近来报名了CCCC网络技术挑战赛,奈何参加得太晚,距离资格赛只有几天的时间,资格赛是刷题,就想着能否将题库爬下来呢?
参考了了Jack Cui大佬的教程,说做就做。
爬虫简介
URL
爬虫其实就是模拟浏览器对服务器发送请求,得到目标服务器返回的文字,视频,图片等等。
而访问目标服务器,则是通过URL
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
就像这样
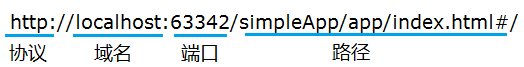
- protocol:第一部分就是协议,例如百度使用的就是https协议;
- hostname[:port]:第二部分就是主机名(还有端口号为可选参数),一般网站默认的端口号为80,例如百度的主机名就是www.baidu.com,这个就是服务器的地址;
- path:第三部分就是主机资源的具体地址,如目录和文件名等。
有时,还需要一些条件,这个条件就是 [;parameters][?query]#fragment
要理解通过URL访问服务器这一过程,可以参考《网络是怎样连接的这一本书》
检查F12
我们需要爬的资源往往并非输入网址的URL,一个网页包含了多个URI,这些URI可以是图片,下一个页面等等。
一个请求消息只能写一个URI,一个网页往往包含了多个URI,需要进行多次请求。
要获取我们想要的URI,需要用“检查”,右键网页-检查,或者F12都可。
通过Element我们可以看到网页源代码,并且可以对应代码与网页的位置。
通过Network我们可以看到每一次的请求和返回结果。
爬虫的步骤
爬虫大致可以分为三个步骤:
- 发起请求
- 解析数据
- 保存数据
其中,发起请求比较常用的事Python的request库和urllib库,前者是第三方库,后者是python自带的。
request官网教程
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
request简单使用,发送一个GET请求,得到html文件
1 | import request |
解析数据可以用很多方式,xpath、BeautifulSoup、正则表达式等,最常用的是BeautifulSoup。
Beautifulsoup官方教程
BeautifulSoup简单使用
1 | import request |
模拟登录
很多网页需要账号密码登陆后才可爬取,对于需要登陆的网页爬虫,有以下三种方式:
- POST请求,填写账号密码
- 添加Cookie,优先采用
- Selenium模拟登录,和用户操作很类似
这里比较常用的是添加Cookie,我们可以手动访问网页在“检查-Network-Header”中找到登录后的Cookie复制下来,在request请求的时候添加header即可。
关于cookie,Crossin的编程教室这篇文讲得不错,并且还提到了面试的问法。
也可以用POST或者Selenium模拟登录后获取Cookie。
常见的反爬手段
不允许右键检查
比如我喜欢的忧郁的Loli网站,可以用F12打开检查。
