可使该实现通过java内置的ServiceLoader提供给openLooKeng。对于包含在openLooKeng源码中的插件,只要在pom.xml中包含<packaging>presto-plugin</packaging>就会自动创建spi文件。
Connector基本知识
openLooKeng通过connector来对接数据源,为此connector需要实现SPI接口的API,实现对数据源元数据信息的获取,在openLooKeng中数据源相关的元数据信息有catalog、schema、table、column等。Connector还需要完成对数据源的读写。数据读,在Connector层通过取回数据表格的形式 (类似于JDBC的ResultSet)。数据写,在Connector层执行具体的操作,例如下发 DML SQL语句,更改文件内容等操作。
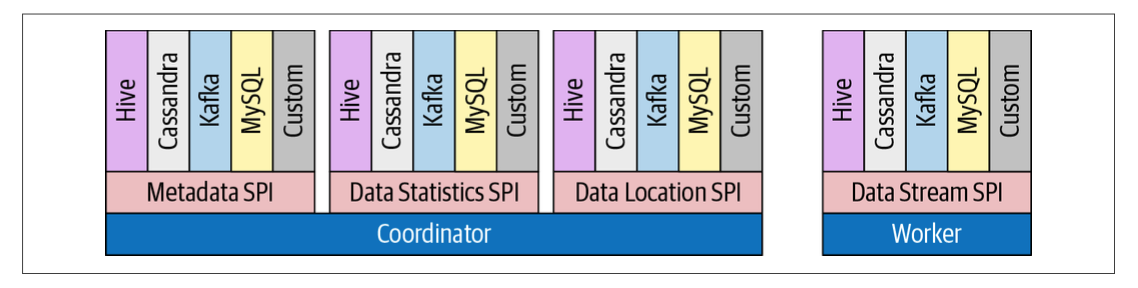
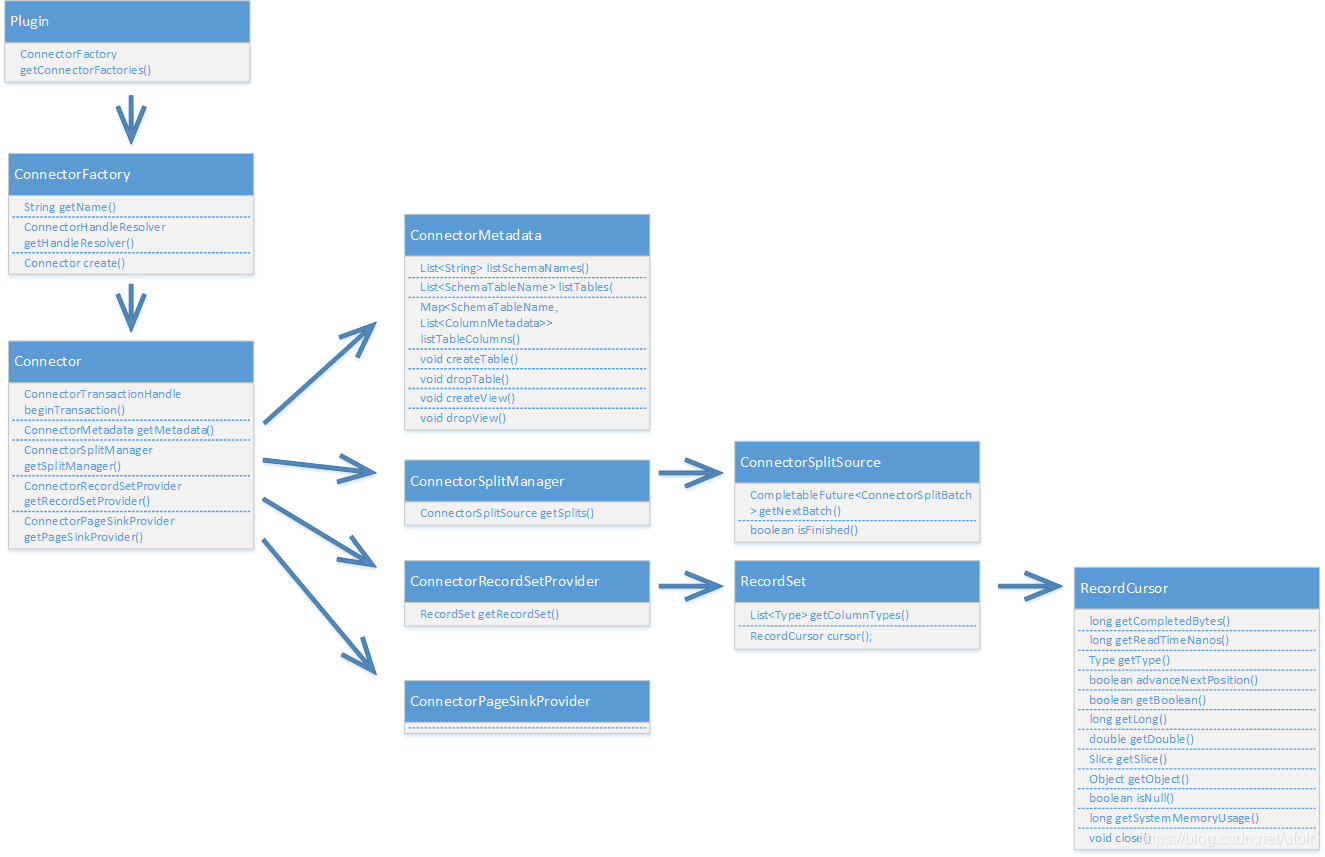
具体来讲,Connector实例由connectorFactory实例创建,openLooKeng调用插件上的getConnectorFactory()时会创建该ConnectorFactory实例。通过Connector获取Metadata、SplitManager、 RecordSetProvider的接口类。
