数据库遇上机器学习
参数优化
⼀种⽅式是将数据库内核与使⽤ ML 算法的模块分⽴,将数据库暴露出来的配置参数与性能数据输⼊到 ML 模块中,常⻅应⽤有⾃动调节参数、异常检测等。以⾃动调参为例,这种分⽴式的应⽤⽅式给出的参 数建议可以对标资深 DBA 根据业务运维经验和对数据库内核的理解给出的参数配置。
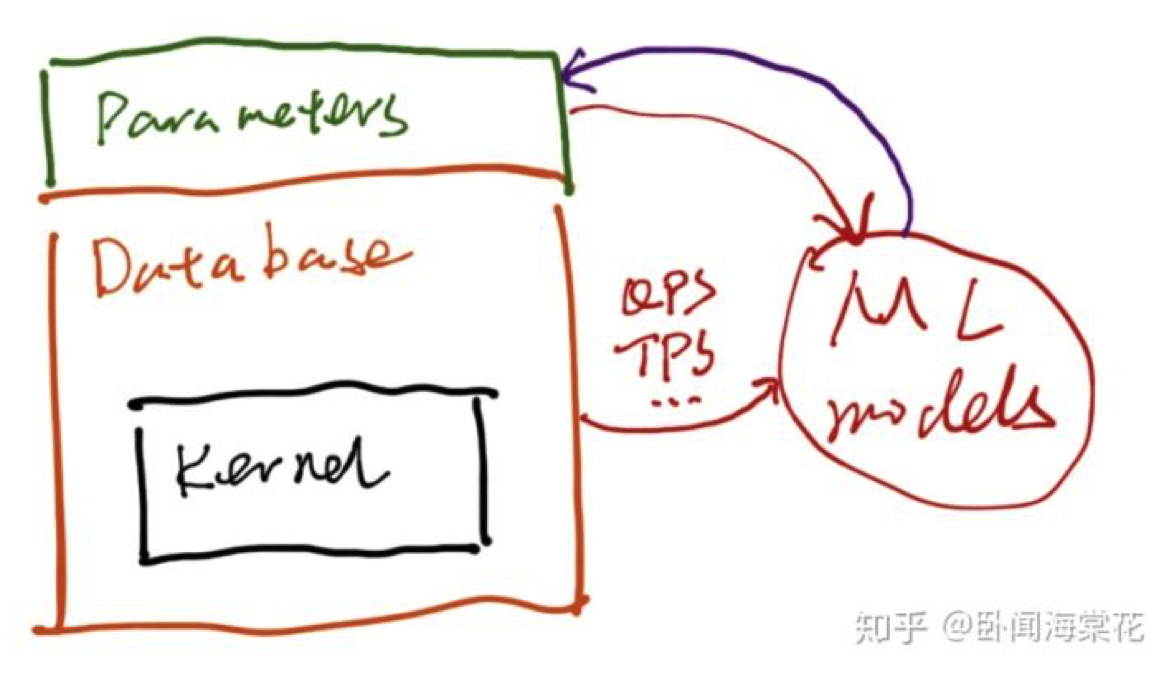
这种 ML 与数据库内核松耦合的⽅式便于将两者分别开发、迭代和维护,ML 可以作为增值服务单独上线 与售卖,且对数据库内核的稳定性影响较⼩。对于开发者来说,算法⼯程师相对⽽⾔可以了解较少的数 据库内核运转机制,跨界感较弱,上⼿快,但仍需要理解数据库参数的物理意义,从⽽能够出设计出合 理的训练数据集和训练任务。不过,算法很难和资深 DBA 在处理异常情况、给出解释并沉淀出运维⽅案 等⽅⾯进⾏有效竞争。
from here
相关⼯作⽐如:
-
TiKV底层使⽤了 RocksDB 作为存储引擎,然⽽ RocksDB 配置选项很多,很多情况下只能通过反复 测试或者依靠经验来调优,作者结合AutoML对数据库参数进⾏⾃动调优。
-
华科与腾讯合作的sigmod2019论⽂,基于AI技术的数据库性能调优结果⾸次全⾯超越数据库 专家经验判断的传统⽅法。
索引优化
⽤ml去优化索引——17年底Google的⼯作,现在仍然是数据库⽅⾯的⼀个研究热点。
相当有名⽓的⼯作 The Case for Learned Index Structures
- 作者提到通过建⽴层次模型的⽅式解决:根节点的分类器将记录划分成n份,给下⼀层分类器 进⾏分类,这样节点的预测器学习的数据少⽽简单,总体的时间成本也能够保证。
