一句话理解
针对DoT/DoH的流量识别,类似于网站指纹,由于DoH普遍有固定长度padding,这里识别时间熵和字节熵,再结合一些DNS事务中请求的依赖关系做识别。
缺点:时间会被网络影响。
分类器很简单,特征也简单。
本文解决的问题
TLS上的DNS(DoT)和HTTPS上的DNS(DoH)对DNS进行加密,以通过对被动对手隐藏DNS解析来保护用户隐私。 但是,过去的攻击表明,加密的DNS对流量分析仍然很敏感。 因此,RFC 8467建议在加密之前填充消息,这大大降低了加密流量的特征。 在本文中,我们表明仅靠填充不足以应对DNS流量分析。 我们提出了一种新颖的流量分析方法,该方法结合了大小和时间信息,可以完全基于加密和填充的DNS跟踪来推断用户访问的网站。 为此,我们对DNS序列进行建模,以捕获通常触发数十个DNS解析而不是单个DNS事务的网站的复杂性。 根据Tranco排名前10k的网站进行的封闭世界评估显示,攻击者可以对86.1%的所有网站的测试痕迹进行匿名处理,甚至可以正确标记65.9%的所有痕迹。 我们的发现破坏了DoT / DoH中最新消息填充策略的隐私目标。 通过得出结论,成功缓解此类攻击必须消除查询响应之间的到达时间间隔的熵。
背景
DNS隐私暴露的危害
隐私的一条关键路径是在客户端与解析器之间,在此可以窃听多个实体,例如Wi-Fi接入点或Internet服务提供商(ISP)。 他们可以使用此信息做广告或创建受害者的浏览档案。 用户访问网站后,客户端会将一个或多个DNS查询发送到解析器,解析器可以从缓存中对其进行回答,也可以执行迭代查找以查询权威名称服务器(AuthNS)。 这意味着DNS几乎将所有用户行为泄漏给任何窃听者。
防止DNS隐私暴露的方式
DoT全称是DNS over TLS,它使用TLS协议来传输DNS协议。TLS协议是目前互联网最常用的安全加密协议之一,我们访问HTTPs的安全基础就是基于TLS协议的。相比于之前使用无连接无加密的UDP模式, TLS 本身已经实现了保密性与完整性。
DoH全称是DNS over HTTPs,它使用HTTPs来传输DNS协议。DoH的安全原理与DoT一样,他们之间的区别只在于:DoH有了HTTP格式封装,更加通用。
DoT专用853端口,DoH和其他加密流量一样用443端口。
然而,类似于利用加密的其他保护隐私的通信系统(例如,HTTPS [25、33]或Tor),DoT和DoH容易受到流量分析的影响。 吉尔莫尔(Gillmor)的经验评估表明,被动攻击者可以仅利用单个加密DNS流量的规模来缩小查询的域名的范围。 然后,RFC8467遵循Gillmor的建议来填充DNS查询和对128 B / 468 B的倍数的响应。
简而言之:DoT/DoH + padding
本文工作简介
尽管填充策略破坏了消息的熵,但我们评估了DNS解析序列(例如,由于第三方内容所致)在多大程度上允许攻击者揭示网站目标。 这样的序列利用DNS消息大小和DNS事务之间的定时信息。
然后,我们利用k最近邻分类器在先前训练的模型中搜索最相似的DNS事务序列。 我们的封闭世界评估表明,攻击者可以对所有测试跟踪的86.1%进行匿名处理,并且我们将展示DNS如何为执行子页面不可知的域分类提供更好的基础。
之前的工作
[13] Rebekah Houser, Zhou Li, Chase Cotton, and Haining Wang. An investigation on information leakage of DNS over TLS. In Proceedings of the 15th International Conference on Emerging Networking Experiments And Technologies, 2019.
[27] Sandra Siby, Marc Juarez, Claudia Diaz, Narsea Vallina-Rodriguez, and Carmela Troncoso. Encrypted DNS ! privacy? A traffic analysis perspective. In 27th Annual Network and Distributed System Security Symposium. The Internet Society, 2020.
