一句话描述
解决了什么问题?
过去基于统计的方法特征是假阳率比较高,并且很依赖专家的知识(其实这个方法也很依赖),不同主机间有着潜在的图特征。
什么方法?
将网络流量转换为一阶和二阶图。 一阶图从单个主机的角度学习潜在特征,二阶图从全局角度学习潜在特征。 此功能提取过程不需要人工参与或专业知识。
对我的启发。
采用Graph embedding + 异常检测的方法来针对异常流量检测。
方法
一阶图
一阶图是一个二部图。图的左侧节点表示IP,右侧节点表示端口。图中的边表示主机 的端口使用情况,该端口发送的数据包个数表示边的权重。
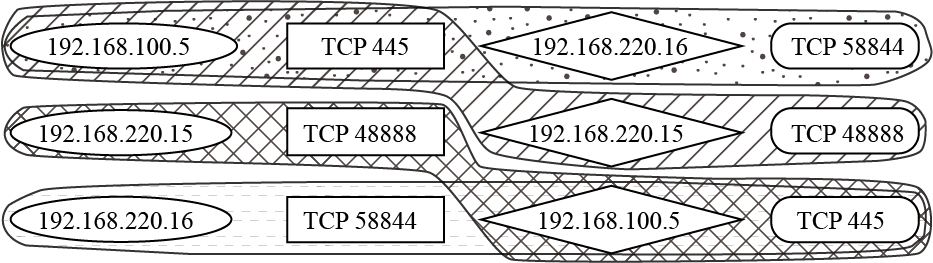
作者认为,如果两个主机具有相似的端口使用率分布,则它们在向量空间中的距离应接近。
问题在于,加密流量很多时候都是使用HTTPS,443端口啊。
虽然图很简单,但是作者仍然采用了embedding,下面是他们定义的条件概率,其中 v 表示结点, u 表示低维向量表示:
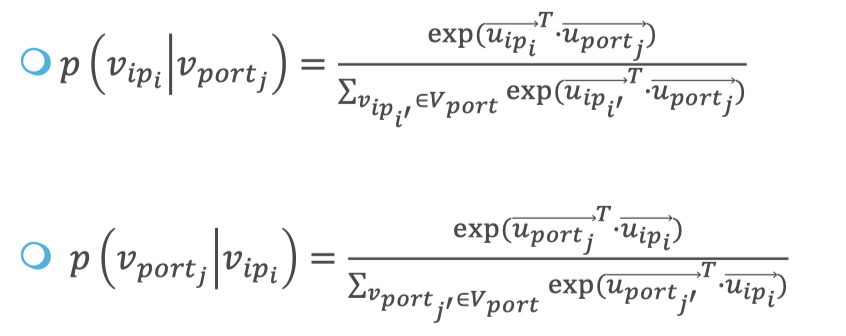
可以计算出对应的条件概率分布 𝑝 ( ∙ | 𝑣 𝑝𝑜𝑟𝑡𝑗 ) 和 𝑝 ( ∙ | 𝑣 𝑖𝑝𝑖 ) 从一阶图中可以计算出如下两个经验概率:
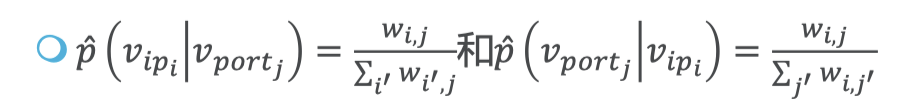
然后可以计算出对应的经验概率分布𝑝 ( ∙ | 𝑣 𝑝𝑜𝑟𝑡𝑗 ) 和𝑝 ( ∙ | 𝑣𝑖 𝑝𝑖) 。
为了了解IP地址和端口的潜在特征,最小化了条件分布和经验分布之间的距离。因此,得到以下目标函数:

- 目标函数是最小化条件概率分布和经验概率分布之间的距离,让条件概率分布尽可能接近经验概率
- KL散度(Kullback-Leibler 散席,相对熵)可以表示概率分布之间的距离
二阶图
二阶图是一个超图(hyper-graph)。图中有四类节点:源IP、源端口、目的IP、目的端口。源IP和目的IP的网络通信形成超边(hyper-edge),发送的数据包个数表示超边的权重。
在超图中,一个边可以连接多个点,称之为超边。