ConnectorMetadata 元数据接口,允许openLooKeng查看模式列表、表列表、列列表等元数据信息。如果要接入的数据源是非关系型数据库,则需要将数据源映射到openLooKeng的 模式、表、列概念。
ConnectorSplitManager分片管理器,将表的数据分区为多块,将块由openLooKeng分发到不同的工作节点处理。对于没有已分区数据的数据源,比较好的策略是针对整张表返回单个分片。
openLooKeng分布式执行任务是将任务划分为Stage在不同的worker上执行,数据源中定义的Split即为Source Stage中调度的Split。
如果一个Split分片涵盖的数据量过大,数据不均匀,则会拖慢整个SQL;若过小,则会造成大量的CPU资源都耗费在调度Split的操作上。
ConnectorHandleResolver
ConnectorRecordSetProvider 记录集提供器,给定一个分片和一个列表的情况下,记录集提供器将数据提供给OpenLooKeng执行引擎。记录集提供器创建一个RecordSet,RecordSet又相应的创建一个RecordCursor,OpenLooKeng使用该RecordCursor来读取每一行的值。
对于每个Split都会创建一个RecordCursor实例。
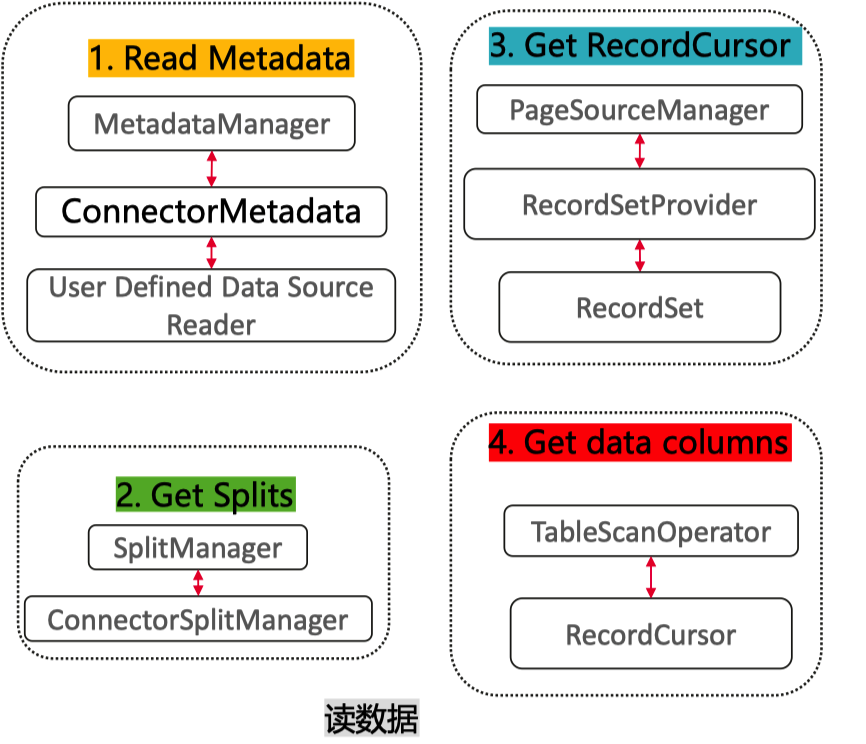
通过Connector读数据流程:
- 取元数据
- 获取Split信息
- 为每一个Split构建RecordCursor
- 通过RecordCursor取数据
通过Connector写数据:
