粗略DL自阅笔记——RNN
循环神经网络
为什么要用RNN?
对于传统的DNN而言,每个输入是相对孤立的,而在很多的任务中,例如nlp中的词性标注,上下文,单词之间是相互影响的,而RNN在处理序列信息方面有很大的优势,有很强的短期记忆能力。
RNN框架
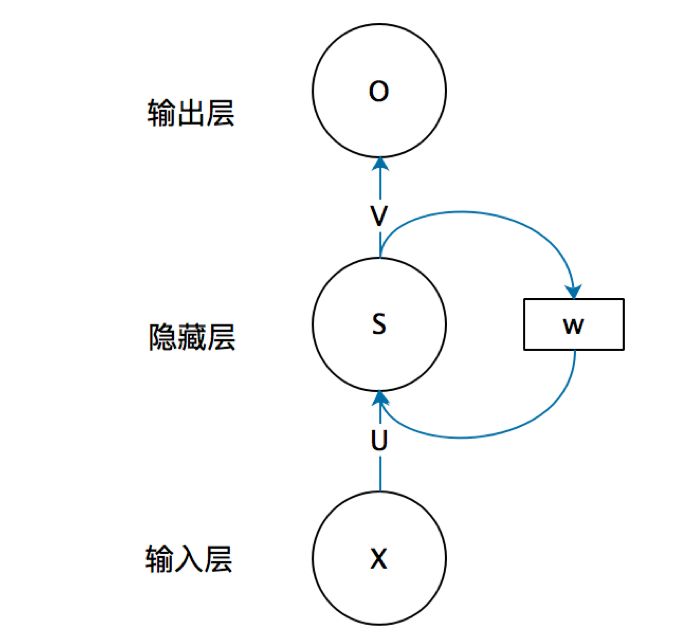
上图中的W及其连线去掉,可以视为一个全连接的神经网络,而输入层X和输出层O并非指的是一个神经元,而是可以形式多种多样,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵
展开来看
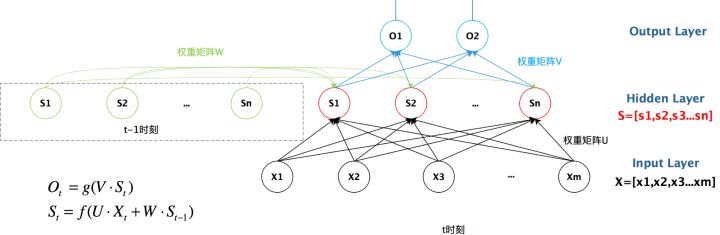
与DNN不同的是,RNN隐藏层状态st不仅仅取决于当前时刻的输入xt,还取决于上一时刻的隐藏层状态st-1
$$
z_t = Us_{t-1} + Wx_t + b
$$
$$
s_t = f(z_t)
$$
$$
O_t = g(V·S_t)
$$
其中zt为隐藏层输入,f(·)是非线性激活函数,U是状态-状态权重矩阵,W是状态-输入权重矩阵,b是偏置项
