本文解决的什么问题
few-shot classification:小样本分类问题
问题介绍
Few-shot classification需要在每个类别的标注样本很少的情况下进行分类,甚至需要对训练过程中没有出现的类别进行分类。
在标注样本很少的情况下训练分类器,很容易导致过拟合。
Few-shot Learning 是 Meta Learning 在监督学习领域的应用。Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。
形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 CK 个数据中学会如何区分这 C 个类别,*这样的任务被称为 C-way K-shot 问题。
训练过程中,每次训练(episode)都会采样得到不同 meta-task,所以总体来看,训练包含了不同的类别组合,这种机制使得模型学会不同 meta-task 中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉 meta-task 中 task 相关部分。通过这种学习机制学到的模型,在面对新的未见过的 meta-task 时,也能较好地进行分类。
前人的工作
Vinyals(matching networks)
Vinyals提出的matching networks(匹配网络),在标记的样本集(支持集)的embedding中使用attention来预测未标记样点(查询集)的类别。匹配网络可以理解为在embedding空间中的加权最近邻分类器。
值得注意的是,该模型利用了在训练期间被称为episodes 的mini-batches(抽样),每个episodes旨在通过对类别以及数据点进行二次采样来模仿few-shot任务。
Ravi and Larochelle
Ravi和Larochelle也是采用的这种episodes式的训练思想,并提出了一种meta-learning方法来进行小样本学习。
他们的方式是,给定episode训练一个LSTM对分类器进行更新,以便很好的推广到测试集。也就是说,LSTM meta-learner不是对于多个episode训练一个单独的分类器,而是为每一个episode训练一个定制的分类器。
这段没读懂,意思是每个分类来了之后对分类器进行二次训练来更新
与直接训练一个多分类的分类器的不同么
本文的思想
prototypical networks
prototypical networks的思想是每一个类别的所有点embedding会围绕一个原型聚集。由于样本有限,分类器会有一个归纳偏差 (inductive bias)。
做法是将每一个类别映射到非线性空间embedding,求其均值作为原型,分类的时候查询最近的原型点即可。
该方法还可以用来解决zero-shot学习,该任务每个类别都有meta-data,meta-data对类进行了高级描述,而非少数带标签的示例。因此,可以将元数据嵌入到共享空间中,以用作每个类的原型。
##prototypical networks模型
符号
共N个样本每个点为(Xi, yi),其中Xi是一个D-dimensional的向量,yi是一个数字类型的标记类别,共K类,Sk表示属于第K类。
模型
通过embedding函数 ***fΦ***(参数Φ),将Xi从D-dimensional的特征映射到M-dimensional的空间中,再进行求均值得到原型:
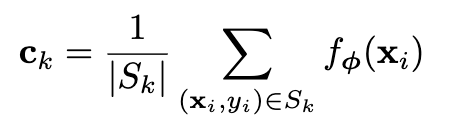
通过一个softmax对查询点x进行分类,x 属于类别 k 的概率为:
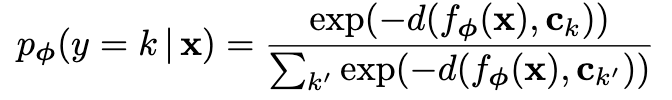
其中 d() 是距离函数,计算样本点 x 到原型点的距离,取相反数的原因是相距最小的原型最有可能使这个样本点对应的类。
通过随机梯度下降最小化正确类别k的负对数概率:
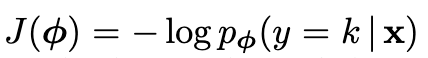
最小化正确类别的负对数概率等价于最大化 pϕ(y=k|x) ,其中x属于类k。
Training episodes是从训练集所有类别种抽取的类别(就是抽取NC个类别)。
support set是episodes每个类别抽取的样例的子集,support set以外的部分进行抽样得到query points。

这段伪代码的几个注意点
- 这是一个episode的训练,而非整个训练过程
- 2-way 5-shot指的是N
c=2,Qk - 小k代表的是类k,K是整个训练数据有K个类别
- Compute prototype from support examples 中的N
C应该为NS - Update loss步的时候,后面的式子可化为x属于c
k类的概率(前面提到的)- 这样的效果是叠加每个类的 query set 节点的损失作为损失函数
进一步分析
原型网络可以理解为混合密度估计
当距离函数 d 为regular Bregman divergences时,本文提到的原型网络的算法相当于对具有指数族密度的支持集进行混合密度估计。
Bregman divergence包括了常见了“距离”定义,如均方欧式距离Mahalanobis距离。根据Bregman divergence的性质,在support set上利用向量均值求得得值是最优的聚类中心。
这一点作者没有直接证明,主要是通过[4]间接说明
[4] Arindam Banerjee, Srujana Merugu, Inderjit S Dhillon, and Joydeep Ghosh. Clustering with bregman divergences. Journal of machine learning research, 6(Oct):1705–1749, 2005.
