Knowledge Graph Embedding: A Survey of Approaches and Applications 论文笔记
摘要
这是一篇综述性论文
作者在16年回顾了KG发展的关键技术,按照基于embedding task的不同类型进行回顾
本文首先介绍了仅使用KG中观察到的事实做嵌入的技术,描述了总体框架、特定的模型设计、流程和这些技术的优缺点
其次,讨论了不仅基于事实做嵌入的方式,尤其注意利用实体类型,关系路径,文字描述和逻辑规则。
最后,简要介绍了KG的embedding在上游和下游任务类似KG不全,关系抽取,自动问答等各方面的应用。
仅利用KG实体生成embedding
典型KG embedding生成步骤
- representing entities and relations
- 实体和关系可以被映射为vectors, matrices, tensors, multivariate Gaussians
- defining a scoring function
- 在KG中观察到的往往比未观察到的有更高的分数
- learning entity and relation representations
- the third step solves an optimization problem that maximizes the total plausibility of observed facts
大体的embedding分类
translational distance models平移距离模型
- 基于距离的评分函数
semantic matching models语义匹配模型
- 基于相似性的评分函数
Translational Distance Models
平移距离模型利用基于距离的扫描函数。他们用两个实体之间的距离来衡量一个事实的可信性,通常是在经过一个翻译的关系进行的。
TransE and Its Extensions
TransE 2013是典型的翻译模型,将三元组(h, r, t)看作h+r=t
TransE打分函数如下:
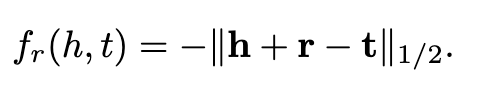
在知识表示的1-to-N、N-to-1、N-to-N中表现很好
transE可能将不同的实体表示为类似的embedding
例如:
Psycho, Rebecca和RearWindow都是由AlfredHitchcock执导的电影,可能其embedding被transE学习得很类似
解决方式:引入特定关系的实体嵌入
为了解决该问题,一个办法是允许实体在面对不同关系时可以有不同的表示
