一句话理解
总结了可选的加密流量功能,并针对不同的数据集详细分析了功能选择的方法。
(大海啊,你全是水~)
本文解决的问题
作者认为很多工作都只能针对特定数据集,不是通用的。本文提出一种针对加密流量分类优化特征选择的系统方法。
比如Feghhi和Leith [1]提出了仅采用定时信息的加密Web流量分类攻击。
[2]仅使用分组长度信息来基于客户端和服务器之间的双向交互对加密的网页流量进行分类。
第一个挑战是收集在流量分类中可能有效的加密流量功能。 这些基于数据包内容的功能不适用于加密的流量分析,这超出了我们的考虑范围。 第二个挑战是特征的选择和优化。 当我们获得了大量可能有效的加密流量功能时,如何根据特定场景对这些功能进行过滤并优化功能组合是实现通用加密流量分类的最关键步骤。
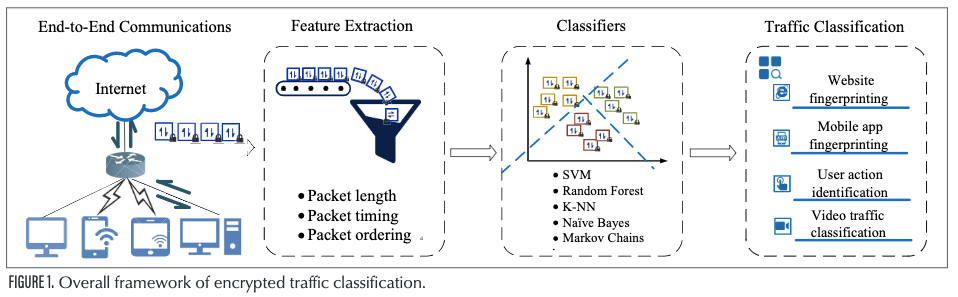
本文提出了一种高效加密流量分类特征选择的系统方法。在下一节中,我们将给出加密流量分类工作在何处进行的宏观解释,并详细阐述目前最先进的加密流量分类研究。然后指出了加密流量的特征集。接着,我们描述了如何评估和组合不同数据集的特征。接下来,我们展示我们的实验表现。最后,提出了未来的研究方向,并对本文进行了总结。
加密流量分类概述
例如,一些研究人员使用来自Tor或其他加密网络的流量来识别网站指纹,其他研究人员则对由移动应用程序生成的加密流量进行分类,而另一些研究人员则可以识别加密的视频流量,例如视频标题和视频类型。 图1显示了加密流量分类的总体框架。 加密流量分类研究的几种常见类型如下。
网站指纹
Feghhi和Leith [1]提出了一种网站流量分类方法,该方法仅使用链路上的分组时间信息。 他们应用了动态时间规整(DTW)来按时间顺序对流量跟踪进行分类。 他们的方法不需要实现网络获取的开始或结束。 Panchenko等[6]采用累积数据包长度序列作为网站指纹,并从具有不同长度的流量跟踪中提取了固定数量的判别特征。 Wang等[7]计算了数据包序列之间的距离以实现网站指纹识别。
都不是特别新的文章,分别是16和14年的。
手机应用指纹
Taylor等人[8]提出了一种应用数据包长度统计数据的Android应用程序指纹识别方案,称为AppScanner。它具有自动指纹识别和实时识别的能力。Shen等人[9]利用二阶马尔可夫链对不同移动应用产生的加密流量进行分类,他们的程序基于包含证书包长度和SSL/TLS流量中第一个应用程序数据大小的应用程序属性双元组的特性。Mauro等人[10] 通过对Android加密网络的分析,实现了用户行为的识别。他们采用DTW算法来计算数据包的序列并提取特征。然后用随机森林作为分类器。最后,通过聚类得到用户行为的分类。
视频流量分类
Ran等人[11]提出了一种通过分析加密流量对视频流标题进行分类的方案。使用采用支持向量机和最近邻作为分类器。他们还可以识别训练集中不存在的视频标题为未知。Dong等人[12]提出了一种基于k-最近邻算法的视频流量细粒度分类方法。
下表是上述文章的汇总
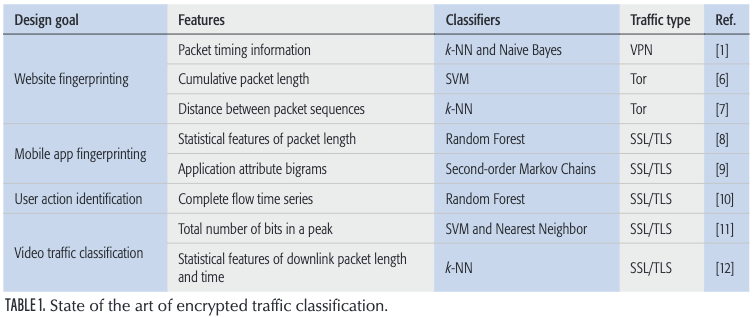