在二阶图的例子中,四种不同的填充方式表示四条超边,填充区域覆盖的点是超边中的点。
还是很疑惑,没有使用时间信息,没有使用数据包大小,仅仅用ip和端口还有包数,就能识别?而且上下文还是目的ip和端口。
二阶图的边定义如下
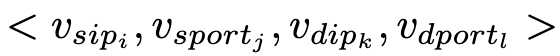
定义 C 表示一个节点的上下文,例如对于一个超边( 𝑣 𝑗, 𝑣 𝑘, 𝑣 𝑙), 𝑣𝑖 的上下文是 ( 𝑣 𝑗, 𝑣 𝑘, 𝑣 𝑙) 。
定义条件概率:

从二阶图中可以计算经验概率:
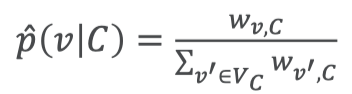
最终目标函数:
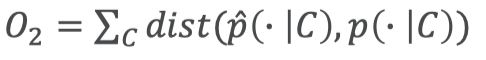
使用随机梯度下降算法求解目标函数最小值,就可以得到源IP、源端口、目的IP、目 的端口的二阶低维表示 𝑢 𝑠 𝑖𝑝 𝑖 , 𝑢 𝑠 𝑝𝑜𝑟𝑡 𝑗 , 𝑢 𝑑𝑖𝑝 𝑘 和 𝑢 𝑑𝑝𝑜𝑟𝑡 𝑙 。
这部分应该去看看图嵌入的实现过程,以及如何得到向量表示的。
优化
主要是为了加速计算速度,采用了下列两种方式。
Fast Sigmoid Algorithm
用sigmoid table代替严格的sigmoid计算,也就是卜老师所说的,足够好即可,不需要严格最好。
Alias Method for Sampling
一种采样的方法,具体没有仔细看,不是本文重点,这里作者提到采用了论文 Reducing the sampling complexity of topic models 的方法,有用到的时候可以看看。
异常流量检测框架
网络探测 + 嵌入 + 训练 + 检测 + 数据库存储。(并不复杂)
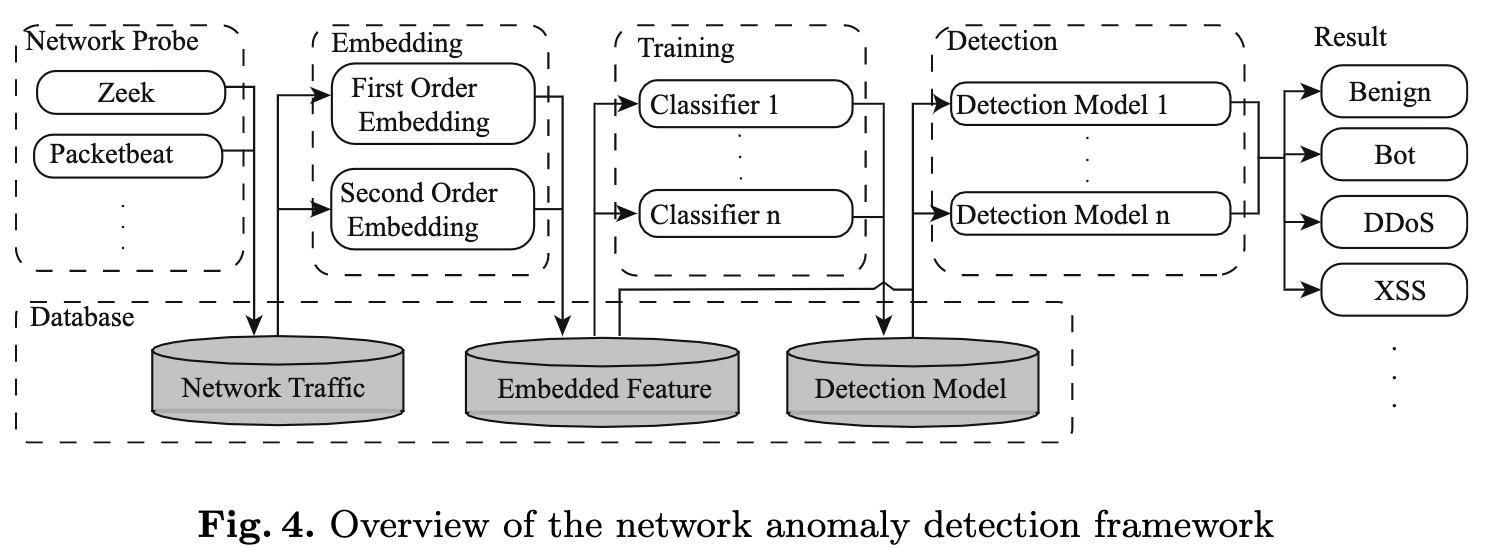
网络探测就是流量捕获,这里作者使用开源工具Zeek , Packetbeat , 和 Joy 来生成流量,然后解析得到流量日志如下:

原文中的话:对于初始训练,我们随机初始化每个节点的嵌入向量。 对于每个后续训练,我们将上次训练的嵌入向量用作该训练的初始值,然后将新数据用于迭代训练。 在每次培训结束时,我们将结果存储在数据库中以备后用。(把向量存到数据库会带来很大的存储开销,在实际运作的系统中难以实现)