[13]通过使用大小和时间的统计特征来解决DoT。 在最相似的情况下,他们报告仅98个网站的数据集的正确分类率为83%。
他们通过使用机器学习(ML)分类器对DNS消息的时间序列的统计特征进行DoT分析。 他们的威胁模型与我们的威胁模型相同。 该特征集是根据DNS消息的时间序列构建的,其中包括时间戳,加密消息的长度和流量方向。 他们从中提取更高级别的功能,例如查询或响应长度,数据包总数,时间间隔或每秒查询。 对于每个更高级别的功能,他们计算一系列统计信息(最小,最大值,中位数,均值,十分位数和计数),然后将其输入到ML分类器中。 他们使用两个自学习分类器,随机森林和Adaboost。 对于域类别推断(即域与约会或赌博相关),他们报告未填充数据的正确分类为93.65%至96.12%。 使用填充数据时,此比例最多下降到78.7%。 像我们的论文一样,使用填充来识别单个网站只能实现83%的正确分类。 这些结果适用于仅包含98个敏感网站的数据集。
[27]没有利用时间特征,在1500个域名的数据集中,他们报告的精度为94%。
Siby等分析了DoH的隐私,侧重于未填充的流量,但评估了填充的影响。 主要特征是一个字节序列,其中的符号表示流量方向,其值表示TLS记录长度或突发的组合大小。 然后,使用滑动窗口将此序列转换为二元字母,然后输入到随机森林分类器中。 重要的是,它们不使用任何时序信息,但是,在表3中,我们发现时序非常重要。 封闭世界的数据集范围为700到1500,开放世界的数据集范围为5000。 当在与我们相当的封闭世界数据集上进行评估时,它们报告的精度为94.0%。 根据他们自己的报告,DoT的分类比DoH困难得多,F1分数降低了0.3。 本文的优势在于进行各种评估,使用不同的客户端,解析器和填充配置进行测试。
与这两篇论文相比,我们使用最大的数据集(1万个域)和地址与子页面无关的分类,并评估对策。
本文贡献
- 说明了一个流量分析攻击,它利用DNS事务序列显示客户访问的网站。
- 我们对DNS消息填充(RFC 8467)提供的隐私担保进行了广泛的分析,以抵御我们在Web浏览上下文中的攻击。我们展示了严重的隐私损失,即使是被动的对手嗅探到加密和填充DNS传输,并将分析范围扩展到索引页之外。
- 我们是第一个评估替代填充策略和恒定速率通信系统的研究。我们发现,即使是完美的填充也无法减轻流量分析的压力,并且表明任何有效的对策都需要将时间混淆。
流量分析和DNS Padding
加密的DNS仅留下三个特征,可用于推断通信内容
(i)计数(例如数据包)
(ii)大小(例如总传输字节)
(iii)时间
这三个维度提供了有关通信内容的宝贵提示。 有两个标准描述了如何添加填充以减少大小信息:RFC 7830 描述了如何向DNS消息中添加填充,而RFC8467建议了一种将所有查询填充为128 B的倍数的填充方案,同时对所有响应进行填充 到468 B的倍数。
DNS Sequences
填充建议基于单个查询/响应对。 我们证明,与单个DNS事务相比,攻击者可以利用一系列DNS查询/响应对来增加独特性。
网络浏览会导致DNS查询序列,其原因很多,例如重定向,第三方资源的加载或子域名的资源。正如我们将要展示的,这些序列很好地描述了用户的网站访问。
比如访问“ wikiquote.org”,该访问会触发四个DNS请求/响应。 它获取域的IP地址,然后在287毫秒后获取“ www”子域,然后又获取211毫秒后同时获取“元”和“上传”子域。 生成的DNS序列(忽略请求)看起来像Msg(1),Gap(8),Msg(1),Gap(7),Msg(1),Msg(1)。 DNS序列对四个DNS响应(每个468 B长,即一个填充块)进行编码。 如果两个响应之间存在时间间隔,我们会使用毫秒的对数刻度记录此间隔及其大小(例如,log(287) = 8)。 这使其例如由于网络抖动而不太容易受到定时变化的影响。 我们会删除所有数值为0(即小于1毫秒的数值)的时间间隔,例如最后两个Msg之间的时间间隔。