有的网站禁止了F12,也可以将鼠标移到浏览器地址栏,然后再按F12。
可以采用view-souce: URL
view-source: https://beats0.github.io/www.mygalgame.com/
通过header字段反爬
网页可能通过User-Agent、referer、X-Requested-With等反爬,这些都可以在request里添加header处理,只需要在“检查-Network”中查看真实请求URI的header是什么即可。
通过IP地址反爬
同一个IP大量请求了服务器时,可能别识别。
可以通过IP池,采用免费的代理ip或者购买ip。
通过验证码反爬
可以通过OCR或者机器学习识别。
也可以调用一些API,比如打码平台识别。
EP4资格赛题库爬虫
分析URI
登录C4竞赛答题网站,分析想要得到的URI。
根绝观察可以发现,切换题目的时候,页面的URL并没有改变。
观察点击“下一题”和“提交的按钮”,在Network中可以看到请求的URI和header,其中“提交”时,出现了一个answer请求包,是一个post请求,查看post请求的发送的data,可以看到分别需要提交question_id,answers,cloud_platform_id,显然question_id是需要根据题目改变的。
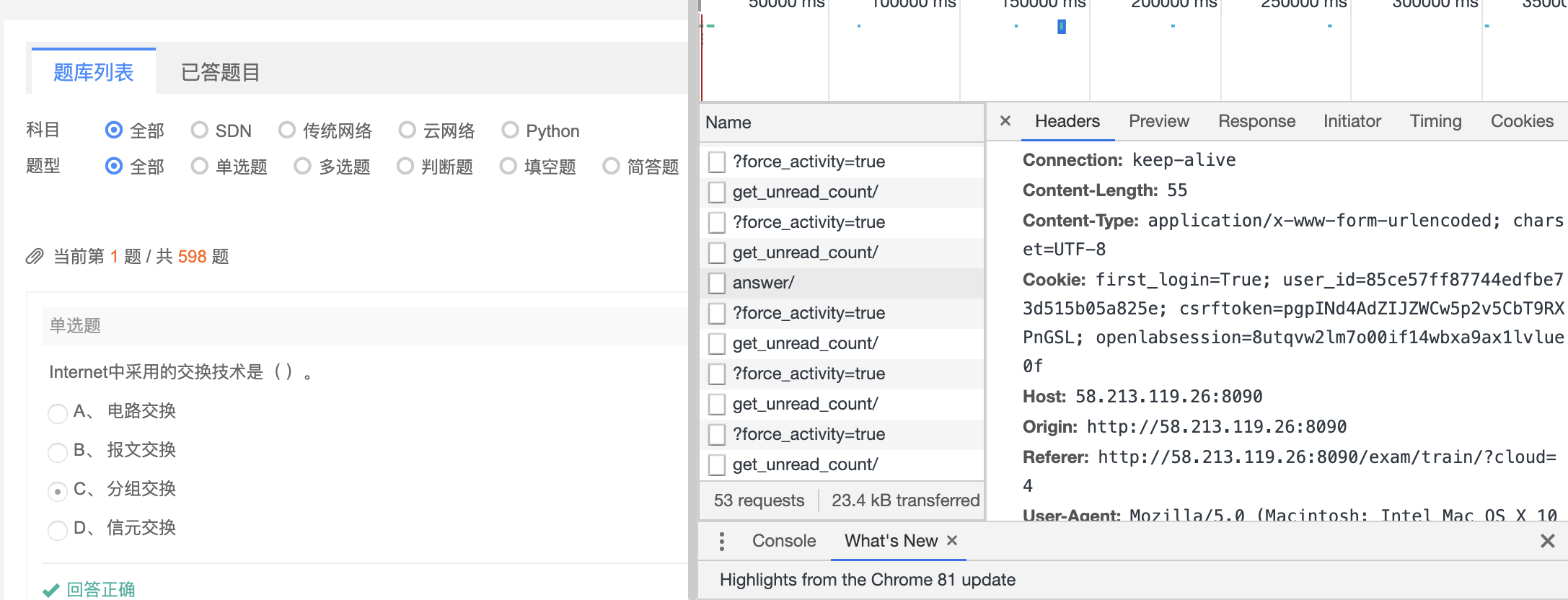

通过“Network-Preview”看到正是想要的。
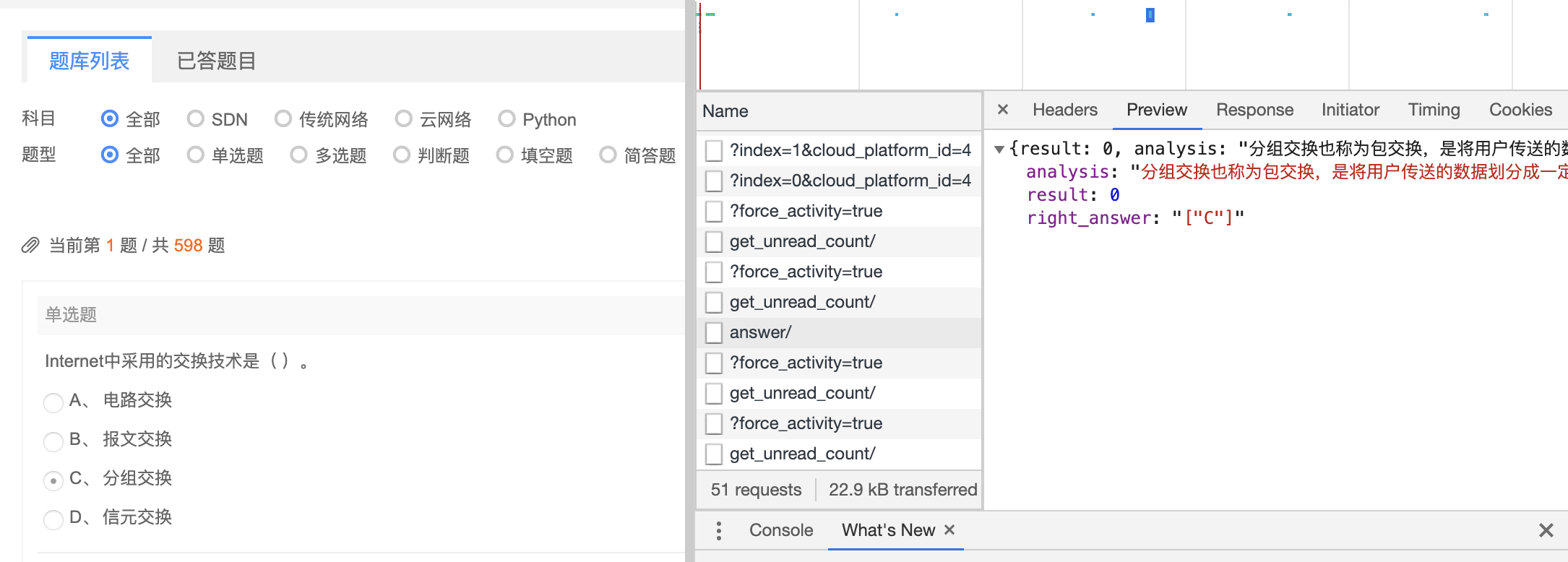
点击“下一题”时,出现了下一个页面的请求包,在“Network-Response”可以看到每次点击下一题返回的html,在其中观察得到question_id和对应的题目。
基于此,写入代码如下:
1 | import requests |
这里需要注意区分选择题和判断题,我用了一个很naive的方法, 即判断清洗后的文字是否包含“是”,这样的做饭总感觉不太优雅。
文字解析问题
在调用BeautifulSoup的text返回文字的时候,总有很多标签去不掉,最开始采用正则表达式的方式进行处理,但是不完善的匹配规则会去掉很多需要的文字。
最后选择w3lib库。
1 | from w3lib import html |
超时问题
request请求有时会有超时的问题,可以看[这个][https://www.cnblogs.com/gl1573/p/10129382.html]
可以参考[这个博客][https://blog.csdn.net/Homewm/article/details/92127567]
主要有以下做法
- 使用eventlet,但是不适用于多进程
- 使用signal设置装饰器
本文主要参考Jack Cui大佬的[教程][https://github.com/Jack-Cherish/python-spider/tree/master/2020]
在寻找资料时还发现了以下不错的资源
[Python网络爬虫实战][https://www.jianshu.com/p/3a038d070eb1]