- 修改元数据、数据信息
整体执行逻辑如下图所示:
基于JDBC实现
openLooKeng connector主要有两种实现方式,自己实现一个server引擎或者基于JDBC实现。
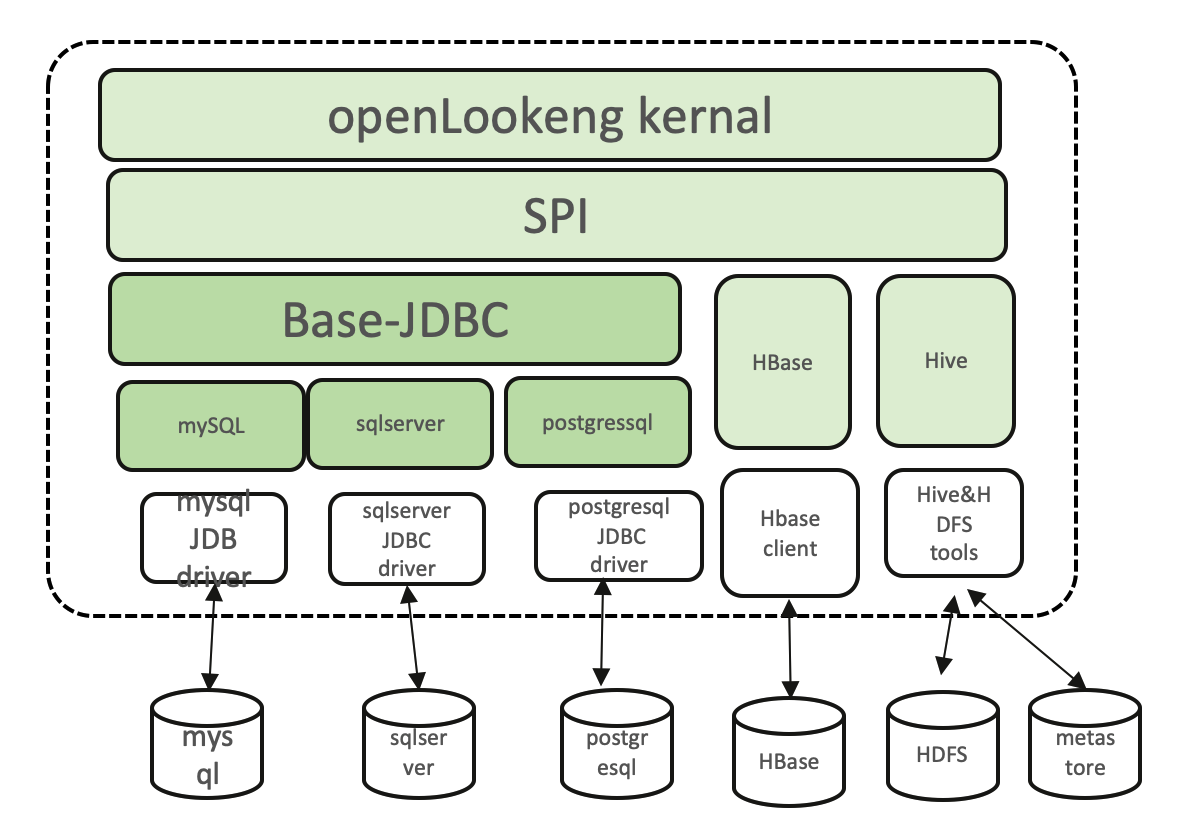
Hive和HBase是自己实现了server引擎,而对于大部分支持JDBC规范的数据源,可以在Base-JDBC的基础上进行开发。Base-JDBC已经实现了MetaData,Split,RecordCursor等关键接口,实现ClickHouse可以继承Base-JDBC对其进行修改。
需要注意的是,基于JDBC的方式,一定会存在性能损耗,因为是通过JDBC去进行查询,无法像Hive Connector那样进行查询优化。不同的数据源对于JDBC的支持和实现细节有所差别,需要根据数据源进行适配开发。
适配开发最关键的类是JdbcClient类,用于和数据源进行交互,Client包含对数据库的DDL操作方法和类型转换。
io.prestosql.plugin.jdbc.JdbcClient
提供元数据的增删改查等
提供数据类型转换接口
元数据的增删改查
getSchemaNames、listSchemas、getTableNames、getTables、getColumns等
数据类型转换接口
元数据取回时,需要进行数据源类型转化为openLooKeng数据类型-已经有标准实现:toPrestoType