理解为线性模型
在应用欧式距离 d(z, z’) = ||z - z’||^2^ 时,上文的softmax相当于有特定参数的线性模型,可以得到:
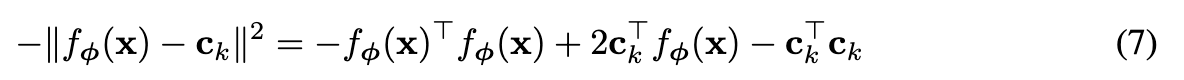
由于 k 是常数,可以进一步化为如下线性模型:
本文的工作表明,使用欧式距离虽然简单,相当于线性模型,但是有效。作者猜测所需要的非线性因素都在embedding函数中学到了。
与Matching Networks比较
原型网络Prototypical networks和匹配网络Matching networks在few-shot(少样本)的场景下是不同的,但是在one-shot(单一样本)的场景下是等价的。
在one-shot的场景下,原型点就是样本点 ck = xk 。
Matching networks提出了许多扩展,包括将支持点和查询点的嵌入解耦合,以及使用考虑了每个episode中特定点的second-level, fully-conditional embedding(FCE)。 这些同样可以合并到原型网络中,但是它们增加了参数的数量,并且FCE使用双向LSTM对支持集施加了arbitrary ordering。
设计选择
Distance metric
相比余弦距离,本文发现使用平方欧几里德距离可以极大地改善原型网络和匹配网络的结果,作者推测这是因为余弦距离不是Bregman散度,因此与混合密度估计不等价。