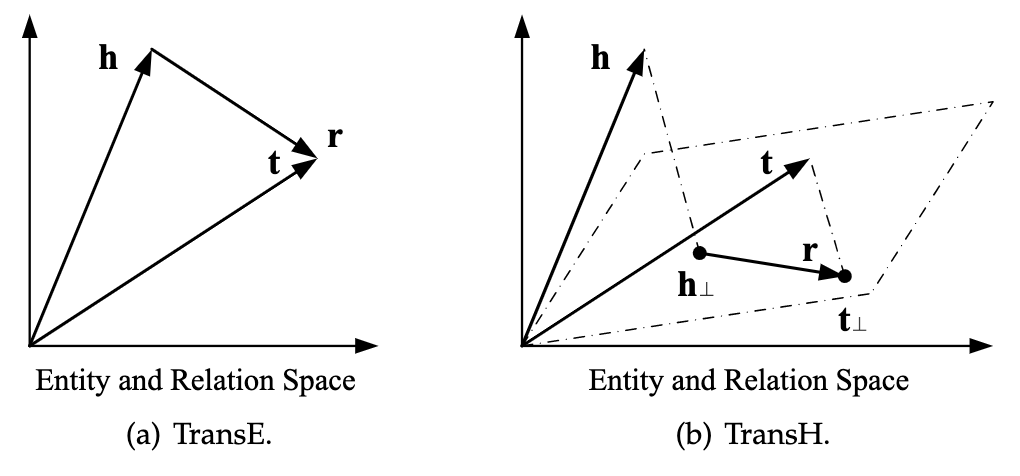
TransH 2014
- TransH根据这种思路,引入了“关系特定超平面”
- h和t首先映射到超平面
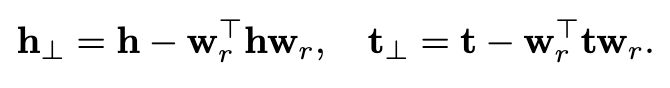
- 投影到超平面后h和r由t连接
- 打分函数
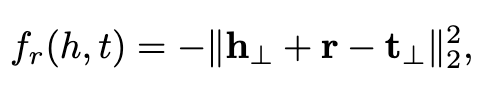
- TransH可以让实体在不同关系中表现不同
TransE和TransH模型都假设实体和关系是在同一个语义空间的向量,这样相似的实体会在空间中相近的位置,然而每一个实体都可以有很多方面,而不同的关系关注的是实体不同的方面。因此,TransR模型对不同的关系建立各自的关系空间,在计算时先将实体映射到关系空间进行计算。因为是在关系空间做向量叠加,所以这个模型叫做TransR
https://zhuanlan.zhihu.com/p/32993044
这一部分大量引用了知乎用户“”的文章
个人觉得比综述的这一部分更详细
TranR 2015
- TransR和TransH类似,引入的是“关系特定空间”
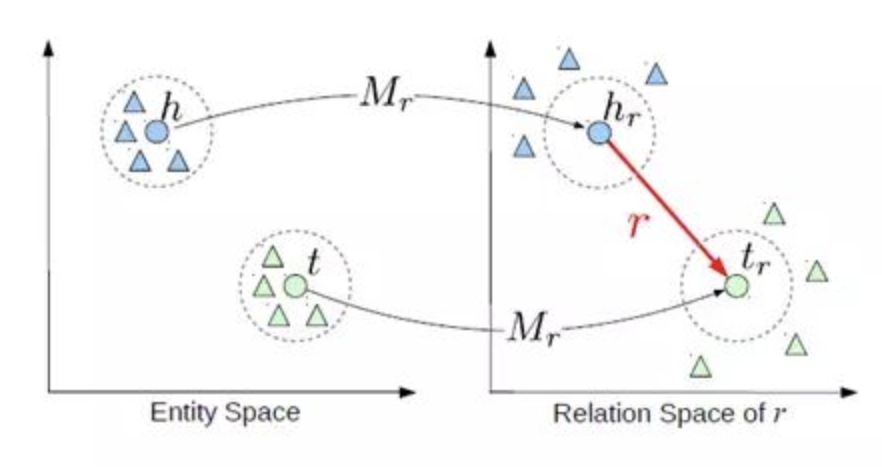
- 对于每个关系,有一个变换矩阵Mr和一个在它自己的关系空间的表示向量r。通过变换矩阵将前件和后件的表示向量映射到关系空间
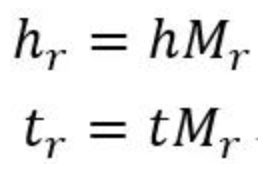
- TransR打分函数和TransH类似
TransR同样有它的问题,首先对于一种关系,它的前件和后件使用同样的变换矩阵映射到关系空间,而前件和后件往往是完全不同类的实体,比如(刘康,工作单位,中科院自动化所),其中刘康老师和自动化所就是不同范畴的实体,也应该使用不同的方法进行映射。其次,这种映射是与实体和关系都相关的过程,然而映射矩阵却只由关系确定。最后,TransR模型运算量大且参数较前两种模型多得多。
TransD 2015
TransD模型对每个实体或关系使用两个向量进行表示,一个向量表示语义,另一个(用下表p表示)用来构建映射矩阵。映射矩阵通过以下公式构建:
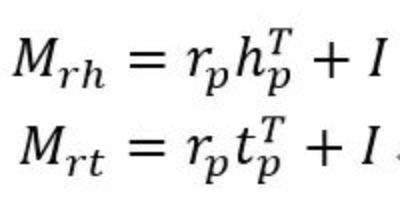
这样映射矩阵就由实体和关系共同决定了,其中I为单位阵,即通过向量相乘生成的矩阵对单位阵(代表不做变换)进行调整。后面的映射和训练过程和TransR相同。
这样的话,TransE模型就变成了TransD模型的一个特例,只要实体表示的维度与关系表示的维度相同且所有用于构建映射矩阵的向量均为0。此外,上面构建映射矩阵和进行空间变换的过程还可以用向量相乘代替,从而避免了耗时的矩阵乘法,即