尽管许多研究人员提出了各种加密的流量分类方案,但是这些方案并不是通用的。 换句话说,所有这些方案仅对研究人员提出的特定数据集具有良好的效果。 替换数据集时,许多方法会失去效果。 基于这种情况,我们展示了可用于区分加密流量的候选功能,并提出了一种系统的方法来优化功能选择,以实现有效的加密流量分类。
值得注意的是,虽然一些现有的流量分析方案[8]也考虑了评估特征贡献,但本文提出的方法与现有方法有几个明显的区别。
V. F. Taylor et al., “Robust Smart phone App Identification Via Encrypted Network Traffic Analysis,” IEEE Trans. Info. Forensics and Security, vol. 13, no. 1, 2018, pp. 63–78.
首先,我们给出一个系统格式的方法来总结所有的类别及可从加密流量中提取的候选特征的子类别。而现有的研究仅仅关注于具体的和有限制的特征数量。其次,考虑特征之间的关联关系及其对结果的影响,根据不同的场景(目标和约束)的需要灵活选择特征。这个框架在现有的方法中并不存在,因为现有的论文通常已经预先设定了一个固定的场景。总体而言,我们的方案具有较强的通用性,可以有效地分析任何交通数据集,为今后的流量分类工作提供指导。
加密流量的特性集
如表1所示,可以使用加密流量的大量特性来训练高效的分类器。然而,现有的研究仅仅关注于被证明与他们使用的数据集不相关的具体特征,留下整个候选特征空间未被利用。因此,我们总结了可从加密流量中提取的候选特征的类别和子类别。
为了分析起见,有必要基于以下五元组将杂乱的加密流量分类为多个流:源/目标IP地址,源/目标端口号和协议(TCP / UDP)。 对于每个流,考虑三种类型的分组序列:仅上行链路分组,仅下行链路分组和完整的分组集(即,上行链路和下行链路分组两者)。 此外,我们将上行链路数据包突发定义为一组上行链路数据包,其中没有两个相邻的下行链路数据包。
基本包长度的特征
由于数据包长度是网络数据包的附属功能,因此数据包长度信息已成为一种常用功能,并已证明其在加密流量分析中的有效性。
包长序列
对于每个流,可以将前n个数据包的数据包长度序列用作重要功能。 例如,由于单个网站的内容和协议参数(例如SSL / TLS握手过程中的内容和协议参数)不同,因此前n个数据包在各个网站的数据包长度方面可能会有很大差异。
Unique包长度
流中唯一数据包长度的存在是一个重要特征,文献[7]中也提到了这一点。 它表示在流量数据集中,某些数据包长度仅出现在一种流量类型中,而没有出现在其他流量类型中。 我们能够利用独特的数据包长度来区分不同类型的流量。 但是,如果存在数据包填充(例如Tor),它将失去效果。
包长box
流中数据包的长度通常分散在数据包长度间隔内。 为了获得流中数据包长度的统计特征,我们可以将数据包长度汇总到固定数量的盒子中。 假设每个盒子代表一定范围的包长度; 获得落入每个范围的分组长度的数量是很简单的。
累计包长序列
在考虑流向时,我们可以先将上行数据包的长度设置为负,将下行数据包的长度设置为正。 然后,我们向前累积数据包长度,以获得前n个数据包的累积长度序列。 当将流视为无方向时,可以将上行和下行数据包的长度设置为正值。 流中的前n个数据包的累积长度序列被作为判别特征。