Episode composition
Vinyals(匹配网络)和Ravi等人的方法是直接选择Nc个类作为episode,每个类直接选择NS个样本的支持集。
作者发现,在测试集的时候选择更大的Nc和NS会有更好的效果,并且作者发现训练和测试采用相同数量?的NS会更好。
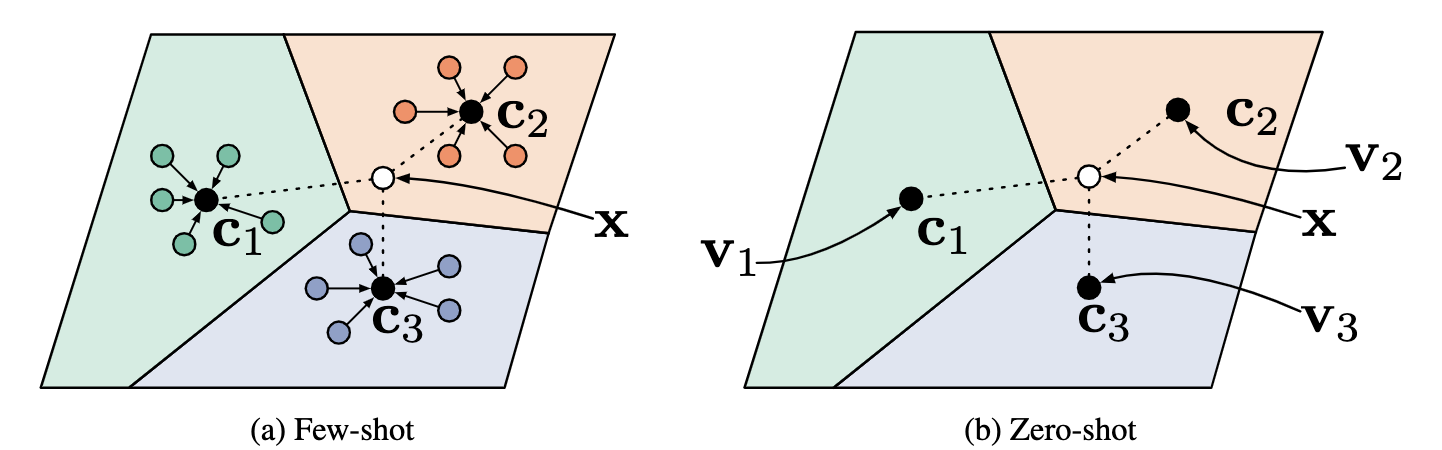
Zero-Shot零样本学习
Zero-shot learning与fewer -shot learning的不同之处是,没有可以用于训练的支持集,而是给每个类一个元数据向量vk,这个元数据可以事先定义或者通过学习得到。
将原型网络应用于Zero-shot只需要将元数据作为原型即可。
由于原数据的向量和query point通常来自不同的作用域,作者发现可用固定原型embedding的长度为单位长度,对query embedding不限制。
实验
对于few-shot learning,在Omniglot和miniImageNet version of ILSVRC-2012上进行实验。
对于zero-shot learning,在2011 version of the Caltech UCSD bird dataset (CUB-200 2011) 上进行实验。
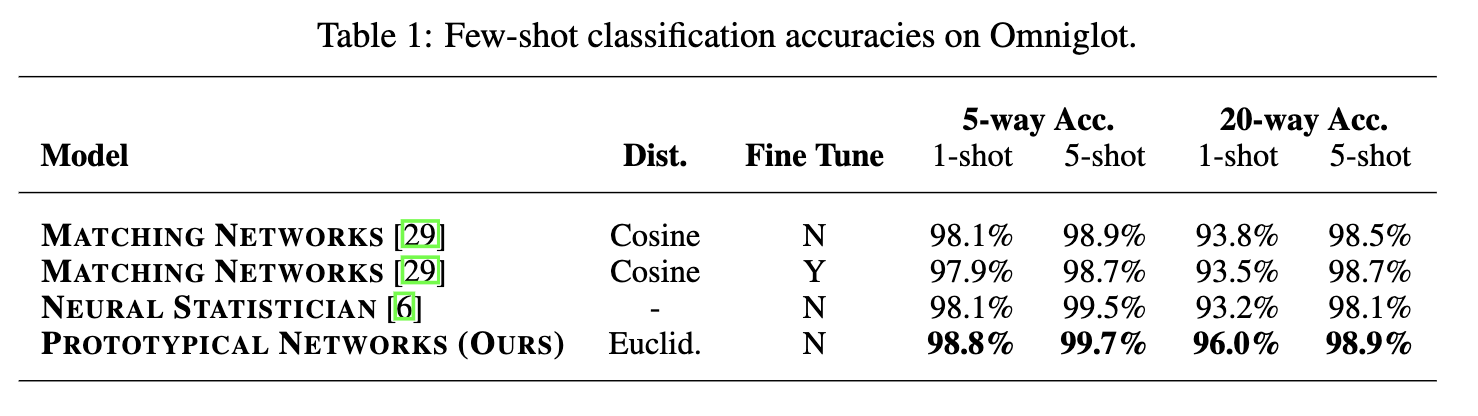