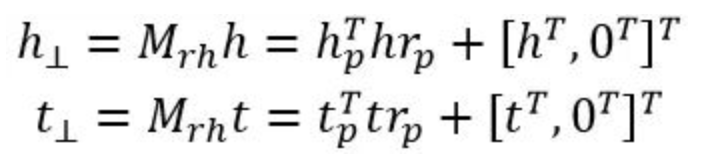
补0是因为这里假设关系空间维度比实体空间维度高。
TranSparse 2016
使用不同程度的稀疏矩阵进行从实体空间到关系空间的变换。
有两个版本,share和separate,前者实体和关系共享一个映射矩阵,后者实体和关系采用不同的映射矩阵。
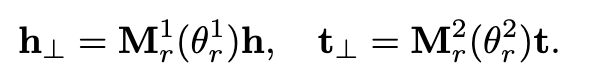
theta表示稀疏的程度。
通过引入稀疏映射矩阵,有效降低了参数的数量。
其他Trans
TransM放松了h+r≈t的条件,引入了权值weigh。
ManifoldE,TransF虽然采取方式不同,但大体思路都是从打分函数入手,改变了传统TransE的h+r≈t
TransA同样,其将关系r引入了对称的非负矩阵,并且将打分函数转换为一个自适应的马氏距离,通过学习距离关系矩阵,TransA处理复杂矩阵更加灵活。
Trans系列还有很多变种等等,这里就不一一介绍了
借用知乎用户“reflux Ning”的话
“都是基于最初TransE模型的生长,即使用前件和关系向量之和来预测后件向量。向量之和从某种程度是表示的是信息的叠加,但是实体和关系或许不仅仅是信息的叠加而已。”
Gaussian Embeddings
之前的Trans系列都是将实体和关系视为向量空间中确定的点,Gaussian Embedding考虑了其不确定性,将之表示为随机向量。
KG2E
He等人认为,知识库中的关系和实体的语义本身具有不确定性,而过去模型中都忽略这个因素。
将实体和关系表示为从多元高斯分布中抽取的随机向量。使用高斯分布来表示实体和关系。其中高斯分布的均值表示的是实体或关系在语义空间中的中心位置,而高斯分布的协方差则表示该实体或关系的不确定度。
受到翻译模型trans的启发,KG2E将一个事实打分为,两个随机向量,一个是t-h,一个是r,即从两个分布…中抽取
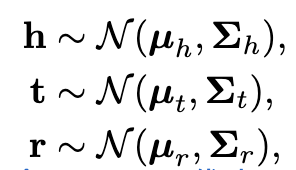
它用到了两种衡量距离的方式,一种是相对熵KullbackLeibler divergence
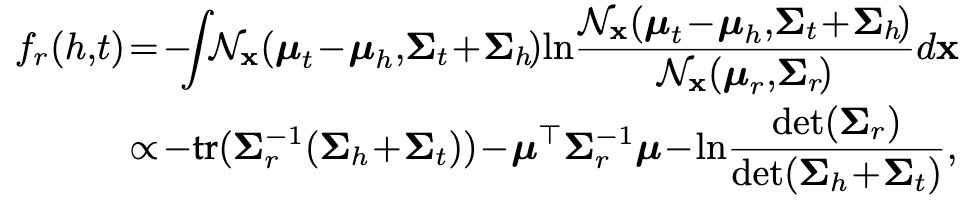
另一种是概率内积probability inner product
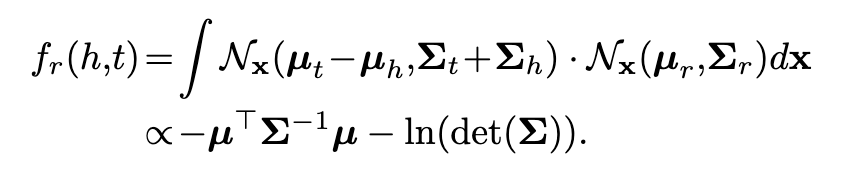
由于这种Gaussian embeddings,KG2E能有效的将知识图谱中的不确定实体和关系模型化。
TransG