DNS序列仅包含DNS响应,因为我们发现DNS查询几乎没有熵,并且它们的时间与答复高度相关。 我们选择抽象地表示消息的大小和时间戳,因为这提供了更高的灵活性,并且可以对我们控制范围之外的不同实现和事件进行概括(例如,网络性能,抖动)。 总体而言,这在保留大多数功能的同时简化了我们的设计。
DNS Sequence Extraction
我们从加密和填充的流量中得出DNS序列。 我们使用端口(用于DoT的端口为853),IP地址(例如9.9.9.9),TLS握手[15,16]或类似DNS的特征(例如数据包大小)来识别DNS承载的连接。 然后,我们重新组合这些TCP流并提取“应用程序数据” TLS记录。 在进行一些数据清理之后,例如合并连续的记录并忽略诸如证书之类的开销,我们仅保留消息大小和DNS消息的到达间隔时间。
DNS Sequence Classifier
我们的分类器使用k最近邻居(k-NN)根据最近邻居的标签为DNS序列分配标签,即最类似于未标记的DNS序列。 假设相似的DNS序列属于同一网站。 k参数指定应搜索多少个邻居,并且找到的k个标签中的多个确定输出分类。
我们将距离函数基于Damerau-Levenshtein /编辑距离。 它使用插入,删除,替换和转位这四个操作来计数将一个序列转换为另一序列所需的编辑操作。 根据每个操作的重要性,我们为每个操作分配不同的成本。 例如,对易失性定时信息的改变比对相当稳定的大小信息的改变具有较低的成本。 我们通过对封闭世界数据集的子集进行超参数搜索来优化这些常数。
实验和评估
现在,我们将评估我们提出的方法论对从流量捕获中获取的DNS序列进行分类的功效。 我们将简短描述数据集生成设置,然后介绍两个评估方案。 封闭世界方案显示了基线分类性能,而与子页面无关的域分类将分类扩展到了索引页面之外。
实验设置
我们通过访问Tranco列表[30]中的顶级网站并记录DNS流量来创建数据集。 我们使用的服务器具有运行Debian9.11的10 GB = snetworkinterface。 对于封闭世界场景,我们还使用运行Raspbian 10的Raspberry Pi 3收集数据。低功耗Pi使我们能够测量硬件性能对数据集收集和分类器的影响。
对于每个网站,我们都生成一个运行Firefox 72和Unbound 1.9.4作为DNS存根解析器的Docker容器。 我们将Unbound配置为使用DoT将所有DNS查询转发到1.0.0.1和1.1.1.1的Cloudflare解析器。 Unbound的DNS缓存已预载了所有TLD的NS条目,因为我们认为由于过去的决议,用户将缓存这些记录。 我们使用Selenium控制Firefox。 如果我们检测到错误(例如缺少DNS流量或HTTP错误),则重复进行多达两次的测量。 最后,我们将网络流量转换为2.1节中所述的DNS序列,并根据网站对其进行标记。 我们将相同的网站归为一个标签,例如对于本地化版本使用不同TLD的网站。
结果评估
我们在两个设置中评估分类器。 首先,封闭世界突显了攻击者的最佳情况,并为性能提供了基准。其次,我们执行了与子页面无关的域分类,其中我们分类的不仅仅是索引页。
封闭世界场景
封闭世界场景对攻击者来说是最容易的,因为客户机可以访问的所有网站都是预先知道的。攻击者只需要确定访问了哪个已知网站。