RNN的不同架构
根据任务的需要,可以采取一些不同的RNN架构
1 to N
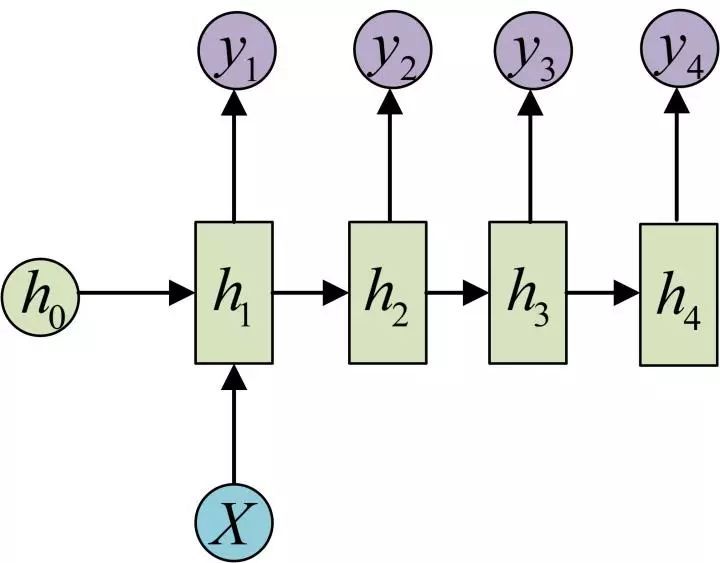
另一种1 to N
image caption等任务可以采用,输入图片特征得到描述文字
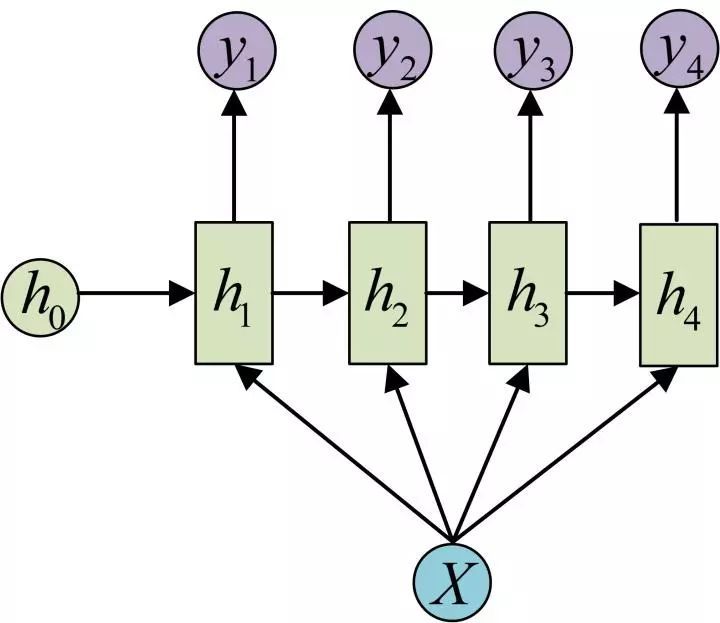
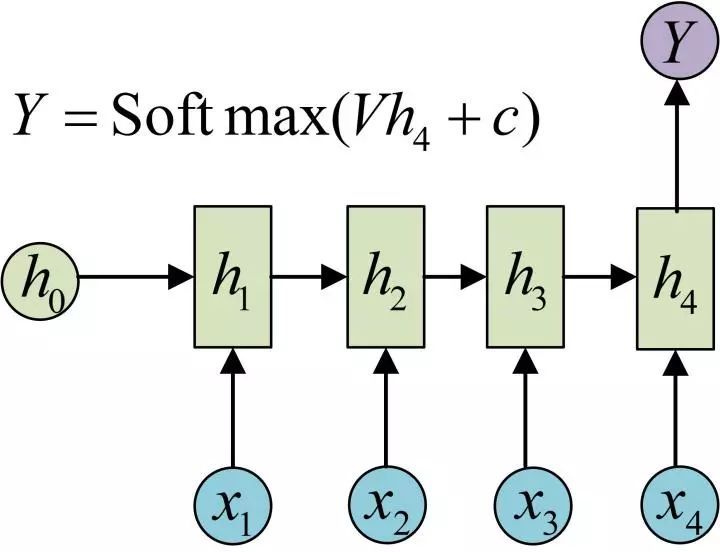
N to 1
适用于句子,文章的情感分析
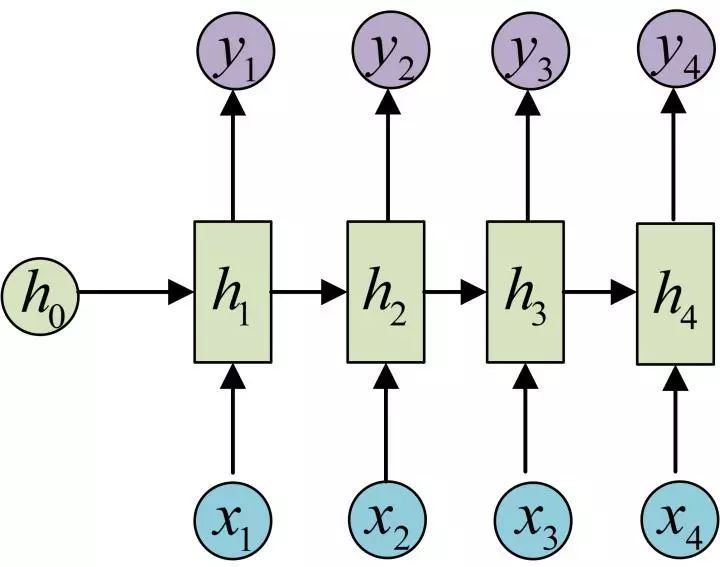
N to N
一些序列标注任务
股票预测,自动写诗可以采用
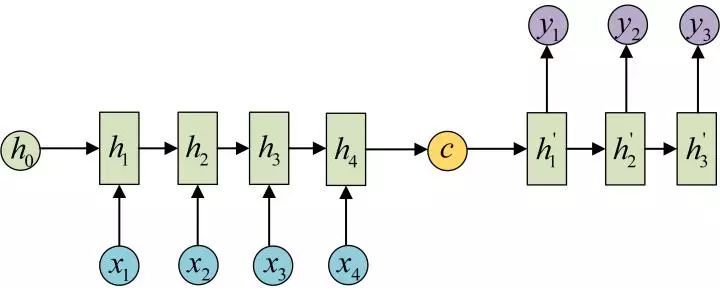
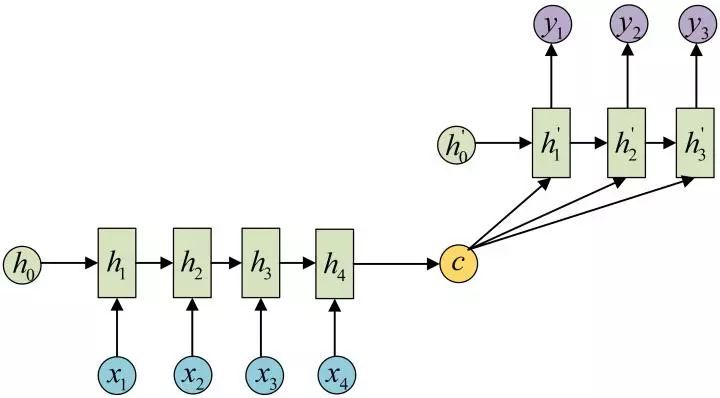
N to M
也被称之为Encoder-Decoder模型,Seq2Seq模型
使用于机器翻译,阅读理解等任务
注意这里其实h1, h2, h3, h4也是有输出的,只是你可以不用,而h1’等也是有输入的