数据写入,数据需要从openLookeng内核类型转为数据源数据类型openLooKeng数据类型:toWriteMapping
⚠️注意,由于openLooKeng内核类型和数据源不一定一致,所以需要在Client对进行映射和处理,这里对于数据源的支持是取openLooKeng和数据源都支持类型的交集,所以会存在泛用性降低的问题。
如果只需要实现基本的查询,那么重写以下几个类就可以了:
1 | io.prestosql.plugin.jdbc.JdbcPlugin |
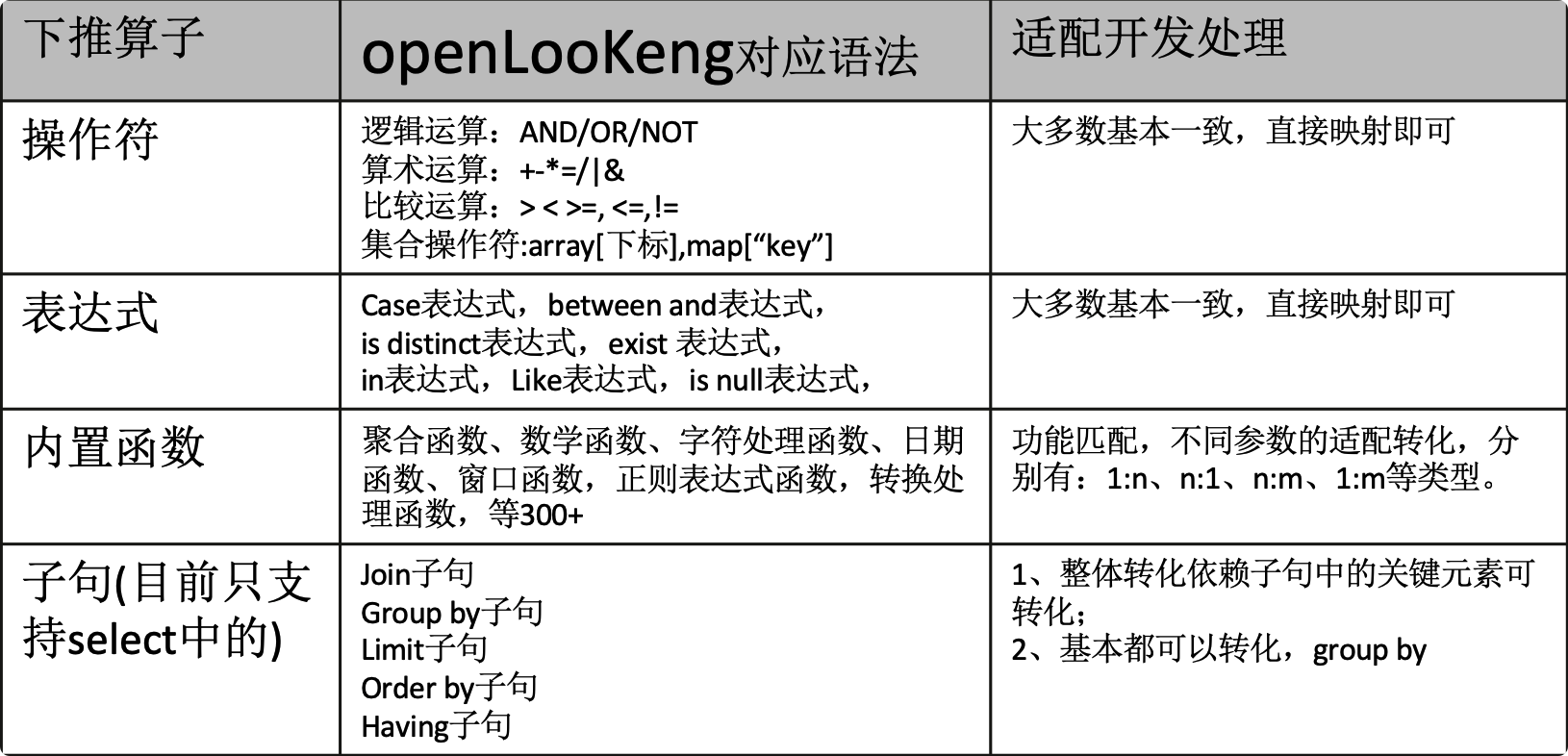
算子下推
对于不少数据源,比如ClickHouse,本身就具备高性能的查询能力,并且数据源一般会对自身的数据和函数进行优化,openLooKeng可以借助这些数据源的能力减少自己的计算部分。下推,也就是将算子尽可能接近数据源,算子下推后,计算和数据更贴近,整体性能更高。
如果不进行下推,openLooKeng会拉去全表数据,再由openLooKeng kernal来进行filter,这样会传输的很多不必要的额外数据。
以下是openLooKeng执行一跳SQL的整体流程:
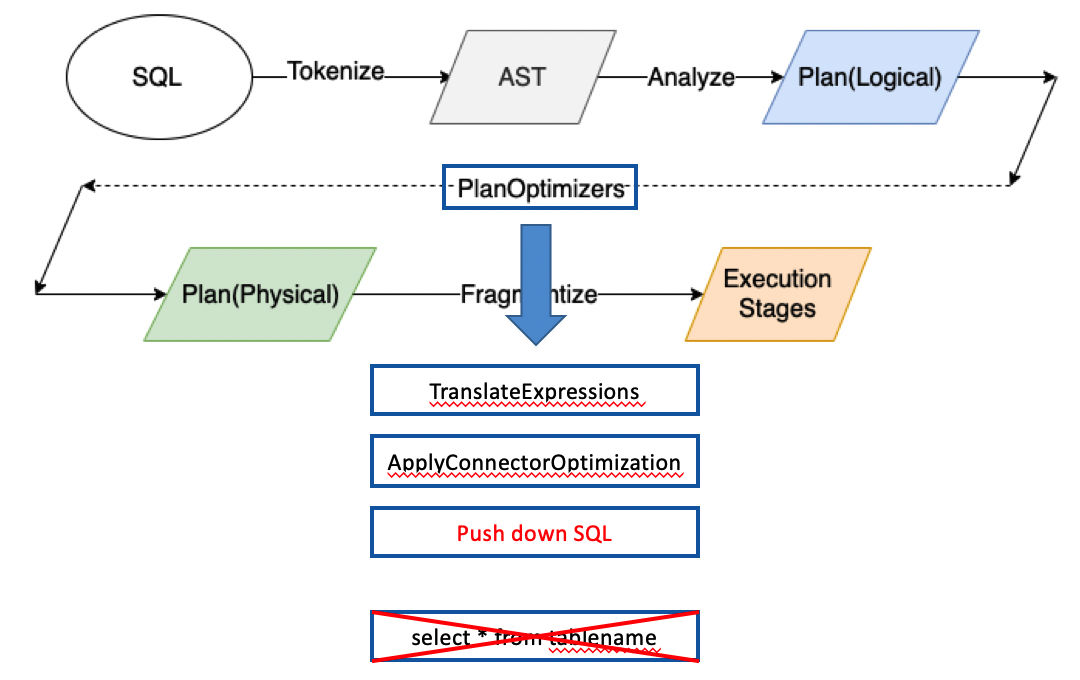
openLooKeng会在optimizer的时候判断是否可以进行算子下推,将openLooKeng语法等价替换为数据源语法下推给数据源执行,提高数据处理效率。
算子需要实现SqlQueryPushDown相关接口:
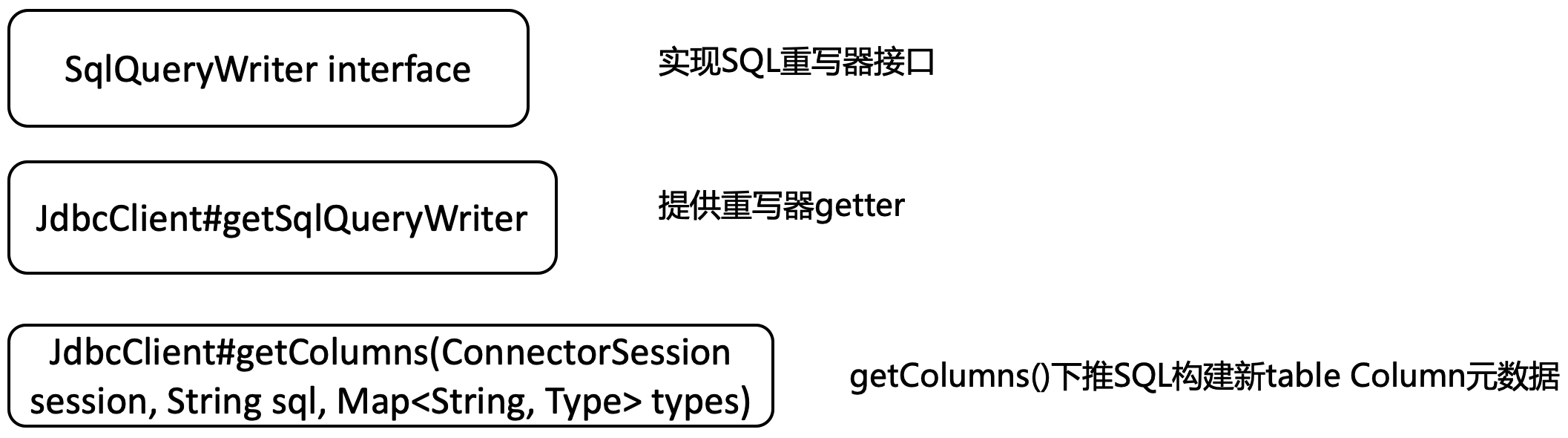
外部数据源的函数应用
算子下推大大提高了查询执行的效率,但是仍然存在一定的限制。单纯的算子下推只能将openLooKeng支持的函数映射为数据源的函数,但是不同数据源的函数实在太多了,并且各个数据库function的开发框架,开发语言不同,很难在不同数据库间 共享实现代码。
总有一些场景可能会用到这些数据源独有的函数,而openLooKeng本身是无法识别的,会在分析器报语法错误。
openLooKeng在1.3提供了一个类似于白名单的机制,对数据源的外部函数进行注册,由于不同数据源可能出现重名函数,需要对函数命名空间进行管理。
对于函数的管理和Table一样也是三级结构,例如:ckdb.function.toDateTime
第二级目录的可以让openLooKeng对于同一个数据源的函数也进行区分管理,虽然我目前还没有发现这个的应用场景(函数更长了orz)。
外部函数的注册下推主要设计以下几个类和方法:
1 | io.prestosql.sql.builder.functioncall.JdbcExternalFunctionHub |
注意, 数据源的函数一般重载了不同的参数,而openLookeng要求注册的外部函数有严格的入参和出参类型,所以单个外部函数可能需要注册多个函数。
最后,实现了对数据源的基本查询,算子下推,外部函数注册,ClickHouse connector的代码结构如下:

ClickHouse connector注意事项
检查算子是否下推成功