我们的数据集由Tranco列表[24,30](2019-08-27)中排名前10000个网站组成,我们每个网站都收集了十个样本。 对于9235个网站,我们可以收集此数据,其他网站反复导致错误,而我们不能收集十个DNS序列。在树莓派上选择了第二个DNS序列集,为此我们收集了四个追踪每个网站的信息。 已成功收集了7699个网站的数据。
在此完全标注的数据集对所有的DNS序列使用10折交叉验证,因为我们每个网站上只有十条痕迹,并且可以测量表1中正确分类的DNS序列和显示结果的百分比。
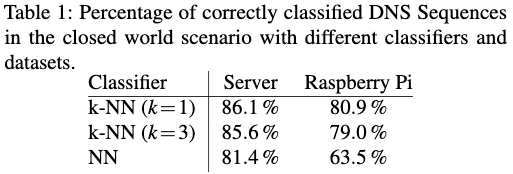
k-NN分类器在服务器数据集上达到最高86:1%,在Raspberry Pi数据集上达到80:9%,两者都为k =1。我们注意到,较高的k会稍微降低分类器的性能,但并不明显,因此 即使k = 9,服务器数据集的性能也只能下降到82:9%。
k-NN分类器在服务器数据集上达到最高86:1%,在Raspberry Pi数据集上达到80:9%,两者都为k =1。我们注意到,较高的k会稍微降低分类器的性能,但并不明显,因此 即使k = 9,服务器数据集的性能也仅下降到82:9%。
表2中每个网站的结果显示了我们如何对网站进行分类,而不是对DNS序列进行分类。 我们对所有网站的三分之二实现了完美的分类(即10 / 10)。 如果我们放宽对每个网站90%正确分类的要求,则可以完全基于加密和填充的DNS流量正确分类约80%。

我们使用神经网络构建第二种分类器,也如表1所示。对于服务器数据集,分类器的表现相同(81.4%),而对于Raspberry,分类器的分类率仅为63.5% Pi数据。 由于结果比k-NN分类器差,因此我们不做进一步考虑。
子页面不可知域分类
网站指纹识别(WF)的一个挑战是子页面不可知的domain分类,这也是一个更现实的场景。攻击者面对的是目标域的任意子页,而不是只在索引页中执行分类。这种设置的挑战是子页面的高度可变性,例如,由于不同的嵌入图像或不同数量的文本,以及更大的空间(通常一个域有许多子页面)。
我们构建的基于DNS的加密分类器在此具有明显的优势,因为DNS请求比基于HTTP(S)的WF更稳定。 直观上,DNS请求主要取决于第三方域(例如,对于JS库或字体)。 这些通常在模板中定义,因此对于许多子页面都是相同的。 HTTP(S)流量比较嘈杂,因为数量和具体图像经常在子页面之间变化。
使用混淆矩阵Pancheko的方法进行对比:
Andriy Panchenko, Fabian Lanze, Jan Pennekamp, Thomas Engel, Andreas Zinnen, Martin Henze, and Klaus Wehrle. Website fingerprinting at internet scale. In23rd Annual Network and Distributed System Security Symposium, 2016.
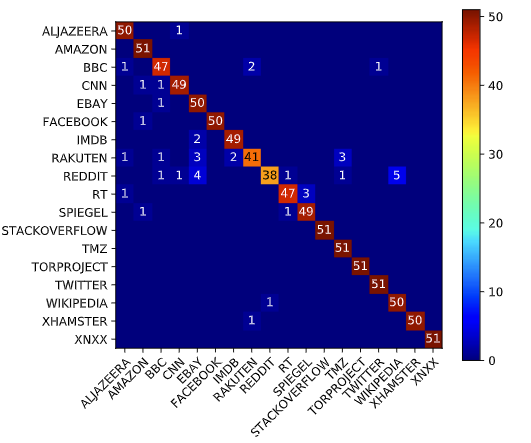
对于与Panchenko等人相同的20个域集合,我们从2019年10月的普通爬行[4]数据集中随机选取51个uri。只有解析为200状态码的域是合格的。
与Panchenko等人 [23,图11(b)]相比,我们在图1中的分类错误要低得多。在918个子页面中,只有43个(4:7%)被错误地分类,而Panchenko等人则被错误分类。 错误地分类175(19:1%)子页面。 总体而言,我们的方法在18个域中的15个域上表现更好。 最具挑战性的领域是RAKUTEN和REDDIT,其中我们的分类器表现较差。 我们可以取得更好性能的原因之一是DNS流量的方差低于HTTP(S)流量。
反制措施