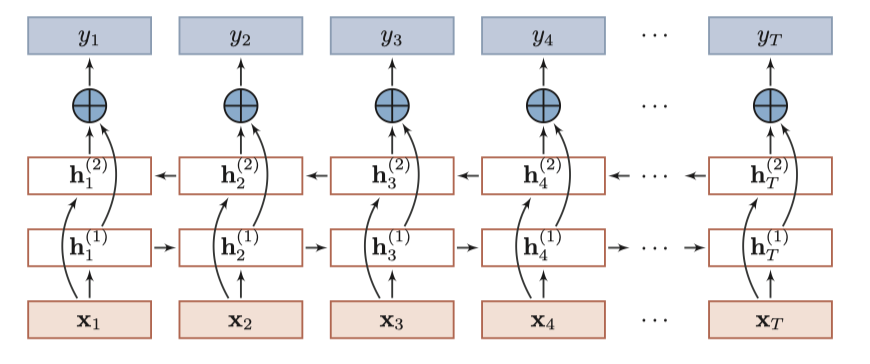
Bi-RNN
对于一些任务,输出不仅和过去时刻,还和未来信息有关,例如一个词的词性与上下文信息都有关,故可以采用双向的RNN搜集更多的信息
Bi-RNN有两层RNN的隐藏层组成,输入相同但顺序不同
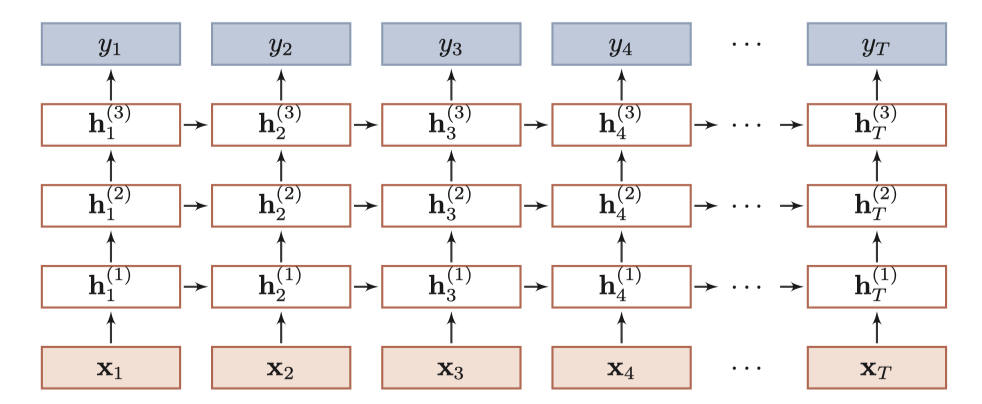
堆叠RNN
一个基本的RNN只有一个隐藏层,可以叠加多个隐藏层得到堆叠RNN
参数学习
用梯度下降的算法进行学习
待补充,参考邱
随时间反向传播BPTT
实时循环学习RTRL
RNN存在的问题
传统的RNN采取线性序列结构手机输入信息,在反向传播过程中,很容易导致梯度消失和梯度爆炸(爆炸还可以剪枝,消除就没辙了),简单的理解便是,信息在传播过程中,较远的信息起到的作用越来越小,为了解决这些问题,后来提出了LSTM和GRU
其次,RNN本身的序列输入,在工业界效率不高,很难高效的并行计算,不过有一些改造的RNN可以进行并行计算,但这些做法使RNN的特点并不那么明显。
参考
邱锡鹏:《神经网络与深度学习》