统计特征
对于每个流,我们能够计算数据包长度的统计值,例如最小值,最大值,平均值,绝对斜率中位数,标准偏差,方差,偏斜,峰度,百分位数(从10%到90%),长度总和, 和数据包的数量[8]。 对于三个数据包系列(上行数据包,下行数据包和完整数据包),我们总共考虑了这57个统计值。
基于数据包排列的特征
在某些情况下,包长度在不同的加密业务流中是固定的或相似的,从而使基于数据包长度信息的那些功能不太有效。 例如,Tor使用单元填充技术在固定大小(512字节)的单元中发送数据。 为了处理这些情况,可以将分组排序信息视为重要特征。
数据包数量
可以考虑几种类型的数据包计数。 我们可以计算每n个数据包集的上行链路和下行链路数据包的数量。 此外,每个上行链路分组之前的分组总数也是有用的特征。 我们可以提取指示每两个上行链路数据包之间的下行链路数据包数量的功能。
Burst计数
如文献[13]所示,爆发是一个重要特征。 在此,我们将重点放在上行链路数据包突发上,因为下行链路数据包容易受到网络延迟的影响。 我们将突发视为一个整体,并计算突发数量以及每个流中突发长度的最大值和平均值。
T. Stöber et al., “Who Do You Sync You Are?: Smartphone Fingerprinting Via Application Behaviour,” Proc. 6th ACM Conf. Security and Privacy in Wireless and Mobile Networks, 2013, pp. 7–12.
数据包的时间信息
一些研究人员还利用包的时间戳对加密的加密通信进行分类。从包定时信息中提取的特征如下。
数据包间的延迟
对于每个分组序列,分组间延迟被定义为两个相邻分组的时间戳的差异序列。
数据包计数和时间的组合
对于每个数据包系列,我们计算特定时间间隔内的数据包数量。 这指示了数据分组传输被集中的时间段。
从理论上讲,我们将所有这些特征均等对待。 但是,时序特性通常不会起作用,因为在不同网站中的时序分布是相似的。 此外,网络波动会极大地影响数据包的时间戳信息。 因此,在大多数情况下,我们会优先考虑其他特征。
一种优化特征选择的系统方法
本节介绍一种优化特征选择的系统方法。如图2所示,特征选择框架由特征预处理、特征评估和特征组合三部分组成。
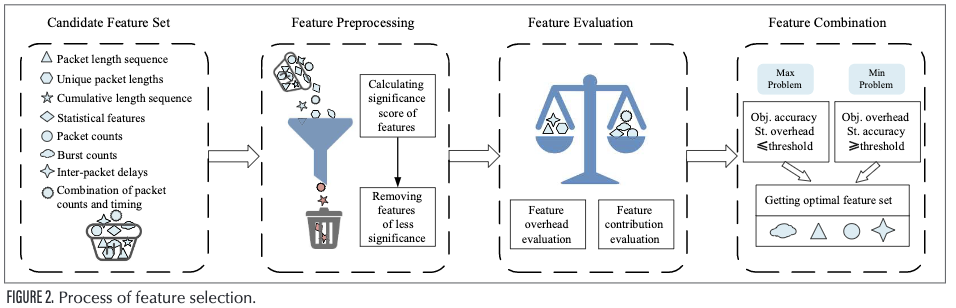
特征预处理的目的是在没有偏见的情况下预先删除流量特征。 在这三个步骤中,特征评估是最重要的一步。 通常从两个方面考虑对特征的评估:特征贡献和特征开销。 对于不同的问题,特征评估的重点可能有所不同。 稍后将提供更多详细信息。
经过数据预处理和特征评估后,我们需要选择并组合有意义的特征并将这些特征输入到分类器(例如机器学习模型)中,以实现流量分类(例如网站指纹识别)。 特征选择的主要目的是减少特征的数量和尺寸,从而使模型更通用,并减少过度拟合。
特征预处理
为了更有效地找到有意义的交通分类特征,我们需要使用重要性测试对交通特征进行预处理,并删除重要性较低的那些特征。 可以通过计算特征的方差来实现。