ALEX: An Updatable Adaptive Learned Index
- sigmod2020的⼯作,和上⾯的⼯作是⼀个组做的,解决了学习型索引插⼊删除难的问题。
- ALEX的核⼼解决思路是:
- 让每个模型独⽴管理⾃⼰的数据。即插⼊到⾃⼰这部分的数据变化不影响其后的模型。
- 更改数据存储结构。使得插⼊、删除更为迅速。
简⽽⾔之,这是⽐较难的⼀个坑,慎跳(虽然俺组也跳不了orz)。
查询优化
- Towards a Learning Optimizer for Shared Clouds
- VLDB的论⽂ 研究了在多租户云数据库环境下,使⽤历史查询的执⾏统计数据进⾏训练学习,来预估未来查 询的中间结果基数⼤⼩,从⽽指导⽣成更优的查询计划。
- Towards a Hands-Free Query Optimizer through DeepLearning
- Neo: A Learned Query Optimizer
- VLDB的论⽂
- Neo会从现有的优化程序中引导其查询优化模型,并继续从传⼊的查询中学习,以成功为基 础,并从失败中学习。 此外,Neo⾃然会适应基础数据模式,并且对估计错误具有鲁棒性。
查询优化同样是很困难的⼀件事,从sql到执⾏树,如何选择执⾏⽅案,与⼀般的分类或回归任务有很⼤ 不同,并且如果采⽤有监督的机器学习,⼤规模的训练数据也难以获取。
缓存优化
更新数据库,再删缓存
在知⽹的毕业论⽂⾥找到了⼏篇这⽅⾯的⼯作:
-
- 华科的硕⼠毕业论⽂,华科在机器学习结合数据库⽅⾯的⼯作很多
- 在数据库第⼀次访问将要被缓存的时候,⽤⼀个分类器来预测其可能在后续被访问。
- 问题在于针对不同场景,是否再次访问是完全不可知的,也就是不通⽤。
基于机器学习的RocksDB存储引擎配置优化
