DataCon加密流量总结
抓包工具人:桃同学、Ga同学、灰同学
赛事简介:https://datacon.qianxin.com/competitions/16/introduction
数据介绍
赛事数据集:https://datacon.qianxin.com/opendata/maliciousstream
本数据集源自于2020年2月~6月收集的恶意软件与正常软件,经奇安信技术研究院天穹沙箱运行并采集其产生的流量筛选生成。本数据集定义的恶意流量为恶意软件(均为exe类型)产生的加密流量,白流量为正常软件(均为exe类型)产生的加密流量。流量内容为443端口产生的TLS/SSL数据包。
训练集规模为6000,其中黑样本为3000,白样本为3000。测试集规模为4000,其中黑样本为2000,白样本为2000。
训练集中的黑样本为2020年2月~2020年5月捕获的恶意软件加密流量,测试集中的黑样本为2020年6月捕获的恶意软件加密流量。所有白样本均为2020年捕获的正常软件加密流量。
我们的理解:比赛数据为标记数据,由于是加密流量,所以无法使用DPI或者直接使用端口的方式,可以参考之前的流量个人总结,考虑提取特征使用机器学习的方式或者直接使用深度学习的方式。
解题思路
在真实环境下,恶意流量占正常流量的极小一部分,在本次赛事中皆为1:1的比例,所以不需要做数据增强等手段。
在一周内,我们总共采用3种模型进行试验,分别是投票,stacking和深度学习的方式,由于比赛时间有限,最终提交版本为黑名单+投票的方式,下面依次介绍思路。
数据处理
我们通过@灰同学提供的统计流特征代码提取了如下特征:

头部特征+统计特征共计76维,由于比赛中数据的ip是随机化的,所以初次尝试时排除了源ip和目的ip。
在数据分析过程中,我们发现黑样本的服务端 IP 地址很容易复现,我们认为虽然经过hash随机化,但相同来源的恶意软件的服务端IP地址是相同的,所以手动构建了黑名单进行过滤,这一点与冠军方案类似,清华的方法是使用了一个朴素贝叶斯进行处理,而我们在经过数据流特征放入分类器之前先经过了一层黑名单过滤,简单粗暴。
除了传统的统计特征之外,我们还是用了TLS数据中提取的特征,主要包括:密码套件、支持的扩展、公钥长度、服务器选定的密码套件等,由于比赛时间有限,我们并没有做成哈希表或者one-hot的形式,而是简单的提取其中的字段值。
这部分是使用的scapy扩展进行提取,有两种安装方式,一种是安装完整的scapy库,命令如下:
1 | pip install --pre scapy[complete] |
另一种是给scapy安装第三方插件,参考如下:
第二种方式安装较为繁琐,需要修改代码,不推荐。提取的SSL/TLS特征如下:
1 | ###[ SSL/TLS ]### |
除了上述提到的特征之外,我们还想到了TLS/SSL证书特征,但遗憾的是,由于时间有限(写代码太弱小),没有进一步提取,在冠军方案中,对此特征分解为0/1 特征:是否自签名、是否过期、版本号、证书有效期、公钥长度。
投票机制
我们最终采用投票机制进行分类,使用5个强分类器对提取的流特征和tls特征进行分类。采用的强分类器分别是:LightGBM、RandomForest、GBDT、ExtraTrees、XGBOOST,实际上进行测试的分类器不少于10个,所有分类器都是使用sklearn所实现。