我们证明了基于加密DNS流量的攻击是可行的。 现在,我们通过了解分类器的两个主要特征类型(大小和时间)的影响来分析应在哪些方向上制定对策。 基于这些见解,然后我们描述潜在的缓解措施。
评估完美的缓解措施
我们的分类器使用两种功能类型:数据包大小和定时信息。 为了建立更好的对策,我们首先需要了解哪个功能会带来更大的熵,因为缓解该功能会产生最大的影响。 为此,我们进行了一次思想实验,其中我们假设了完善的缓解措施,即完善的填充方案和完善的时序防御。 我们通过删除Msg元素(用于完美填充)或DNS序列中的Gap元素来模拟这些元素。

我们使用这些修改重新运行了封闭世界分类,并比较了表3中的结果。对于完美的填充防御,我们看到的只是微小的差异,但是,对于时序防御,我们看到了性能的大幅下降。 这表明现有的填充机制已经接近最佳。 相反,基于定时的完美防御会破坏分类结果。 序列中DNS响应的到达时间间隔带有很大的熵,我们用它来对完全填充的流量进行分类。
首先,当前提出的填充策略确实是开销与最大私密性之间的良好折衷,而最佳私密性可以保证最佳填充。 第二,即使是最佳的填充策略也不会降低跟踪的熵,也不足以保护用户的隐私。 第三,对策还应考虑到时序信息,因为时序已被证明对DNS序列具有重要的熵。
评估实际缓解措施
基于这些观察,我们现在实施两种实际的缓解措施,并评估其功效和效率。
Constant-Rate (CR) schemes
该方式每x毫秒在一个固定的时间表发送数据包。如果正在等待,则该数据包将充满有效负载,否则将填充数据。 由于一切都是恒定的,CR会完全删除时序信息。 但是,CR具有显着的带宽和延迟开销,因为即使没有有效负载正在等待,也必须发送数据包,并且数据包必须等待直到下一个计划的传输时间,从而增加了延迟。 较大的x会减少带宽开销,但会产生较大的延迟开销。 最后,CR需要终止条件以避免无限传输。 我们定义了概率p,它指定了在流结束后发送伪数据包的可能性。
Adaptive Padding (AP)
自适应填充(AP)通过掩盖客户端的统计时序特征来缓解时序侧信道。 AP通过在创建突发和等待下一个突发之间进行切换,以与实际流量无法区分的时间发送虚拟流量。 突发大小,突发间和突发内时间必须来自现实的分布,因此我们从封闭世界数据集中提取它们。
Comparing AP with CR
为了比较它们,我们创建了一个实验性设置来测量不同配置下的它们。我们实现了一个点代理,将其放在未绑定和点服务器之间,从而在客户端上提供缓解。从技术上讲,我们模拟了对DNS序列的影响,从而可以更快地进行测试而无需重新生成跟踪。
我们使用10倍交叉验证设置来测量缓解效果,该设置用于变化的数据包速率xms(对于CR)和概率p(对于CR和AP)。 我们测试从12毫秒到100毫秒的四个数据包速率,以及从0.4到0.9的六个不同概率的p。 我们测量其他DNS消息中的带宽开销,解析时间的增加,忽略伪数据包以及对分类结果的影响。
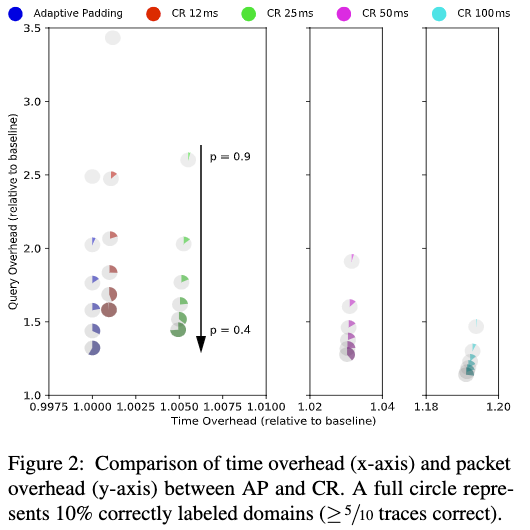
表2显示分类结果。 它用颜色编码,AP为蓝色(圆圈的最左列),其余颜色为CR。 x轴显示的时间开销是未修改基线的一个因素。 类似地,y轴以1为基准衡量DNS消息数量的开销。 每个圆圈的彩色切片的大小表示分类结果。 在正确分类的5条= 10条迹线中,一个完整的圆圈等于10%的分类成功率。
所有变化都成功削弱了我们的分类器。对于类似的防御强度,AP具有比低速率CR更高的带宽开销,但低于快速速率CR。 对于交互式用例,AP可能会更好,因为它没有时序开销,但是当考虑带宽时,发送速率较慢的CR可能比AP更可取。
讨论和结论
我们的工作有助于了解DNS用户面临的隐私威胁,以及如何保护他们。分析新的侧信道攻击变得更加重要,因为为了减少(明显的)隐私泄露,越来越多的加密技术已成为一种普遍趋势。
