论文Knowledge Graph Embedding Based Question Answering
本文想解决什么问题?
- QAKG
- 将自然语言的问题转换为结构化的查询,类似SPARQL
- 返回KG中实体和关系作为答案
- 本文对问题的理解
- 如何通过embedding消除自然问题和KG中实体的差异
- 如何通过embdding来消歧
- 如何利用KG嵌入表示中保留的全局关系来推进QA-KG框架?
- QAKG
该问题为什么重要?
- 知识图谱庞大的数据量和复杂的数据结构使普通用户难以访问大量且有价值的知识 -> 需要KGQA
- 知识图上的问题回答为人工智能系统提供了一种将知识图作为回答人类问题的关键要素的方法,其应用范围从搜索引擎设计到会话代理构建。
- 子问题:语义分析和实体链接
该问题为什么困难?
- 三个主要挑战
- 自然语言中谓语有多种表达方式
- 由于候选集的庞大,实体名称和部分名称(省略全称)的模糊导致难以找到正确的实体
- 最终用户的问题通常是不受限制的,而任何KG都远远不够完整
- 三个主要挑战
本文的新贡献何在?
提出一个 Knowledge Embedding based Question Answering (KEQA) framework
设计一个joint distance metric(联合距离度量),该度量将嵌入表示的知识图中保留的结构和关系考虑在内。
Propose an effective framework KEQA that could answer
a natural language question by jointly recovering its head
entity, predicate, and tail entity representations in the knowl-
edge graph embedding spaces.
基本结论?
本文方法有何假设或者不足?
- 本文重点关注问题中最基本的类型——简单问题(只涉及一个单一的头实体和一个单一的谓语。)。
KEQA
知识图谱G中所有实体和关系都映射到向量空间,则给定一个简单问题,只要找到其头实体和关系对应的embdding,则可以回答。
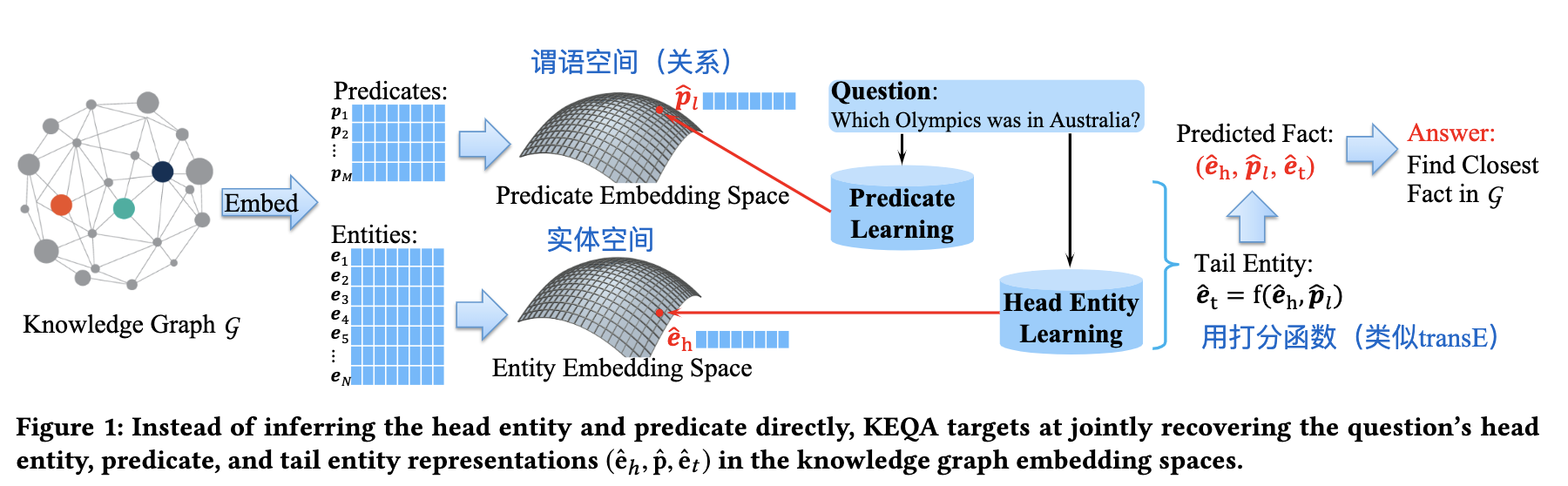