TransG也将实体与Gaussian distribution进行构建,该论文认为关系可以有多个语义,因此应该表示为一种混合的高斯分布。
TransG模型与传统模型的对比如图4所示。其中三角形表示正确的尾实体,圆形表示错误的尾实体。图4(a)中为传统模型示例,由于将关系r的所有语义混为一谈,导致错误的实体无法被区分开.而如图4(b)所示,TransG模型通过考虑关系r的不同语义,形成多个高斯分布,就能够区分出正确和错误实体。
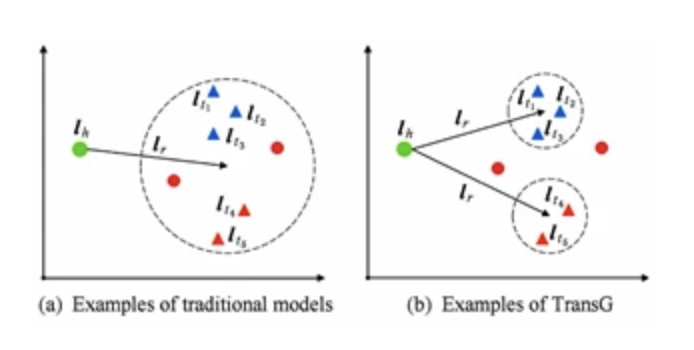
其他距离模型
UM是一种简化版的TransE,设置所有r=0,不能区分不同的关系
SE采用了两种(h和t)的矩阵,使头实体h和尾实体t对每个关系r进行映射
一些综述将SE与Trans系列进行区分。认为前者基于的思想是距离,即当两个实体属于同一个三元组时,它们的向量表示在投影后的空间中也应该彼此靠近。后者是翻译,但个人认为从结果和做法来看二者思想非常相近。
Semantic Matching Models
语义匹配模型利用基于相似性打分函数。他们通过匹配实体和关系体现在向量空间中的潜在语义性来衡量事实(三元组)的可信性。
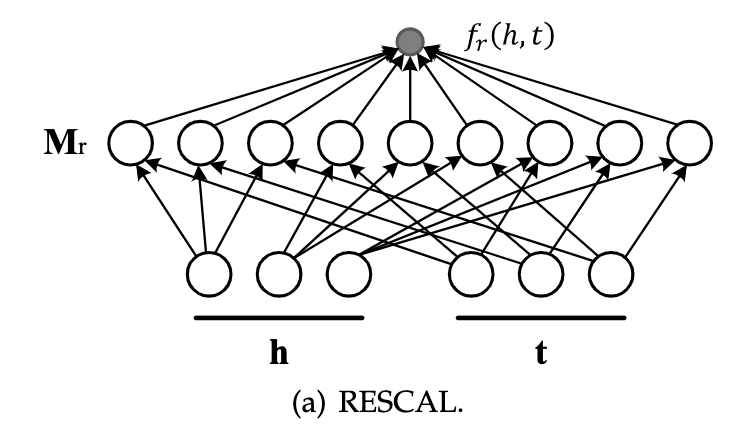
RESCAL and Its Extensions
RESCAL
它将实体表示为一个向量来捕获其潜在的语义。每个关系表示为矩阵,用来模拟相关因子之间的互相作用。打分函数被定义为一种线性函数:
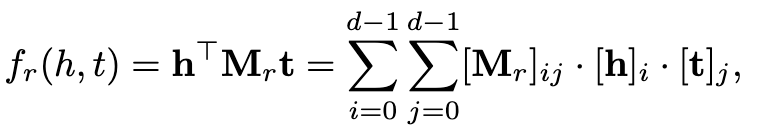
这个分数会捕获所有h和t的相互作用,需要O(d^2)的参数。
个人猜测是,r是一个矩阵,则将h和t的向量和r的一维结合考虑,打分函数考虑了所有的这些情况的组合。
进一步假设,Mr矩阵会在一个rank-1维的矩阵上分解。
TATEC在打分函数上做了改变,对三向交互h,r,t和双向h和r等都进行了建模。
DistMult
DistMult通过将Mr限制为对角矩阵来简化RESCAL。对于每一个关系r,它都引入一个向量嵌入r,并要求Mr=diag(r),打分函数如下:
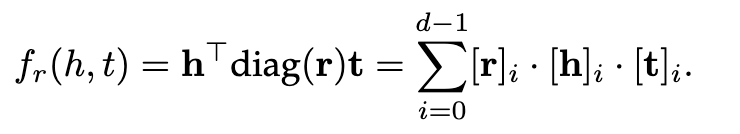
该评分函数只捕获沿同一维度的h和t分量之间的成对交互作用,并将每一个关系的参数数量减少至O(d)。然而,由于对于任意的h和t,hTdiag(r)t = t Tdiag(r)h都是成立的,这种过度简化的模型只能处理对称的关系,这显然对于一般的KGs是不能完全适用的。
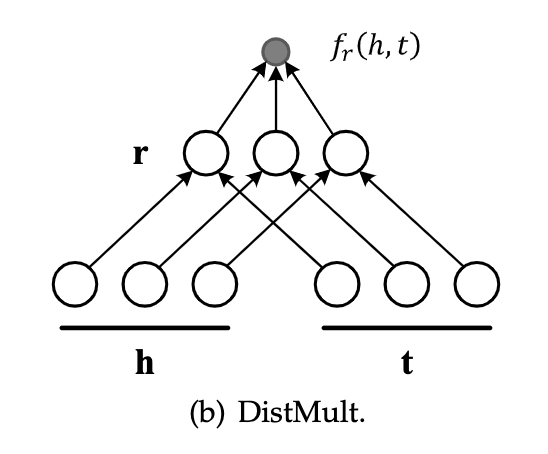
HolE