假设特征值仅为0和1,并且在所有输入流量的95%中,特征值为1。 因此,可以认为此功能的贡献很小。 如果100%为1,则该功能无意义。 一般而言,如果网络流量的特征值是离散变量,则可以直接计算特征的方差,并去除方差小的特征。 但是,如果特征是连续变量,则在使用它们之前需要将它们离散化。
在实际的流量分类过程中,相同值的特征一般不超过95%。因此,虽然这种方法很简单,但不能很准确地进行分类。因此,我们将其作为特征选择的预处理。我们首先删除值变化很小的那些特征,然后通过下面的方法选择适当的特征。
特征评估
通过特征预处理,首先去除一些低识别率的流量特征。接下来,我们需要从两个方面进一步评估特征:特征贡献和特征开销。
特征贡献评估:特征贡献是衡量特征在流量分类中是否起作用的重要指标。 获得特征贡献的主要方法如下。
Chi-square test
经典的卡方检验是测试定性独立变量和定性因变量之间的相关性。 在流量分类中,它主要用于评估二进制分类问题的特征贡献。 例如,区分加密的流量是否由匿名通信系统(例如Tor)生成。 主要思想是计算每个维度的特征的卡方值并对其进行排名。 卡方值表示要素重要性。
TF-IDF
TF-IDF是一种用于信息检索和数据挖掘的常用加权技术,其中TF表示术语频率,IDF表示逆文档频率。 它主要用于评估单词对文档集或语料库中文档之一的重要性。 我们能够利用这种方法来评估交通分类中的特征重要性。 首先,我们希望对TCP数据包进行编码。 数据包编码可以与数据包的方向,长度和标志位结合使用。 例如,U_54_SY N表示长度为54的上行SYN数据包。然后,我们能够计算编码数据包的TF和IDF值。 之后,我们获得具有TF-IDF频率的数据包。 当涉及到功能选择时,我们能够删除那些TF-IDF频率小于某个阈值的数据包,并利用剩余的数据包进行分类。 当然,期望针对不同的问题进行适当的转换。
Model-based ranking
主流特征贡献评估方法基于机器学习模型。 某些机器学习方法具有自己的评分机制,或者可轻松应用于特征评价任务,包括回归模型、支持向量机、决策树、随机森林等。以随机森林为例,我们可以通过森林中所有决策树的平均杂质衰减来衡量特征的重要性,而无需考虑数据是否可线性分离。 更方便的是,在scikit-learns中实现的随机森林已经为我们收集了有关特征贡献的信息。 拟合Ran-domForestClassifier后,我们可以通过feature_importances获得这些内容。 此外,我们提到的其他机器学习模型是相同的。 结果,该方法方便实用,已被广泛应用于特征贡献评估中。
特征开销评估:特征开销主要包括两个方面:特征提取算法的时间复杂度和空间复杂度。
时间复杂度
特征提取的时间复杂度反映了特征提取时间随交通规模的增加而增加。 在很大程度上,它可以反映特征提取算法的质量。 要计算时间复杂度,我们需要找出特征提取算法中的基本陈述。 算法中最常执行的语句是基本语句。然后我们期望计算基本语句的执行次数的顺序,这意味着只要基本语句执行次数的函数中的最高次幂是正确的,所有的最低次幂和最高次幂的系数都可以忽略。这简化了算法分析,并使我们专注于最重要的一点:增长率。 此后,使用O表示算法的时间性能,n表示问题的严重性。 我们需要将基本语句的执行次数的数量级n放入O。
