介绍
本文是关于加密流量识别的一篇概述。
难点:加密和端口混淆。
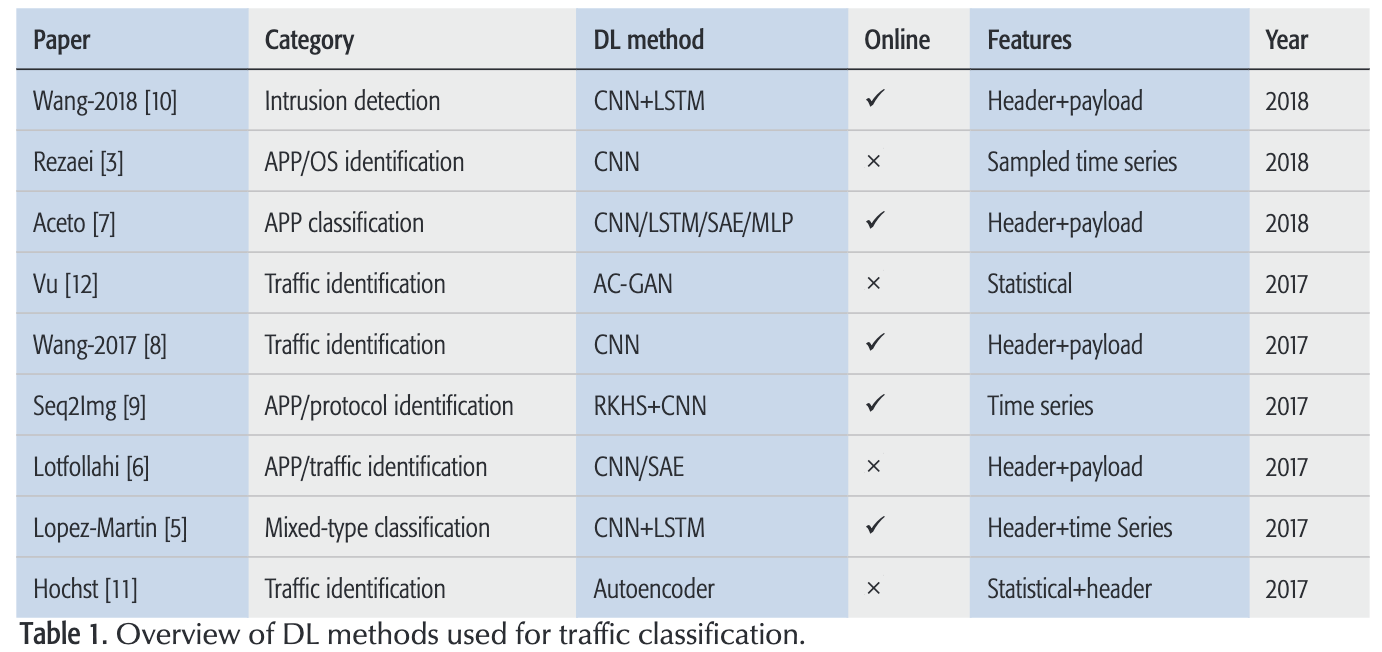
常用的方式
端口号
- 但是很多应用程序会用众所周知的端口号来掩饰流量
- 或者避免使用标准的注册端口号
- 常与其他特征一起使用
数据包检测DPI
- 即根据数据包的模型或者关键字
- 仅适用于未加密的流量
- 计算开销较大
统计特征/时序特征 + 机器学习
- 能针对加密和非加密的流量
- 常用ML方法:随机森林,KNN等
- 需要设计特征
深度学习
- 无需设计特征
- 需要足够的标记数据
以下是流量分类的通常的步骤:
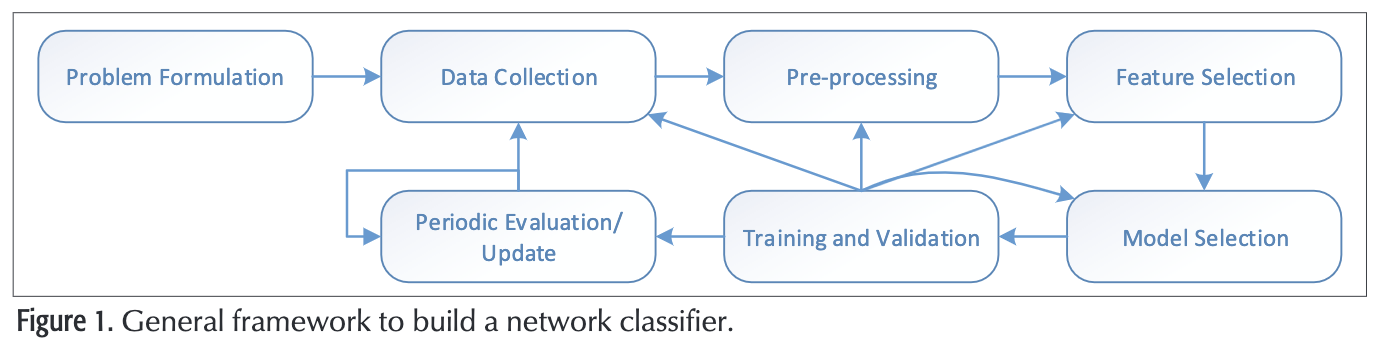
定义流量分类问题
建立流量分类器的第一步是明确定义分类目标。 典型目标包括QoS设置,资源使用计划,计费系统定制以及入侵/恶意软件检测。
可以根据以下内容对流量进行分类:
- 协议:UDP或者HTTP
- 应用:Skype或微信
- 流量行为:浏览或下载
- 网站
- 用户行为:发表评论或者发送消息
- 操作系统
- 浏览器等等
目标是用相应的流量类别标记每个流。 流通常由5元组确定:源IP,目的IP,源端口,目标端口和协议。
此外,流量分类也可以分为两个子类:在线和离线。 在线分类通常是指需要尽快对流进行分类的情况,通常是在前几个数据包之内。 例如,对于QoS设置和路由,需要进行在线分类,因为分类输出直接影响当前流的决策。 对于其他应用程序,例如计费系统,可以采用离线分类。
数据搜集
目前用于流量分类的公开数据集很少,原因是一个数据集几乎不可能包含所有的流量类型,并且没有可以被广泛接受的流量收集方法以及标签方法,流量收集的方法也存在差异,在客户端和服务端不同位置收集的流量都会显著影响流量特征。