HolE将RESCAL的表达能力与DistMult的效率和简单性相结合。它把实体和关系都表示为R^d^中的向量。给定一个事实(h,r,t),首先使用循环相关操作将实体表示形式组成[h*t]∈R^d^
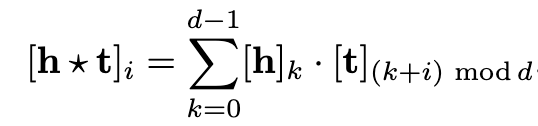
然后将这种组合向量[h*t]与关系表示形式匹配,来对事实(三元组)进行评分
打分函数为
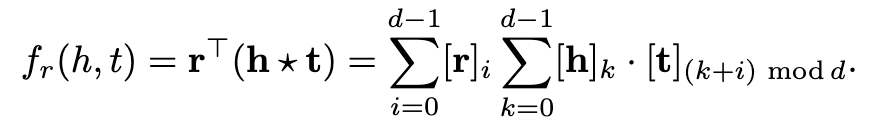
循环相关对成对的相互作用进行压缩。因此,HolE对每个关系只需要O(d)参数,这比RESCAL更有效。与此同时,因为循环相关是不符合交换律的,即ht不等于th。所以HolE能够像RESCAL那样对不对称关系进行建模。
ComplEx
ComplEx通过引入复值嵌入来扩展DistMult,以便更好地对非对称关系进行建模。在ComplEx中,实体和关系嵌入h,r, t不再存在于实空间中,而是存在于复空间中。定义事实的评分函数为:
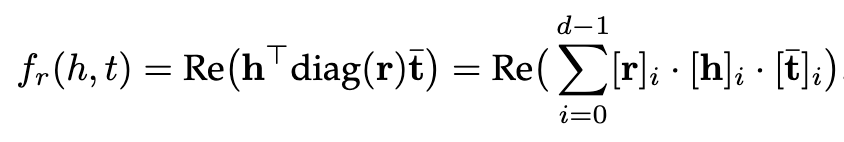
其中,t-是t的共轭和Re(·)表示取复数的实部。这个评分函数不再是对称的,来自非对称关系的事实可以根据涉及实体的顺序得到不同的分数。
有研究表明每个ComplEx都有与其等价的HolE(说反了吧),HolE可以被认为是ComplEx的一种在embedding上施加共轭对称的一种特殊情况,
ANKOGY
ANALOGY 扩展了RESCAL,从而进一步对实体和关系的类比属性进行建模,例如,AlfredHitchcock之于Psycho,正如JamesCameron之于Avatar。它遵循RESCAL并使用双线性评分函数
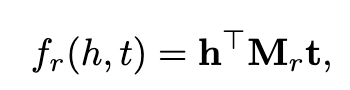
其中,h,t是对于实体的嵌入向量,Mr是一个与关系相关的线性映射R^(d*d)。为了对类比结构进行建模,它进一步要求关系线性映射是正规的和符合交换律,即:
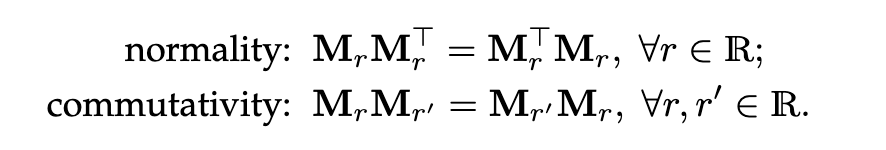
尽管ANALOGY表示关系为矩阵,这些矩阵可以同时对角化成一组稀疏的准对角矩阵,由每个只有O(d)自由参数。结果表明,前面介绍的DistMult、HolE、ComplEx等方法都可以归为ANALOGY的特例。
相似结构的模型,结构较为简单的模型包含复杂的模型,是这样么
Matching with Neural Networks
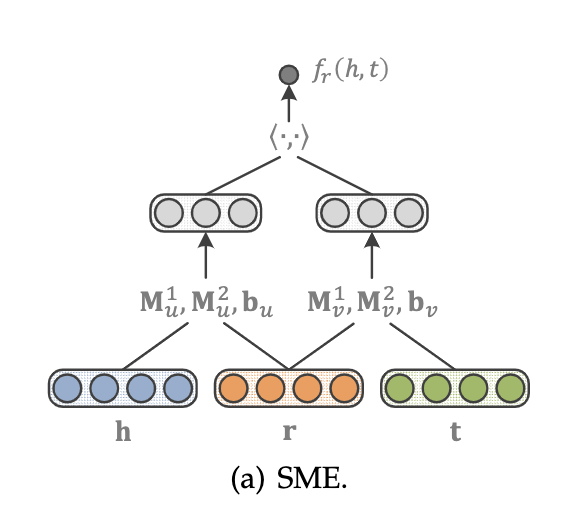
Semantic Matching Energy (SME)
