GraphIE: A Graph-Based Framework for Information Extraction笔记
在纠结一个事,自己读了一篇论文,读的很慢,没有去实现细节,只知道思路。还不如只瞅瞅大致的思想,关注的任务。先这样试试吧。
##本文是解决什么问题
Information Extraction System
将文本信息转化为结构化信息,对应KG的知识抽取,可视为nlp的子领域。
作者用图的方式利用了更多的非顺序文本信息和非本地信息,认为这些信息可以减少标记的歧义。
##前人方法的缺陷
信息提取系统IE,一般都是作为顺序标记器实现,对本地依赖项建模。
对比SeqIE(用BiLSTM和CRF的顺序模型)有提升
大部分结构非局部信息的IE都是定义一些机制(正则化或广义期望)对输出空间进行约束
##本文采用的方法/创新点
在图中表示文本单元,利用GCN传播节点信息,改进单词级别的预测。
##实现方式
将图形模块与编码器-解码器体系结构集成在一起,以进行序列标记。该算法在图上运行,节点对应于文本单位(即单词或句子),而边沿描述它们之间的关系。在模型的核心,一个递归神经网络依次对局部上下文表示进行编码,然后图形模块使用图卷积在相邻节点之间迭代地传播信息。
##实现细节
在我们的框架中,我们将GCN用作学习非本地上下文的中间模块,而不是直接用于分类,而是将其投影到解码器以丰富本地信息并执行序列标记。
encoder:采用RNN将句子或单词表示为向量
graph module:作者将信息抽取定义为序列标注问题,但并非简单将输入作为序列,而是假设信息中包含某种图的关系。graph module用来学习文本单元之间的非局部和非顺序依赖关系
decoder:利用图模块生成的上下文信息在单词级别执行标记
Encoder
作者将图模型分为了句子模型和单词模型,以句子模型为例,G(V, E)其中V是每个句子的表示,E是句子间的依赖。
先将句子中的每个单词,词向量和用charCNN学习特征表示为单词的向量,再用BiLSTM对每个句子单独编码。
这里应该是将句子中单词对应的词向量作为LSTM的输入,得到单词对应的隐藏状态,将这些隐藏状态求平均得到句子的向量表示。
Graph Module
利用GCN对图上下文进行建模以进行信息提取。将encoder得到的句子的向量表示作为GCN的节点输入,在相邻节点传播,得到一个新的隐藏表示。具体来说,每一层GCN有两部分,第一部分来自节点的前一层
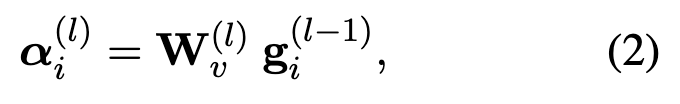
其中gi是encoder得到的表示,W是学习的权重
第二部分是相邻节点的聚合,相邻节点的表示乘对应依赖的权重再求平均
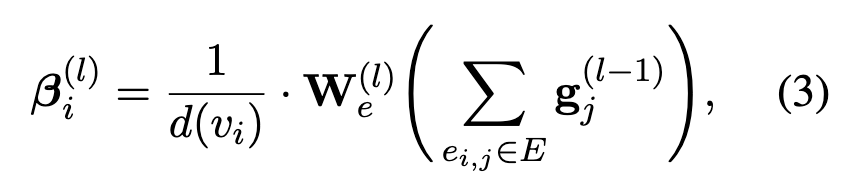
再用一个带偏置项的激活函数得到该层的隐藏表示
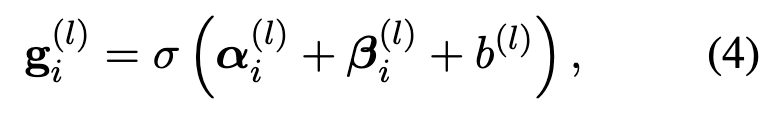
这里相邻节点是什么呢?该句的前一句和后一句吗?
关于权重,作者参考的是
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. \2018. Modeling relational data with graph convolutional networks. InEuropean Semantic Web Conference, pages 593–607.
由于每一层只在直接相邻的节点传播信息,因此可以堆叠多个图卷积层以获得更大的接收场,即每个节点可以知道更远的邻居。在L层之后,每个句子的表示通过GCN学习到了非本地和非局部的信息。
Decoder
解码器被实例化为一个BiLSTM+CRF标记器。GCN(s_i)被分为了两个登场的相邻,作为前向和后向LSTM的初始隐藏状态。用这种方式,图的上下文信息在每个单词之间通过LSTM传播,有
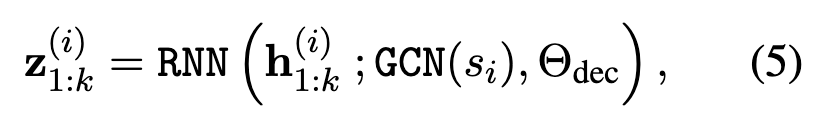
h是encoder输出的隐藏状态,GCN(s_i)是GCN的输出并作为初始状态,Θ是decoder的参数。将图形表示形式合并到解码器中的一种更简单的方法是将其表示与输入连接起来,但是经验显示其性能比它用作初始状态要差。
最后,再在BiLSTM上用一个CRF层进行标记。
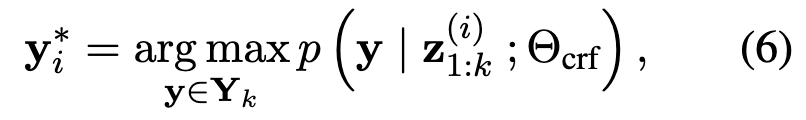
其中Y_k是所有长度为k的可能的标记序列,Θ是CRF的参数。CRF结合了BiLSTM的局部预测和过渡分数来对标签序列的联合概率建模。
实验
在文本抽取,社交媒体抽取和视频抽取任务重进行测试。
作者创建了一个特定于任务的图形拓扑结构,用于捕获输入数据的底层结构,而不需要进行任何其他的处理。
Textual IE
这里作者采用的是文章级别的NER(discNER),他认为句子之间的长期依赖和约束在标记过程中起着至关重要的作用。作者还利用了一些软规则改善抽取。
数据集是CONLL03和CHEMDNER dataset for chemical entity extraction
Social Media IE
这里作者是希望从用户推文重提取教育和工作信息,即给定用户发布的推文,提取对它们所属组织。
数据集是两个twitter语料库EDUCATION和JOB,原始数据集数百万的推文,这里采取了抽样。
将图构建为自我网络,即当提取有关一个用户的信息时,会考虑该用户及其直接邻居形成的子图。节点是一个twitter用户发的所有推文,使用编码器对每个推文进行编码,然后对它们进行平均以获取节点表示形式。在解码阶段,针对每个推文,图形模块的输出将馈送到解码器。
Visual IE
视觉信息提取是指从以各种版式格式化的文档中提取属性值。例如发票和表单,可以利用它们的格式推断有价值的信息来支持提取。
这里数据集用的是由25,200个不良事件病例报告(AECR)组成,记录了与药物相关的副作用。
在这个任务中,每个文本框被视为一个句子,并且对应于图中的一个节点。由于页面布局是这些文档的主要结构因素,所以是采取逐页工作的,即每个页面对应一个图表。边缘被定义为水平或垂直方向上相互接近的连接节点(文本框)(即它们的边界框在垂直或水平方向上的重叠超过50%)。考虑四种类型的边缘:从左到右,从右到左,从上到下,从下到上。当多个节点对齐时,只有最近的节点连接。