评估
虽然本文采用的方法并非很复杂,也没有用到什么独特的特征,但是本文评估的时候采用的是两个公开数据集CIDDS-001和CICIDS 2017。
第一个实验是IP地址的聚类。 我们在CIDDS-001数据集上验证了一阶和二阶低维向量表示是否可以学习IP地址的潜在特征。
第二个实验是网络异常检测。 我们在CICIDS 2017数据集上评估了我们方法的精度,召回率和F1值。
第三个实验是未知威胁发现。 我们使用部分攻击类别来训练我们的模型,然后评估是否可以检测到新的攻击类型。
IP聚类实验
就是把用向量做聚类,base方法是IP2Vec,最后聚出有几簇,然后用明文ip聚类,验证向量是否有效的。
异常流量检测
CICIDS 2017数据集总共包含2,830,743个网络流。 攻击类型包括DDoS,DoS,Brute Force,XSS,SQL注入,渗透,端口扫描和僵尸网络。 我们删除了少于100个流量的攻击类别。 对于其余类别,我们将每个类别的数据的60%用作训练集,将40%用作测试集。
之前的工作 Toward generating a new intrusion detection dataset and intrusion traffic characterization 评估了每种功能对检测攻击的重要性,并选择了八个最重要的功能:流持续时间,总转发数据包,总反向数据包,总转发数据包长度,总反向数据包长度,每秒流字节数, 每秒的流量数据包,下/上比率。
因此,在本实验中,我们使用一阶矢量表示,二阶矢量表示以及这八种特征训练机器学习算法。
啊这…
在此实验中,进行了3次评估。 第一次,仅使用原始特征。 第二次,仅使用嵌入特征。 第三次,我们同时使用了原始特征和嵌入特征。 我们使用随机森林算法来训练和评估来自三个指标的结果:Precision,Recall和F1值。
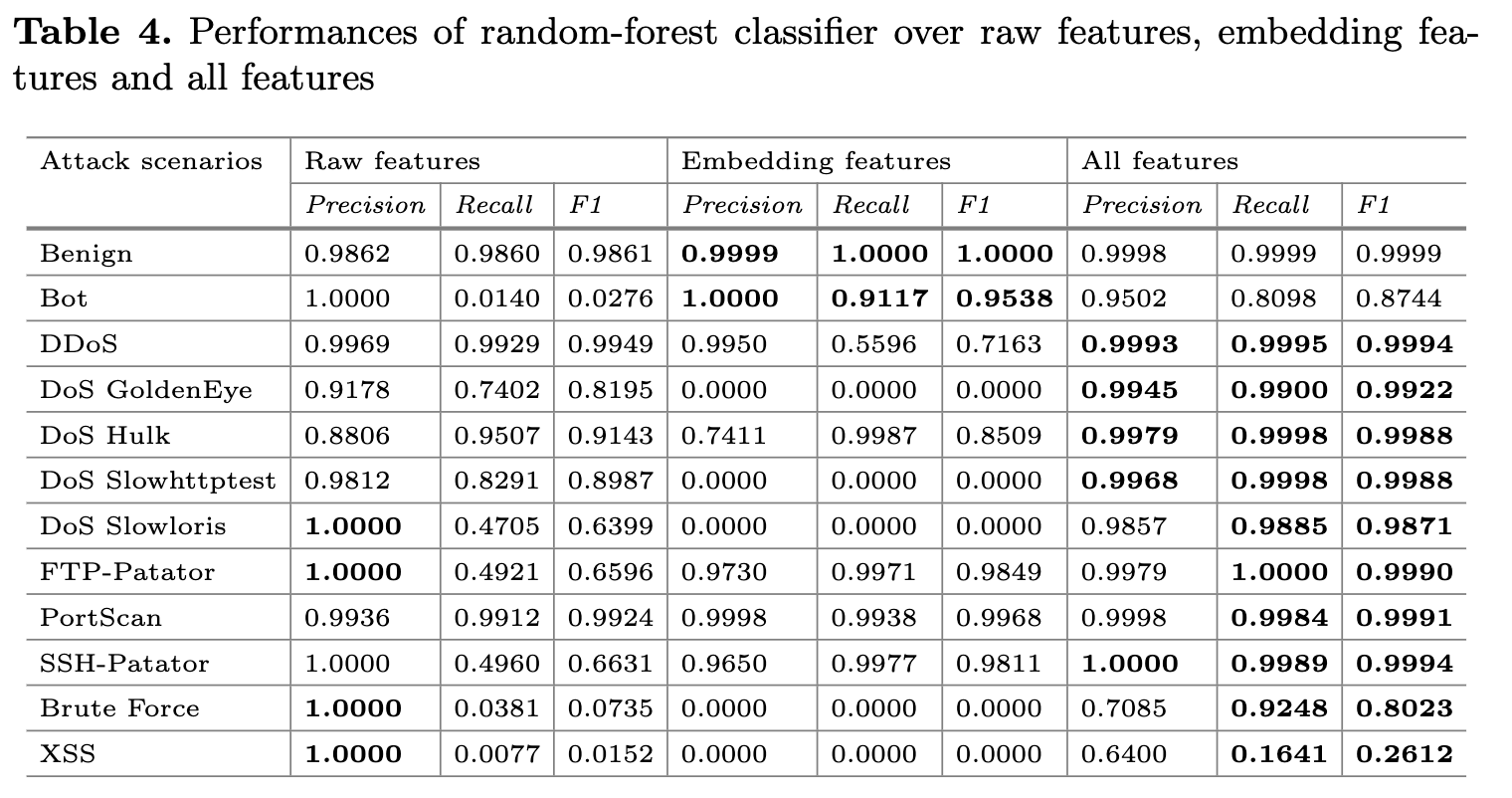
加上文本的embedding之后准确率和召回率有所提升。