SME采用神经网络结构进行语义匹配。给定一个事实三元组(h,r,t),它首先将实体和关系投影到输入层中的嵌入向量。然后,将关系r与头实体h组合得到g_u(h,r),并与尾实体t组合,得到隐藏层中的g_v(t,r)。则该事实的分数最终由它们的点积定义为匹配的g_u和g_v。即:
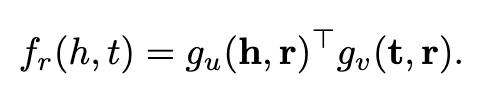
SME有两种类型,双向线性类型和单向线性类型
单向为
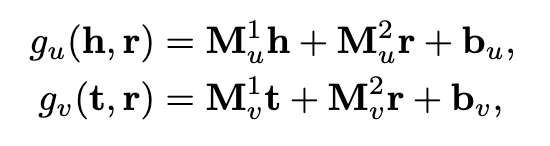
双向为
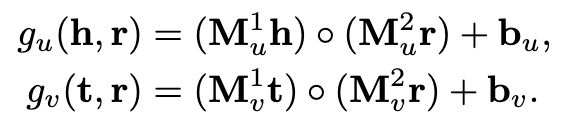
其中,Mu^1^、M_u_2、M_v_1、M_v_2是权重矩阵,而bu、bv是跨不同关系共享的偏差向量,其简要示意如下
NTN
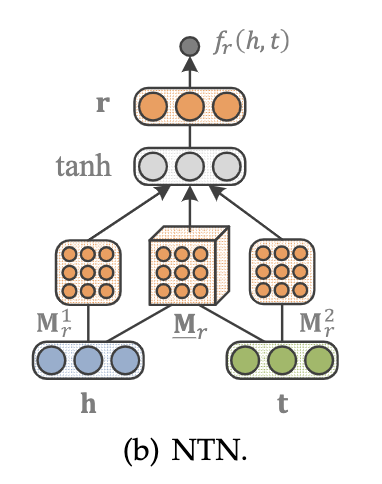
NTN是另外一种神经网络结构,给定一个事实,它首先将实体投影到输入层中的嵌入向量。然后,将这两个实体h,t由关系特有的张量M_r(以及其他参数)组合,并映射到一个非线性隐藏层。最后,一个特定于关系的线性输出层给出了评分,即:
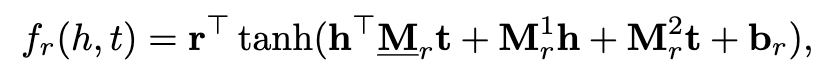
其中M_r_1、M_r_2和b_r分别是特定关系的权重矩阵和偏差向量。双线性张量积hTM_rt得到一个向量,其中第i项计算为 hT*M_r*t。通过设置所有M_r=0和b_r= 0,NTN退化为单层模型(SLM)。尽管NTN是迄今为止最具表达能力的模型,但是,由于它的每个关系的需要O(d^2*k)个参数,并且不能简单有效地处理大型的KGs。
NTN示意图如下
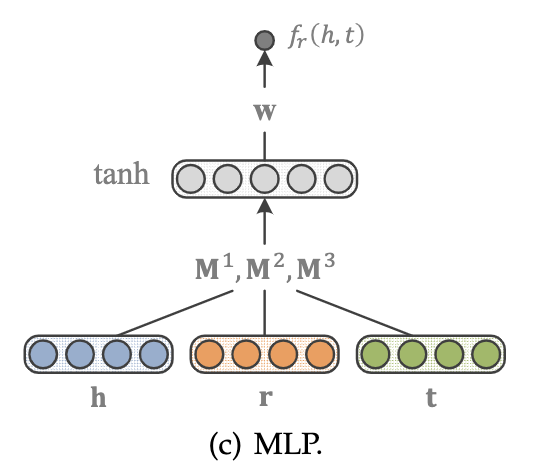
多层感知器MLP
MLP是一种更简单的方法,在这种方法中,每个关系(以及实体)都是由一个向量组合而成的:
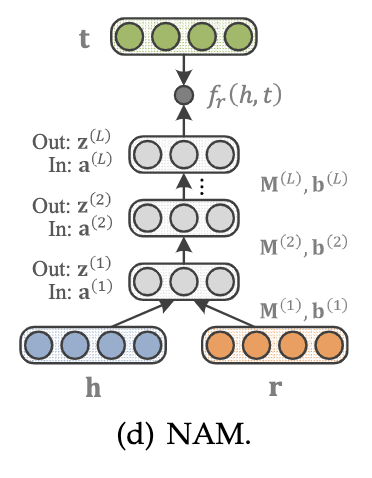
神经关联模型NAM
NAM使用“深度”架构进行语义匹配,给定一个事实,它首先将头实体的嵌入向量和输入层中的关系连接起来,从而给出z_0=[h,r]。然后输入z_0输入到一个由L个线性隐层组成的深神经网络中,这样:
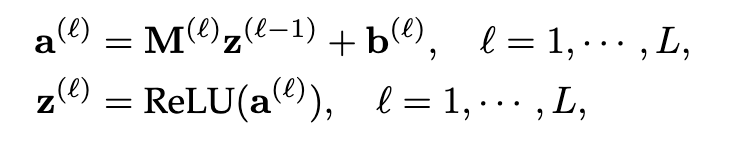
其中M_(l)和b_(l)分别表示第l层的权重矩阵和偏差。在前馈过程之后,通过匹配最后一个隐藏层的输出和尾实体的嵌入向量来给出分数,即:
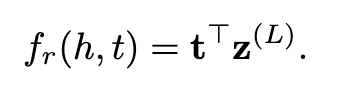
NAM示意
训练模型(单独以KG信息)
个人感觉这部分要结合代码才好