由于这是连接到Internet的第一步,因此DNS成为侦听用户隐私的重要目标。 考虑到我们将自己限制在加密和填充的DNS流量中,我们发现提供的分类结果非常令人震惊。 我们可以部分取消对网站的92:2%的匿名处理,并正确对86:1%的DNS序列进行分类。 我们研究的首要目标,是评估成功的guaran-teesofencryptedDNS隐私,因为它已经显示出了棘手的隐私问题。 通过将我们的方法与现有的WF方法相结合,可以进一步提高分类的准确性。 话虽如此,我们提议的方法存在一些局限性,我们将在下面进行介绍。
数据集:在封闭世界数据集中,我们使用了9235个网站/ 92350个DNS序列的相当广泛的数据集。 相关的WF攻击论文通常在其数据集中使用数量很少的网站,范围从几十到数百。 较大的数据集会导致准确性和查全率下降,这意味着在与这些论文相同大小的数据集上,我们的结果会更好。
DNS流量识别和提取:从网络捕获中提取DNS序列的方法假定DNS服务器本身是可识别的。 DoT通过使用专用的TLS端口在这里为我们提供帮助,并且大多数DoH服务器都具有专用的IP地址。
类似地,我们假设我们可以从TLS流中提取消息大小,这对于当前的实现是可能的。 他们尝试通过使用单个TLS记录进行DNS回复来使用小型TLS记录来传输数据。 原则上,DNS消息可以在许多微小的或相等大小的TLS记录中传输,从而妨碍了精确提取消息大小的尝试,但是由于处理更多和网络开销增加了成本。
用户建模:对于我们的实验,我们为特定的用户行为建模,但是在实践中可能会有所不同。 首先,我们假设客户端正在等待网站完全加载,没有任何后台DNS流量。 其次,使用空的浏览器缓存和DNS缓存(仅包括有效TLD)进行评估。 实际上,用户的DNS缓存和浏览器缓存可能具有不同的状态,这可能导致发送的DNS请求减少。 但是,所有主要的浏览器都实施了基于第一方域[3、9、32]对浏览器缓存进行分区的策略。 这样可以防止浏览器跨域重复使用公用资源,并且可以防止用户从网站进行跟踪。 考虑到我们的攻击只能在网站停留的首页访问中起作用,因此我们认为模拟空缓存对于许多网站而言是一个合理的近似值。 虽然部分缓存可能会降低分类器的准确性,但有人可能会说有状态的对手可以利用我们的攻击来为用户的DNS缓存状态建模。 知道了这些,攻击者可以通过对具有特定缓存状态的预期跟踪进行重新训练来适应训练数据集。 我们计划将来进行此类分析并根据分类器进行相应调整。
特征集:Houser等人使用最广泛的特征集,包括时间、大小和方向性,而Siby等人使用大小和方向性。我们使用大小和时间,但忽略方向性,因为我们只使用下游流量,因为我们发现上游几乎不包含熵。
Houser等人使用可检查的自学习分类器,允许他们列出最重要的特性。在个别网站分类与填充的情况下,他们是不同的时间特征,就像我们在4.1节的结果。 有趣的是,在执行域类别推断时,时序即使在填充时也几乎不起作用。 Siby等人只使用低级字节计数,没有时序特征,因此特征重要性不适用于他们的分类器。
独有贡献:最重要的是,我们是唯一实施和测试针对加密DNS指纹的对策的工作。 之前两篇论文都测量了填充对其分类结果的影响,而我们仅使用标准化的128 B / 468 B块填充来评估分类器对填充数据的影响。 此填充也是相关论文中测试的最激进的填充。 Siby等。 测试另外两个配置,一个完美的填充,其中所有大小都无法与我们在第4.1节中进行的工作类似,并且在Tor上通过DNS进行隧道传输的效果。 Houser等人仅讨论高级防御概念,即隐藏确切的大小和时间信息。
我们是唯一测量子页面不可知分类的人,在这个分类中,我们访问的网页超出了索引页,由于页面的多样性,这是一个本来就更复杂的任务。