- explain
1 | Output |
- 查询query log
1 | SELECT |
语法不同
ClickHouse允许在where中使用select的别名,这和标准SQL的查询流程不同,而openLooKeng是标准的ANSI SQL03语法,如果希望通过openLooKeng查询ClickHouse数据源,需要注意语法问题。
catalog问题
这个问题真的搞了我好久~
openLooKeng对于表的定义是 Catalog.Schema.Table 三层结构,但是对于ClickHouse而言,Catalog和Schema是等同概念,所以需要注意将Catalog置为null。
ClickHouse connector目前的限制
- 类型支持暂不全面
- 支持常见类型
- 不支持Int128,Int256,UInt256,IPV4…
- 关于array的常用函数暂时不支持,因为array就不支持
- 不支持create,delete和alter操作
- 单表查询性能具有一定的损耗
本文参考和引用了下面的资料:
在openLookeng中构建一个Connector-黎一泽 谢谢大佬在我开发过程中给予了很多帮助~
OpenLooKeng / Presto Connector原理-ufolr 很好的一篇文,谢谢社区的酷行者大佬~
《Presto实战》[美] 马特·富勒(Matt Fuller)[美] 曼弗雷德·莫泽(Manfred Moser)[美] 马丁·特拉韦尔索(Martin Traverso)