使用投票的好处在于使分类的结果更加稳定,当我们使用单个分类器时,单独用流的特征,分数会在61-67之间波动,而使用投票机制之后,分数会相对稳定。
stacking
在kaggle比赛中,stacking是比较常用的方式,其可解释性较差,简而言之为用第一层的强分类器的输出作为一个中间结果,通过第二层的弱分类器来预测/分类标签,弱分类器是为了防止过拟合。个人认为这是一种类似于神经网络的结构,参见下图。
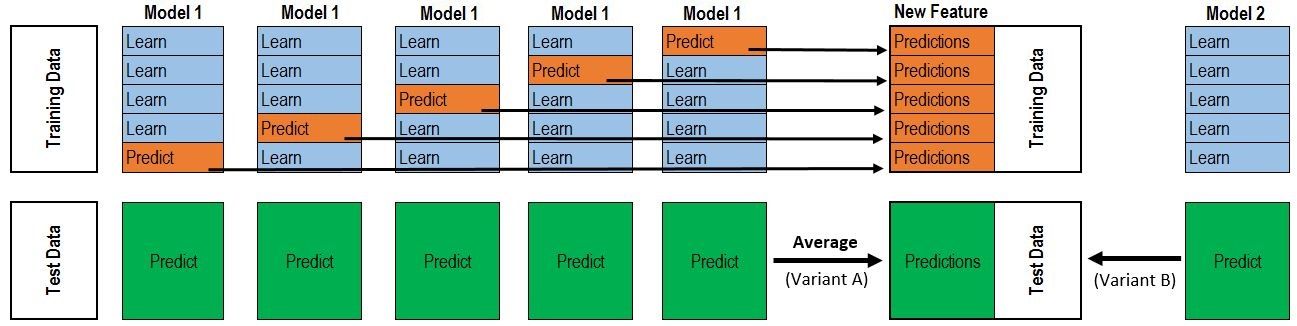
对于过程的详解可以参见:Kaggle机器学习之模型融合(stacking)心得 - 龙哥的文章 - 知乎 https://zhuanlan.zhihu.com/p/26890738
核心代码如下:
1 | # 第一级,重构特征当做第二级的训练集 |
深度学习
这一部分由@Ga同学完成,主要思路为使用CNN对包的数据部分当成句子序列来分类,直接把数据包转换为16进制的无意义字符进行处理。
用深度学习的方式进行流量识别是目前学术常用的做法,最常见的是采用包长序列的方式,比如对抗组的论文FS-Net: A Flow Sequence Network For Encrypted Traffic Classification。
在比赛中,考虑到深度学习的训练和调参需要一定的时间,并且比赛提供GPU的环境,我们没有在这个方向深挖,仅仅只是进行了初步的尝试。
反思和不足
在比赛前一半的时间我们采用的是通过pcap包进行判断,因为赛事所给的pcap白与黑的比例是1:1,而pcap文件中白流要多于黑流,我们陷入一个错误的思维是认为黑的pcap中仍然有不少白流,所以不能直接通过流来进行训练,然而实 测是流的效果更好。
虽然我们最后使用超过80维的特征,但数据的处理过于粗糙,参考马泽宇等同学的方式使用方差来过滤一些特征进行降为会更好,实际上通过特征选择删除冗余特征是很有必要的一步。
采用分类器直接对所有特征进行判断的方式过于粗暴,冠军方案对不同类型的特征分为不同的级别更加优雅。
有部分特征没有提取到,比如证书相关的特征等。
(哀嚎一句…自己太菜了)
第一名的方法简介
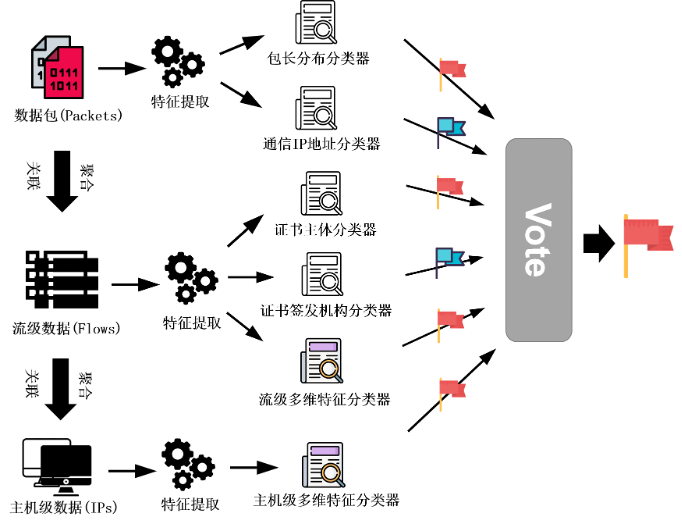
来自清华大学HawkEye战队https://datacon.qianxin.com/blog/archives/122
我们所采用的检测方法的总体结构是让多个分别利用不同的异构特征训练而成的分类器进行多数 投票 (Majority Voting) 的方式来获取最终的判定结果。由于我们所采用的多种特征是异构数据, 且具有不同的组织特点,我们并没有直接采用将这些特征统一编码并输入到集成学习分类器中 的常规方式,而是针对各个特征的特点分别构建对应的分类器,并利用他们的分类结果进行投 票,最终取得多数票的分类结果被定为最终的分类结果。参与投票的多个模型中部分使用了多 维特征综合分析,另一部分使用经过分析后黑白样本区分较大的、置信度较高的单维特征对多 维特征中的潜在的过拟合和判断错误进行消解。同时,我们考虑到了数据包级、流级、主机级 多维度的行为建模,将不同层次的数据进行聚合分析,提升对于黑白样本建模的准确度。下图展示了方案的整体流程。