在实践中,研究人员经常收集特定于其分类目标的数据集,首先需要确定的是数据收集的位置,可能是客户端,服务器端,甚至是中间的任何位置,这回影响标签和模型的泛化能力。
数据收集需要考虑以下几个方面:
1.可靠的标签,期待值y(标签)的重要性不言而喻。对于非加密类型的流量,可以通过开源的DPI工具,如nDPI来为流量进行标签,这样的做法会使效果受到工具的制约。对于加密流量而言,在可控情形下,排除干扰流量的影响,从客户端是可以对流量进行标签的,尽管有着很多限制,但这是最常用的策略。
2.可用的特征。加密会报文字段不是文本格式。路由的不对称性可能使得只能捕获流的一个方向。客户端距离服务端的位置会影响时延特征。隧道流量会影响包长度特征。因此不同抓包点得到的数据训练得到的模型对于另一抓包点得到的数据分类效果不一定准确。
3.如何构建具有代表性的数据集,对于每一个类别的样本,数量要多而且需要具备多样性,来防止产生过拟合。 检测模型有效性的关键在于,能否在与来自训练集不同的设备和用户配置收集得到的测试集上达到好的分类效果。
数据预处理
数据清洗和预处理会影响分类的性能,使用深度学习的方法这一点尤为重要。数据包重传,重复的ack和无序的数据包可能会更改应用程序的流量模式。
R. Dubin et al., ”I Know What You Saw Last Minute —
Encrypted HTTP Adaptive Video Streaming Title Classification,” IEEE Trans. Info. Forensics and Security, vol. 12, Dec. 2017, pp. 3039–49. 这篇认为数据清洗有影响G. Aceto et al., ”Traffic Classification of Mobile Apps through
Multi-classification,” Proc. IEEE GLOBECOM, Dec. 2017, pp.