空间复杂度
与时间复杂度的讨论类似,功能提取算法的空间复杂度定义为该算法消耗的存储空间。 特征提取算法在计算机内存中占用的存储空间包括算法本身占用的存储空间,输入和输出数据以及算法在操作中占用的临时存储空间。 数据所占的存储空间由流量规模决定,并且不会随算法的不同而变化。存储算法本身占用的存储空间与算法编写的时间成正比。
在这里,我们总结了前面提到的每个特性的时间和空间复杂性,并在表2中展示了它。
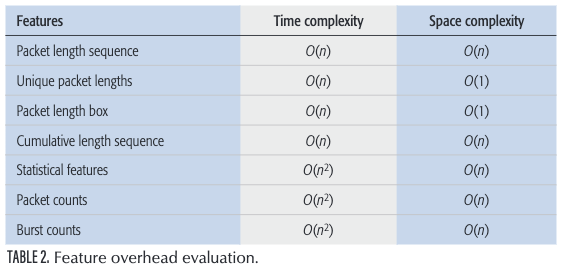
特征组合
经过特征预处理和特征评估,我们得到具有三个属性的特征:贡献度,时间复杂度和空间复杂度。 最后一步是选择特征并将其组合为对应数据集的最佳特征集。 特征组合的主要目的是从原始特征集中选择更具代表性的子集。
在不同的流量分类应用场景中,我们需要的特征是不同的。 有些流量分类方案需要快速响应; 例如,网络管理需要快速识别用户使用非法匿名软件生成的流量并及时阻止流量。 此时,它可以放宽对流量识别精度的要求(例如,不低于70%),但是需要确保识别速度。 相反,对于一些离线流量分类工作,我们更关心的是分类的准确性,而我们对分类的存储和时间消耗具有更大的容忍度。
一般而言,特征选择和组合需要考虑以下两个方面:
- 在确保一定准确性的同时将开销降至最低
- 在开销不超过一定阈值时提高准确性
对于那些需要时空复杂度低的流量分类任务,我们首先需要弄清每个功能的时空复杂度,并优先考虑那些低复杂度的功能。 然后,我们需要评估特征贡献以进一步从中选择有价值的特征。 对于那些需要高精度的流量分类任务,我们需要提取流量特征并按特征贡献对它们进行排名。 在那之后,我们希望能够以较高的贡献率获得这些流量功能。
当我们根据需求对特征进行分类时,最简单的选择特征的方法是依次将它们添加到特征集中,并观察流量分类的准确性,直到达到最高的准确性为止。 另外,我们可以首先尝试在前50%中排名靠前的功能,然后计算分类的准确性。 然后在特征集中添加或减去特征,直到获得最高的精度。
实验和评价
在本节中,我们在Panchenko等人[6]提供的一个自收集数据集和一个代表性数据集上进行了通用流量分类实验,以评估我们提出的方法UTA的性能。用于比较的方案是Appscanner[8]和CUMUL[6]。
A. Panchenko et al., “Website Fingerprinting at Internet Scale,” Network and Distributed System Security Symp., 2016, pp. 21–24.
V. F. Taylor et al., “Robust Smartphone App Identification Via Encrypted Network Traffic Analysis,” IEEE Trans. Info. Forensics and Security, vol. 13, no. 1, 2018, pp. 63–78.