Omniglot Few-shot Classification
Omniglot 数据集包含来自 50不同字母(语言)的1623 个不同手写字符。每一个字符都是由 20个不同的人通过亚马逊的 Mechanical Turk 在线绘制的。

作者参照Vinyals等人的步骤,将灰度图像调整为28 ✖️ 28,并将图像多次旋转90度来增加字符类别。使用1200个字符及其旋转来训练(总共4800个类),剩下的类别(包括旋转后的)用于测试。
embedding architecture也是参考的Vinyals等人的结构,由四个卷积块组成,每个块包括一个64滤波器3 ✖️ 3卷积,batch normalization layer ,一个ReLU非线性和一个2 ✖️ 2最大池化层。当应用于28 ✖️ 28的Omniglot图像时,此体系结构将产生64维输出空间。
所有的模型都通过使用Adam的SGD进行训练。 使用10^-3^的初始学习率,每2000个episode将学习率减半。 除了batch normalization外,不使用任何正则化。
作者在1-shot和5-shot场景下进行训练原型网络,每个episode包含60个类别,其中每个类包含5个query point。
作者发现,将training-shot与test-shot相匹配是有利的,并且用于训练的episode包含更多的类别也会使结果更好。
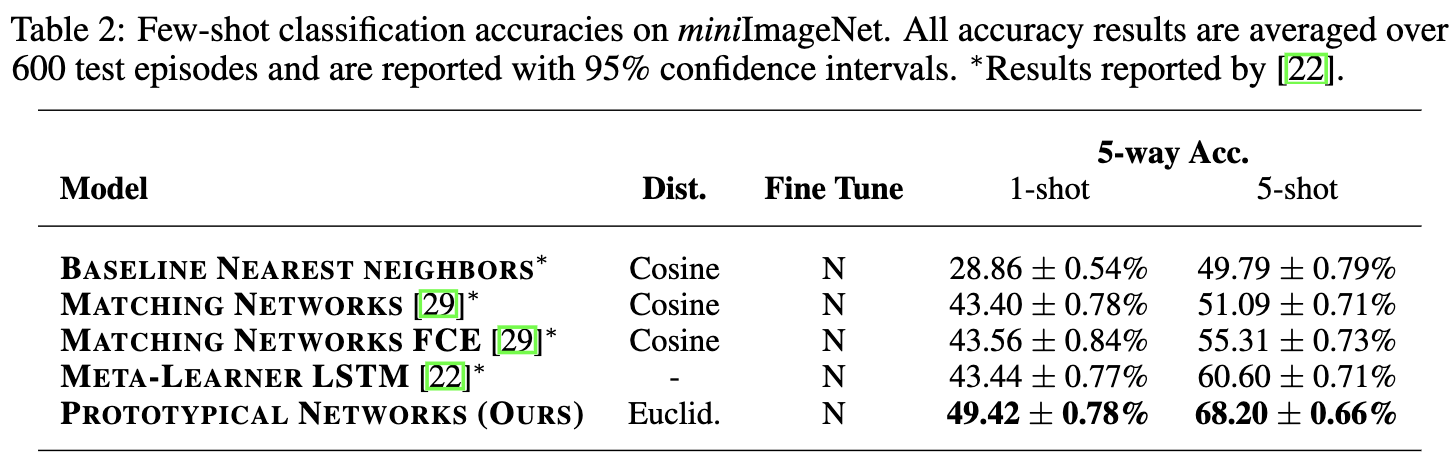
miniImageNet Few-shot Classification
miniImageNet数据集来源于ILSVRC-12数据集,Vinyals等人在match networks提出并使用。本文参考了此前的sota,Ravi和Larochelle等人的做法,每个分割由100个类别,其中64个类别用于训练,16个类别用于验证,20个类别用于测试。
embedding函数使用和Omniglot相同的结构,由于图像尺寸的增加,输出空间是1600维,学习率也是和之前使用的一样。
对于1-shot分类,使用30-way episodes,对于5-shot分类,使用20-way episodes。
和之前的几个工作相比,效果最好。
作者进一步分析了距离函数和每个episode的训练类别数对结果的影响。
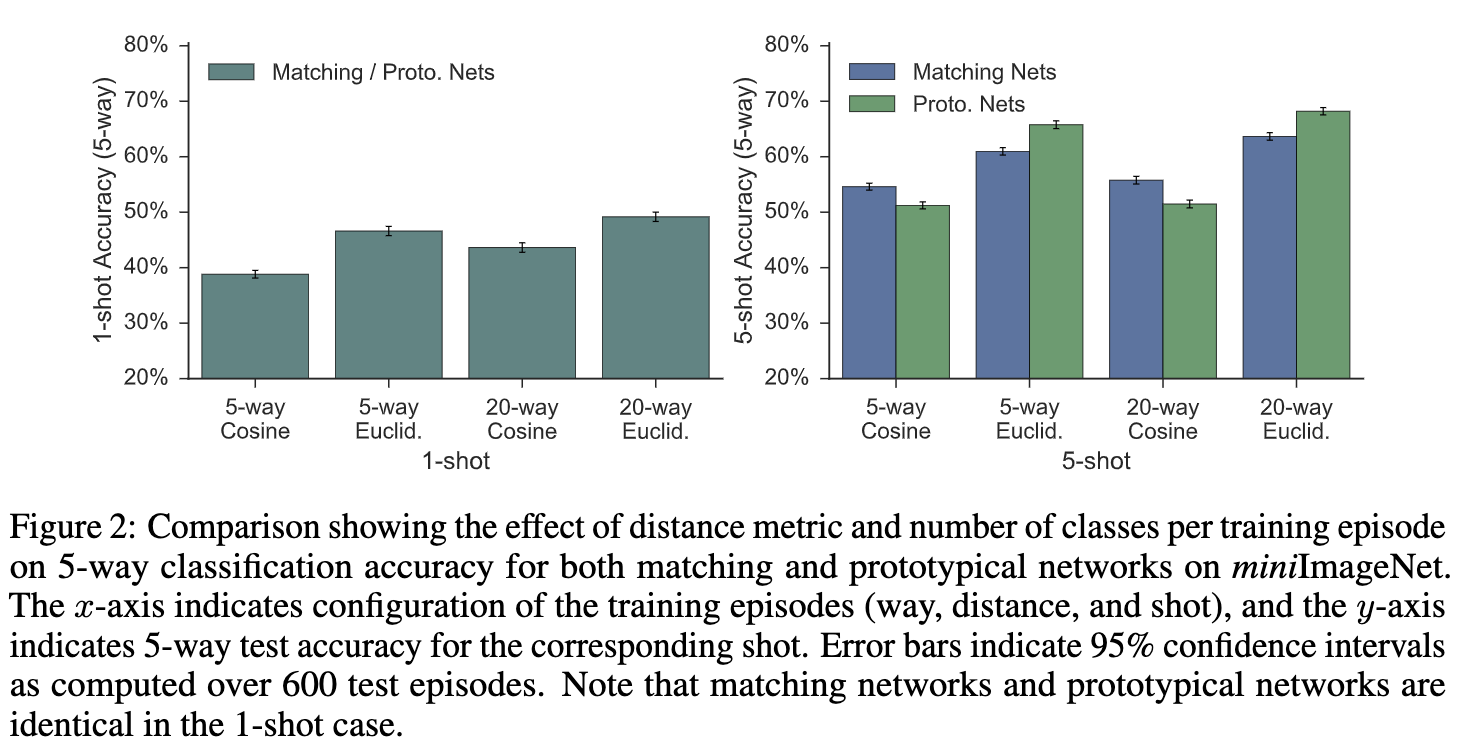
结果显示,均方欧式距离比余弦距离更好,每个episode中的类别更多结果也会更好。
我的理解:
5-way指的就是每个episode5个类别,1-shot就是episode中的类别只有一个实例。
那这句话是什么意思呢?
with 15 query points per class per episode.