表4显示了实验结果。 从表中可以看出,仅使用原始特征来训练分类器,分类器的检测精度就很高,但是召回率却相对较低,尤其是机器人,XSS和brute force。 因此,分类器的F1度量较低。 另外,仅使用嵌入特征训练的分类器的结果也不太有效。 尽管它在多种攻击场景(例如Benign,Bot和Portscan)中具有很高的检测准确性和召回率,但它具有无法检测到的多种攻击场景(例如DoS GoldenEye,DoS Slowhttptest和XSS)。 如果同时使用原始特征和嵌入特征来训练分类器,则可以极大地提高分类器的性能。 它不仅具有较高的检测准确率,而且具有较高的召回率。

图5显示了三次评估的混淆矩阵。 从图中可以看出,仅使用原始特征训练的分类器将大量恶意流量分类为良性流量,攻击误报率较低。 尽管经过嵌入功能训练的分类器无法准确检测攻击情况,但很少将恶意流量归类为良性流量,攻击误报率非常低。 使用原始特征和嵌入特征训练的分类器具有两者的优点。 它不仅可以识别恶意流量,还可以准确检测不同的攻击情形。
(其实异常流量检测很看重的一点是找得准,而非找得全)
未知威胁发现
把前文提到的11种恶意流量中的6种攻击流量和60%的正常流量一起作为训练集,其余5种攻击流量和40%的正常流量作为测试集,看是否能识别未在训练集出现的流量。(识别未知应该在真实下测试才好呢)
结果显示能识别“变体”,比如DoS GoldenEye这种,但是对于识别新攻击能力有限。
相关工作
相关工作中有一篇也是用的图:
Yao, Y., Su, L., Zhang, C., Lu, Z., Liu, B.: Marrying graph kernel with deep neural network: a case study for network anomaly detection. In: Rodrigues, J.M.F., et al. (eds.) ICCS 2019. LNCS, vol. 11537, pp. 102–115. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-22741-8 8