数据集
这里,我们考虑采用Panchenko等人[6]提供的一个典型数据集Panchenko16和我们自己收集的另一个数据集Website100。
我们之所以选择Panchenko16作为我们的实验数据集,是因为它包含了所有公共数据集中最广泛的数据。Panchenko16不仅仅是从有限数量的网站的索引页面中收集流量,它在索引页面之外包含了更多的网站页面,收集了大量的网站流量,能够反映出互联网的代表性样本。Cui等人[14]还利用了Panchenko16来确认他们的方法的有效性。具体来说,它包含来自712个不同网站的1125个可检索网页的访问量,每个网页有40个实例。 该数据集包含有关每个数据包的方向和大小的信息。
包括Panchen-ko16在内的大多数先前的公开数据集都缺少部分流量信息(例如,端口号或到达时间),这使我们无法提取出之前提到的所有候选特征。 结果,我们收集了自己的名为Website100的数据集,该数据集保留了完整的路况信息,以便我们可以提取所有候选特征并进一步进行特征选择。 它由来自中国排名前100位的网站的流量组成。 对于每个网站,我们下载了200个实例。 我们基于五元组表示将流量分为流:srcIP,dstIP,srcPort,dstPort,协议(TCP / UDP),其中srcIP代表客户端IP地址,dstIP代表服务器IP地址,srcPort代表客户端 port num-ber,dstPort代表服务器端口号,protocol代表客户端和服务器之间建立的通信协议。 此外,由于重传主要是由网络状况引起的,因此我们删除了TCP重传数据包。
在以下实验中,我们将UTA应用于这两个数据集以证明所提出方法的通用性。
实验结果
在本节中,我们首先简要介绍两种典型的网站指纹识别方案。 然后,我们提出了UTA解决方案,并采用这两种最先进的方法进行比较,以验证UTA的普遍性。
- CUMUL由Andriy等人[6]提出。该方案拥有迄今为止最高的网站指纹识别精度。他们采用累积包长度来表示流量轨迹,并利用SVM作为他们的分类器。
- Appscanner是Taylor等[8]提出的另一种典型的流量分类方案。这是一种稳健的方法,用于识别使用加密网络流量分析的智能手机应用程序。该方法也广泛应用于网站指纹识别中。它利用上行流、下行流和完整流的54个统计特征作为特征集,使用随机森林对流量进行分类。
性能:根据UTA的思路,我们首先从每个数据集中提取所有可能的有用功能。 数据集是网站流量的集合,这些流量已分组为流量。 前面显示了我们提取的功能。 我们希望对功能集进行预处理,以删除无意义的功能。 我们计算每个特征的方差,并滤除具有低方差的特征。 之后,我们计算剩余功能的贡献。 在我们的实验中,我们利用scikit-learn中实现的随机森林算法来计算特征的重要性。 我们选择了45%的最高贡献功能。 表3显示了我们为两个数据集Panchenko16和Website100选择的功能。 结合这些重要功能后,我们将随机森林用作分类器,并使用10倍交叉验证来获得网站指纹识别结果。
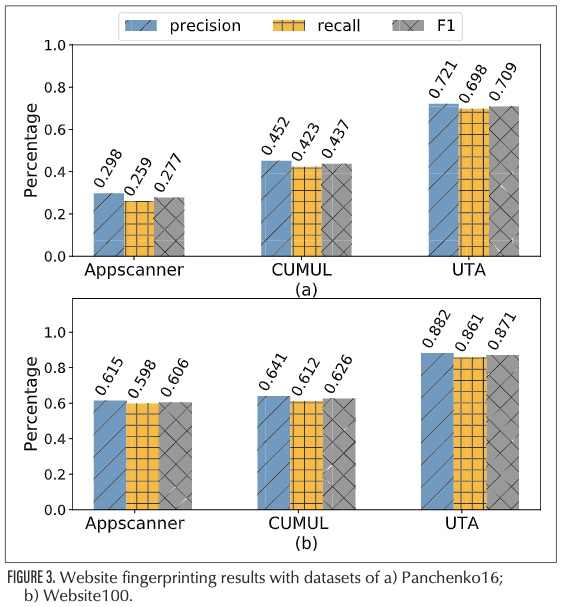
我们考虑三个指标(精度,召回率和F1)来衡量分类结果。 图3描述了这两种方法(UTA,Appscanner和CUMUL)在两个数据集上的性能。 我们可以看到,无论使用哪种指标,UTA的性能都显着高于两个数据集上其他两种方法的性能。 这个结果有力地证明了我们的特征组合方案是有效的,并且UTA比其他最新方案更通用。
挑战和未来看法