1–6. 这篇认为没有影响
对于采用整个流的统计特征可能受到无关数据包的影响更小一些。而采用前几个包进行分类的线上系统可能会受到更大的影响。
然而预处理由于计算复杂的原因,经常被忽略。
除了数据清洗之外,还需要对数据特征进行归一化,让所有输入特性都被缩放为[-1,+1](或[0,1])范围内。
特征选择
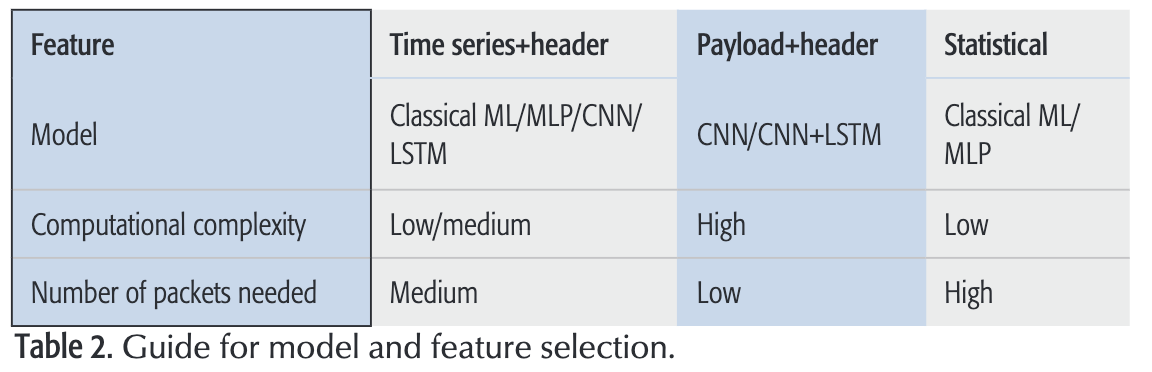
时序特征
时间序列特征包括包的长度、到达时间和包的方向。在很多研究中,前几个包的数据(不超过20个)就可以证明足够的准确。一组采样数据包的时间序列特征最近也被证明可以达到较好的精度。
头部特征Header
网络层和运输层中包含许多用户相关的信息,并且是未加密的。在深度学习方法之前,通常使用端口号,运输层协议,包长等特征来作为代表性特征。在最近,特别是基于深度学习方法而言,习惯使用整个数据包作为输入。注意:ip地址可以来确定流量类型,例如可以将使用Google的ip地址归类为google的应用程序。但是,由于CDN的广泛使用以及IP地址的动态分配,应该谨慎使用IP地址作为分类依据。
Header特征单独使用效果不好,往往和其他特征一起使用。
负载数据Payload Data
即使对于加密流量,也可以通过运输层以上的信息进行分类。例如有研究通过TLS1.2握手包中的纯文本数据得到了很高的准确率。
吐槽一下,这里竟然不附参考文献。
统计特征Statistical Features
统计特征通常通过整条数据流得出,例如平均包长,最大包长,最小包间时延等等。但是得到统计特征需要观测整条数据流或者这条流的绝大部分。因此仅仅适用于离线分类。对于应用分类,统计特征通常还会受到用户行为,操作模式以及网络条件的影响。所以,对于数据集收集的要求比较高。
兄弟组很喜欢这样做,做综述的时候把兄弟组的paper用到的数据特征整合一下
尽管同一流量的未加密版本和加密版本的时间序列和统计特性可能略有不同,但无论加密与否都可以使用它们。因此,在未加密的通信流上训练的模型也可以用于加密的通信流。
另一方面,负载数据和一些头信息(如IPsec加密的通信流的第4层信息)可能不存在纯文本形式。但是,在这些情况下,在握手过程中仍然有未加密的字段可用来进行分类。
深度学习模型
多层感知器MLP
由于流量分类的复杂性和低准确性,用得很少。
CNN
一些研究显示,用CNN对数据包的字节进行归一化,对比使用时间序列和统计特征的方法有明显的改进。
一些方法将时间序列数据转化为二维图像再采用CNN。
还有的研究使用半监督的方法,从带有大量未标记数据集的几个采样数据包中预测整个流的统计特征。 然后将权重转移到新模型中,并重新训练以仅使用少量标记样品进行应用分类。
RNN
有研究表示,混合模型再流量分类任务中,要优于单纯的LSTM或CNN模型。
GAN
GAN可用于处理网络流量分类中的数据集不平衡问题。处理不平衡数据集最常见和最简单的方法是通过复制小类的样本进行过采样,或者通过从主要类中删除一些样本进行欠采样。
据我所了解,GAN并没有生成新的数据,而更像是对于数据的一种增强,所以和欠采样蛮像的。
模型选择
特征的类别和维度会影响模型的选择,在数据量较少的时候,更适合用机器学习而非深度学习的方法进行分类。
时序特征+Header特征
因为时间序列特征不受加密的影响,故而被广泛使用。一些研究表示,通过前10-30个数据包或者从整条流中采样数据包都可以达到很好的分类效果。
负载特征+Header特征
在目前加密流量中,数据流前几个包含握手信息的数据包通常是未加密的,可以用来进行分类。由于负载Payload中有大量字节,输入维度比较高,使用CNN和LSTM能取得不错的效果。也可以将时序特征与这部分特征相结合,会稍微增加准确率。
统计特征
统计特征的输入维度通常很小,因为使用这种特征作为分类的论文很多事采用机器学习的方法,有部分采用MLP。尽管大部分研究通过整个数据流获取特征,但有研究表明计前10-180个数据包的特征,足够实现分类效果。