训练步骤
- step1
- 训练谓语:给定一个问题,返回一个在G中的谓语embedidng
- 实体同理
- step2
- 采用head entity detection模型来减少候选头实体(主要解决歧义问题和减少搜索空间)
- step
- 用训练mebedding的打分函数求出尾实体的embedding,结合joint distance metric返回答案
Knowledge Graph Embedding
用已有算法求出embedding
Predicate and Head Entity Learning Models
设计一个算法,输入一个简单问题,返回谓词和头实体对应的embedding
biRNN+attention
Neural Network Based Predicate Representation Learning
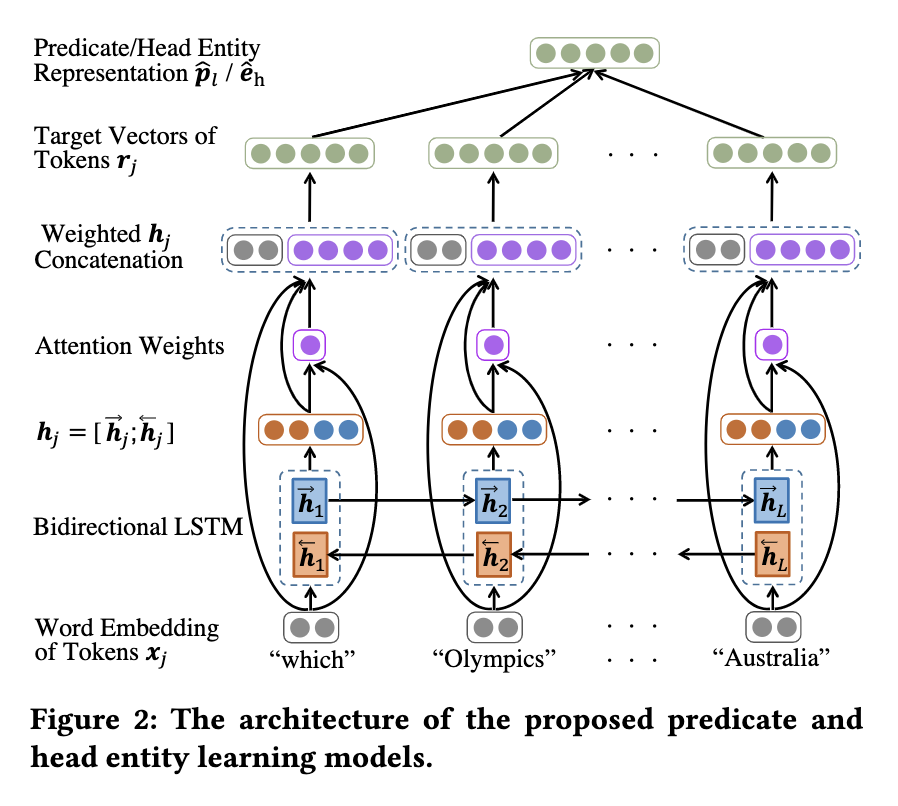
首先用预训练模型GloVe将问题L训练为词向量,再用biLSTM学习前向和后向的隐藏状态,接一个attention和全连接神经网络,最后对各谓词向量求平均得到问题的谓词向量。
Neural Network based Head Entity Learning Model
和检测谓词的模型类似,不过没有attention层。
作者将头实体识别这个问题视为了分类问题,分为实体名称和非实体名称。
有一个问题是实体的候选集会很大。
Joint Search on Embedding Spaces
如果事实(三元组)的头实体为候补实体(之前头实体识别模型识别出的),则将这个事实列为候补事实,而对于头实体和谓语有一个预测的表示(e_h,p_l),衡量候补事实与预测表示之间的距离,可以得到答案。但这种方法忽略了KG的embedding表示中的关系信息。
定义了一个函数实现e_t ≈ f(e_h, p_l),数学上这种联合距离度量为:
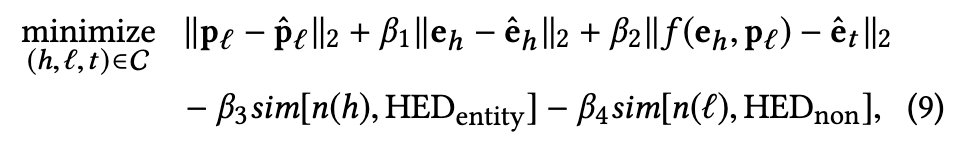
beta是预先定义的权值。L2范数来衡量距离。
KEQA框架

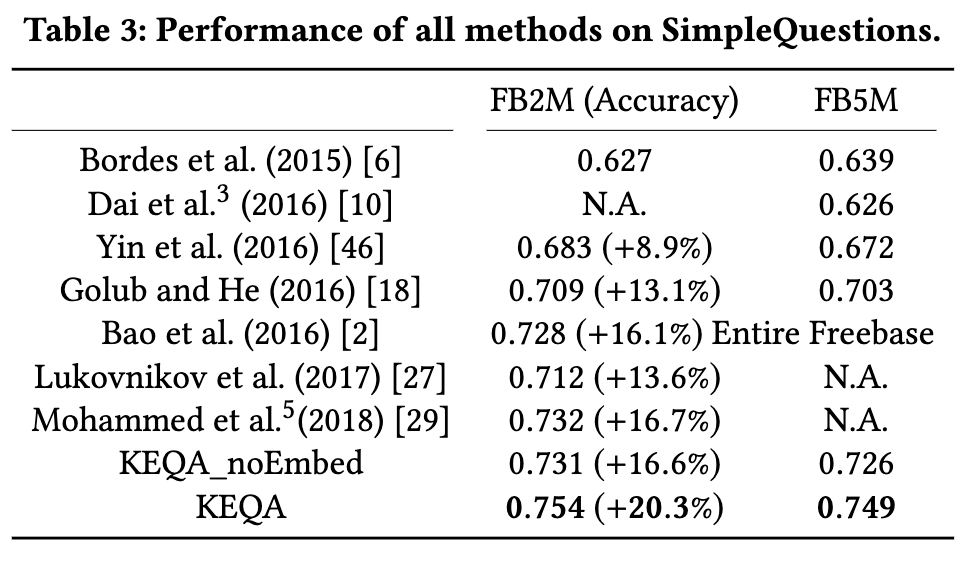
实验结果对比