这部分讨论常规的训练KG的embedding的过程,这里有两个广泛的假设,open world和close world。
The closed world assumption is the presumption that what is not currently known to be true, is false. The same name also refers to a logical formalization of this assumption by Raymond Reiter. The opposite of the closed world assumption is the open world assumption, stating that lack of knowledge does not imply falsity. ——摘自维基百科
可以参考[这个链接][http://www.sohu.com/a/144575100_464088]
Training under Open World Assumption
OWA假设KGs只包含正样例(事实)和未被观察到的事实,负样例可以由启发式产生,比如下一节的封闭世界假设。
logistic loss
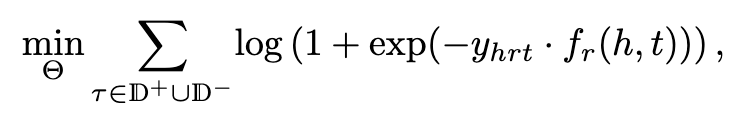
优势:对一些复杂的关系模式(如transitive relations)得到一些紧凑的表达方式
pairwise ranking loss
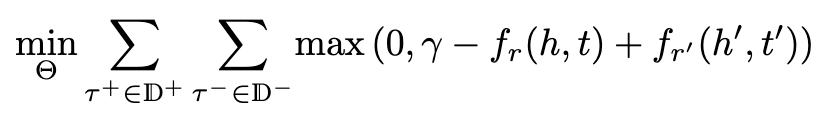
优势:不假设负样本一定是(命题)错误的,只是和正样本相比可能性小,使得positive facts得分要尽可能高于negative ones
以上的目标函数中均包含约束项/正则项【不同的embedding模型不同】,已证明:logistic loss+semantic matching models(DisMult、ComplEx等)性能更好;pairwise ranking loss+translational distance models(TransE)性能更好
优化
可以采取stochastic gradient descent (SGD)进行简单的优化。
AdaGrad常被用来调整学习速率。
Algorithm
论文中详细介绍了算法中的每个步骤,这里就不说明啦。

50 negatives per positive example is a good trade-off between accuracy and training time
这句话的意思是每个正样例有50个负样例训练消耗会好么?