大多数应用程序的流量特征是在不停变化的,而很少有研究会关注定期评估或者如何对模型进行更新。
一种名为zero-day applications的流量类别是值得未来关注的。
未来可能的研究方向
未加密的流量已经研究得很透彻了,对于加密流量仍是一个值得研究的方向,下面介绍流量分类中仍未解决的问题。
针对更强的加密协议
更强加密协议比如QUIC和TLS1.3的流量分类较少。过去对TLS1.2的研究主要在握手过程中使用纯文本字段。 但是,随着TLS 1.3和QUIC中引入0-RTT连接,第一个数据包中只有几个字段保持未加密状态,因此尚不清楚它们是否足以满足分类要求。
多种标签
单个流可以包含多个类别标签。
通过流中间位置的数据包进行分类
流量中有90%是短期的流量,一些分类方法采用前几个数据包进行分类,这样在真实网络环境中会对大量的流量进行分析和存储,如果使用流中间的包进行分类,则可以只关注于elephant flow。
未知流量分类
对于未知的流量进行分类,需要模型主动去标记数据,强化学习是一个可以选择的方向,关于这部分,可以参考nlp的很多工作,对类别进行预测或者打新标签。
Robust Network Traffic Classification 2015
作者说这篇有提到这一点
迁移学习
即对一个类似任务训练的模型进行再训练,迁移到目标任务上。
针对网络流量分类,可以使用公开可用的数据集对模型进行预训练,该模型可以用更少的标记样本针对另一个流量分类任务进行进一步调整。
关于领域自适应,一个示例是使用在通信客户端捕获的数据集训练流量分类器模型,然后采用该模型对数据分布不同的网络核心处的流量进行分类。 另一个例子是基于领域自适应技术,定期重新训练模型以捕获特征不断变化的类的新模式的情况。
多任务学习
广泛应用于cv和nlp,但在网络流量分类还没有相关的研究。
想看的参考
S. Rezaei and X. Liu, ”How to Achieve High Classification Accuracy with Just a Few Labels: A Semisupervised Approach Using Sampled Packets,” 2018; arxiv.org/ abs/1812.09761, accessed Apr. 2019. 这篇对包进行采样然后再分类,文章还用了迁移的思想。下篇仔细读读。并且还对QUIC进行了分类。
如果可以用少样本这种采样方式的话,那可不可以结合16年nips那篇呢?
Network Traffic Classifier with Convolutional and Recurrent Neural Networks for Internet of Things 2017 这篇提出混合模型效果好于单纯的LSTM和CNN
HAST-IDS: Learning Hierarchical Spatial-Temporal Features Using Deep Neural Networks to Improve Intrusion Detection 2018
这篇也是结合了CNN和LSTM
A Deep Learning Based Method for Handling Imbalanced Problem in Network Traffic Classification 2017 这篇采用了GAN生成新数据,貌似再采用机器学习进行分类,我记得18年也有用GAN生成新数据的,可以对比一下
我的想法
之前看一篇文章进行了详细的分析,那么我可不可以分析流的长度对此的影响呢?分别是前5个包,前20个包,所有的包酱紫作为对比分析。
还可以拓展系统到实时和线下,实时的就用前几个包,然后数据清洗一下。
可以采用GAN生成新数据。
可以像19年那篇,借鉴迁移的思想。
感谢
不少文字来源于https://blog.csdn.net/weixin_41763134/article/details/104219211,感谢大佬