查阅了一些资料后终于理解,5-shot指的是支持集有5个实例,query set另说。
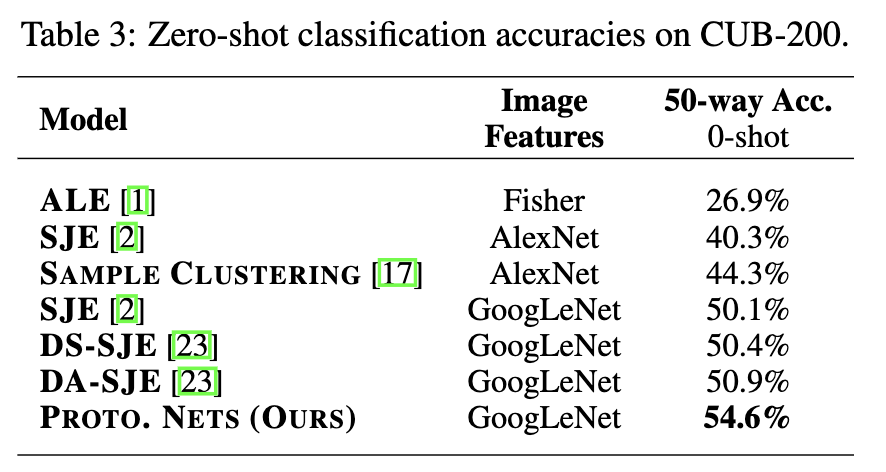
CUB Zero-shot Classification
Caltech-UCSDBirds(CUB)20数据集包含11788张图片,共200种类的鸟类。作者将所有类别分为100个类别作为训练,50个类别作为验证,50个类别作为测试。
采用GoogLeNet对中,左上,右上,左下和右下共提取了1024维的特征,测试时仅使用原始图像的中间部分。
模型对鸟类的种类、颜色、羽毛等属性编码得到312维度的元向量。
在1024维图像特征和312维属性向量的基础上学习了一个简单的线性映射,以生成1024维输出空间。
训练episode的类别为50,每个类别的查询点为10个。
参考
在阅读论文的时候,参考了一些解读
https://zhuanlan.zhihu.com/p/54340045
https://blog.csdn.net/weixin_37589575/article/details/92768668
[阿里巴巴-小样本学习(Few-shot Learning)综述][https://zhuanlan.zhihu.com/p/61215293]
摘自知乎覃含章的回答:
如何理解Bregman divergence
通俗来说,什么是Bregman divergence,就是如果你抽象地定义一种在特定空间里两个点之间的“距离”,然后在这些点满足任意的概率分布的情况下,这些点的平均值点(mean point)一定是空间中距离这些点的平均距离最小的点(这是一个很正常的我们希望对“距离”的定义吧)。
令人吃惊的是,这个条件是当且仅当的,也就是说,反过来说,给定一个 上的divergence函数
,如果满足对所有
上的随机变量(random variable)
,
都是
唯一的minimizer,那么d一定是一个Bregman divergence。我们一般所以也说Bregman divergence是exhastive(穷尽)的,即它包含了一切对“正常距离”的定义。
本文提出的的Prototypical Networks(P-net)思想与match network(M-net)十分相似,但也有几个不同点:1.使用了不同的距离度量方式,M-net中是cosine度量距离,P-net中使用的是属于布雷格曼散度(详见论文)的欧几里得距离。2.二者在few-shot的场景下不同,在one-shot时等价(one-shot时取得的原型就是支持集中的样本)3.网络结构上,P-net相比M-net将编码层和分类层合一,参数更少,训练更加方便。