同样是华科的硕⼠毕业论⽂ 针对RocksDB读性能较低的问题,本⽂以提升⾯向读的⼯作负载性能,拟合热点数据分布为⽬的, 设计并实现了利⽤增量学习进⾏预测分析的热点数据主动缓存模块。该模块针对访问模式对数 据建模,预测潜在热点数据并主动进⾏数据重放操作,这样热点数据永远在⽇志结构合并树的较 低层级中,减少了在存储介质中的I/O访问次数。 主动缓存毫⽆疑问会需要占据更多内存空间。
数据库⽅案
在数据库系统整体⽽⾔与机器去学习结合的⽅式较少,⼀般都是将某个组件或者优化的部分与机器学习 进⾏结合,⽐如上⾯提到的索引优化,缓存优化等等。
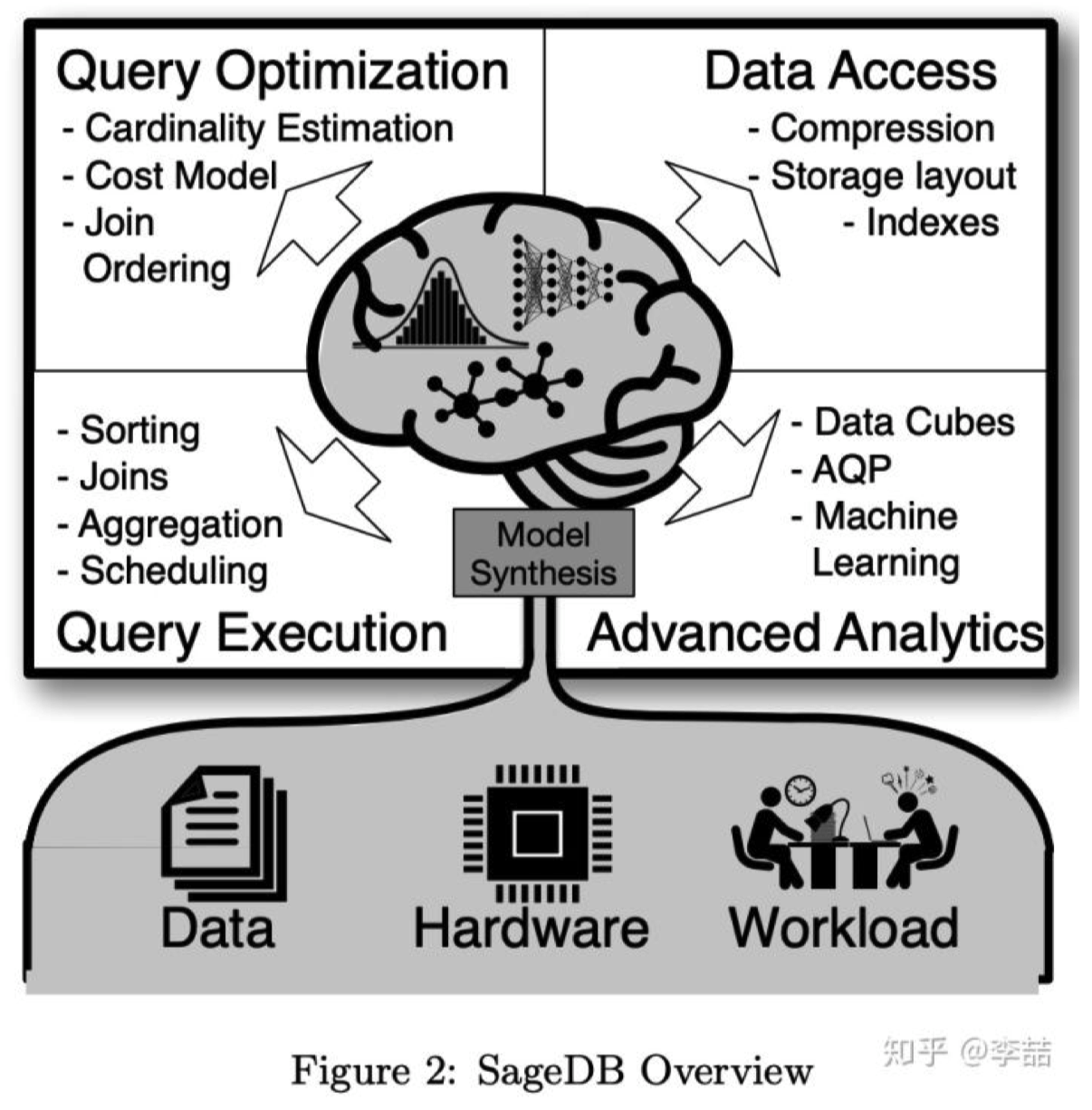
(18年底)Google提出的新型数据库系统SageDB,他们在论⽂中提出了⼀个观点:学习模型可以渗透 到数据库系统的各个⽅⾯。基于机器学习的组件可以完全取代数据库系统的核⼼组件,例如索引结构、 排序算法,甚⾄是查询执⾏器。该系统是他们17年⼯作的进⼀步实现。
SageDB⽜逼的地⽅就在于完整的提出了⼀个⾰新性的数据库系统蓝图(贤者数据库。。。),把所有能 ⽤机器学习替代、结合的地⽅都替代、结合了。其中最重要的⼏点就包括之前的学习型索引,以及新提 出的学习型排序和学习型数据排布(即切分)。
总结
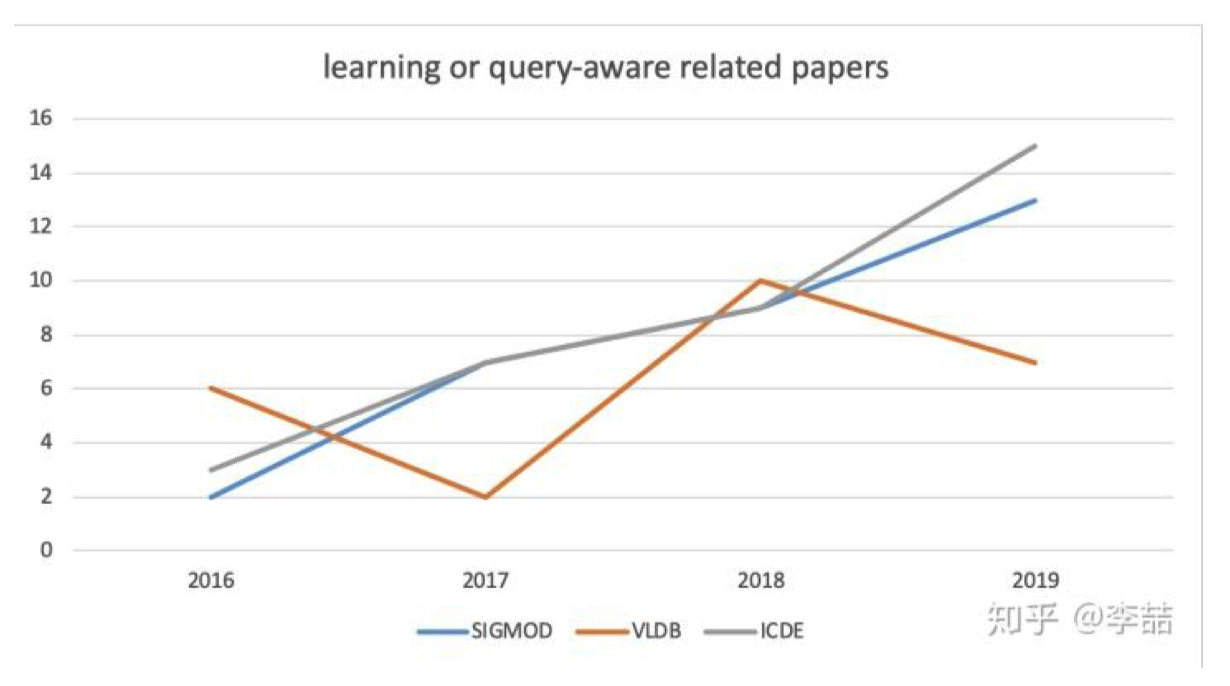
将机器学习与数据库进⾏结合确实是未来的⽅向,从⽬前database三⼤顶会的趋势就可⻅⼀般。 并且⽬前流⾏的数据库⽐如TiDB中也⽤到很多机器学习优化的⼿段,在19年华科与腾讯合作的sigmod 论⽂甚⾄将参数优化的效果超过了数据库专家调优,但是在真正使⽤场景下,这些机器学习优化的组件 能否真正起到作⽤,还是不得⽽知,需要⽤时间和实践来检验。