我们提出了一种用于加密流量分类的特征选择方法,实验结果表明我们的方法对不同的数据集有效。 但是,仍然需要探索几个问题以进一步改进,挑战和未来的方向如下。
特征和数据集之前的关系
在不同的流量分类问题中,我们通常需要提取大量可能的特征,并反复尝试找到对特定数据集有明显区别的那些特征。 该过程耗时且劳动强度大,几乎没有效果。 因此,当前的挑战之一是要找到数据集和特征之间的关系。 对于给定的数据集,我们能够更快地找到最佳特征。
根据我们的经验,我们初步总结了功能与数据集之间的可能关系。 例如,就双向分类问题而言,我们需要区分是通过打开加密服务应用程序时访问网站还是正常访问网站来生成数据集中的流量。 加密服务应用程序通常具有唯一的信息交换协议,并且该协议通常在分组传输过程中反映在分组长度信息中。 因此,根据经验,我们通常会分析此类问题的数据包长度序列。
对于多分类问题,情况通常很复杂,我们需要根据数据集进行分析。 仍然以网站指纹搜索为例,我们需要确定用户正在通过加密连接访问的网站。 如果数据集中的流量主要由短流(例如,不超过100个数据包)组成,则我们可以主要考虑特殊数据包长度,数据包长度的状态转换特性以及数据包长度的统计特性 。 对于那些主要由长流组成的数据集,我们优先考虑累积数据包长度序列和统计特征。 这些只是初步摘要。 我们需要做进一步的研究,以找到特征和数据集之间的确切关系。
实时检测
(虽然很多工作使用抽样的方法来尽可能达到“实时”,但是用头部20个数据包,那么老鼠流会爆炸)
我们现在分析的流量是在实验室去噪音后的流量,但在现实世界中,流量是复杂的、不断变化的。此外,网络管理员需要实时检测异常流量,并及时对其进行阻塞。因此,我们希望在未来的实验中能够直接分析真实世界的流量并实现实时检测。
为了实现实时检测,最关键的步骤是找到可以支持它的流量特征。 在本文概述的功能中,只有累积数据包长度功能几乎不能支持实时检测,而其他功能则需要等待所有流负载完成后才能提取。 因此,我们需要进行更多的研究来解决这个问题。
特征压缩
尽管我们从大量的功能集中提取了有意义的特征,但是这些特征仍然存在信息重叠或贡献不大的问题。 因此,主要的挑战是特征压缩。 我们期待在保证精度的前提下找到有效的算法以最小化特征维,从而减少流量分类的存储和计算开销。
主成分分析(PCA)是减少维数的统计方法。 它还对流量特征压缩有影响[15]。 然而,该算法对数据的缩放敏感,并且对于如何最佳地缩放数据以获得最佳结果尚无共识。 结果,使用PCA进行特征压缩通常会导致分类精度下降。 探索一种压缩算法,将分类精度的损失降到最低,甚至使其成为无损的,从而使流量分类的研究更加有效和轻便,这一点至关重要。
W. Cui et al., “Revisiting Assumptions for Website Fingerprinting Attacks,” Proc. 2019 ACM Asia Conf. Computer and Commun. Security, ser. Asia CCS ’19, 2019, pp. 328–339.
这篇倒是可以看看。
在本文中,我们提出了一种系统的方法来优化特征选择,以进行有效的加密流量分类。 我们首先介绍加密流量分类研究的概述。 接下来,我们总结加密流量的特征集,并说明如何为不同的数据集选择这些特征,包括特征预处理,特征评估和特征组合。 然后我们展示了实验性能并证明了我们的特征选择方案在加密流量分类中具有通用性。 我们还将讨论交通分类领域的挑战和未来方向。
对我的启发&我认为本文不足的
太水了,水文,自己的方法很简单,也没有提一些深度学习的最新进展,关于如何实时也没有提一些近期工作。