这样的话负样例也太多了吧,有待去看原论文。
Training under Closed World Assumption
对于知识库中不存在的,退不出来的,就将其认为是负样例。
squred loss
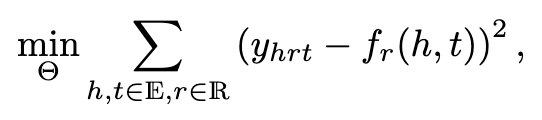
封闭世界假设有很多缺陷,首先很多KGs都是不完整的,这种情况下CWA表现会劣于OWA,其次,封闭世界假设会产生大量的负样例,这可能会导致模型训练的可扩展性问题。
模型比较(单独以KG信息)

论文中比较详细的进行了比较,这里省略。
一个有趣的事情是, 一些结构复杂的模型不一定是结构简单的模型表现更好,比如NTN不比MLP表现更好,甚至比不过TransE和DistMult,这可能是由于其有太多参数,导致在一些小型和中型的数据集上会导致过拟合。
其他方法
除上述模型外,还有其他学习头尾实体对的表示。具体地,给定一个三元组(h,r,t),关系r可以表示为一个向量r,实体对(h,t)可以用另外一个向量p表示。该事实的合理性可以通过r和p内积进行度量。然后,通过最小化成对排序损失来学习这些向量表示,类似于在Eq(2)中的定义。这种实体对表示特别适用于关系提取,其目的是确定一对实体之间可能存在的关系。同样地,头实体h可以表示为一个向量h,实体对(r,t)可以用另外一个向量p表示。然而,这种方法也有其缺点。比如,如果头-尾实体对(h_1,t)和(h_2,t)通过不同的向量表示进行建模,则它们共享的相同的尾实体信息将会丢失。而且,也无法有效地发现未配对实体(如h3和t)之间的关系。此外,它还导致了空间复杂度的增加,因为每个实体对都需要计算一次向量表示,它总共需要O(n^2d+md)个参数。
结合额外信息生成embedding
不仅利用KGs本身的事实,还利用实体类型,关系的路径,文本描述和逻辑规则等。
Entity Types
实体所属的语义类别。例如AlfredHitchcock的类别是Person,这些在大多数KGs都是容易获得的,一种直接的方式是将这种关系对应直接以普通三元组的方式加入训练。
SSE
Guo提出光滑语义模型SSE,将相同type的实体在embedding空间中保持接近。
已经毕业的同实验室师姐,我透,厉害。
SSE采用两种流型学习算法,拉普拉斯映射和局部线性嵌入来光滑建模。前者要求一个实体和同一类别中的每一个其他实体邻近,给出一个平滑度量:
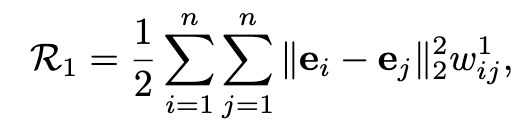
其中e_i和e_j分别是实体ei和ej的嵌入向量,如果这两个实体属于同一范畴,则w=1,否则w=0。通过最小化R_1,只要当w=1时,我们期望e_i和e_j之间距离会很小。后者表示一个实体视为其最近邻居的线性组合,即同一类别内的实体,平滑度量如下:
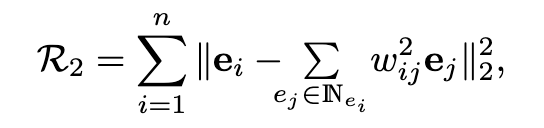
其中IN_ei是包含实体e_i最近邻的集合,如果e_j属于IN_ei,w=1,否则w=0。通过最小化R_2,我们期望每个实体在误差小的情况下,从其最近的邻域进行线性重构。然后将R_1和R_2合并为正则化项,以约束嵌入任务。在KG嵌入和下游任务中,SSE的性能都优于直接方法。SSE的一个主要限制是它假设实体的语义范畴是无层次的,每个实体完全属于一个类别。显然,在典型的现实世界中,情况并非如此。
SSE的一个主要限制是它假定实体的语义类别是非层次的,并且每个实体只属于一个类别。这显然不符合实际情况。
TKRL
相比SSE,可以处理多层次目录和多类别的标签。
TKRL是距离翻译模型再加入了对特定类型的映射,给定一个(h, t, r),r被视为映射矩阵h到映射矩阵r的翻译,打分函数如下:
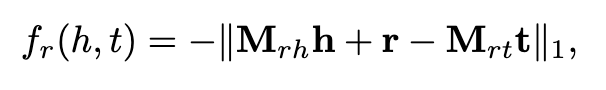
其中M_rh和M_rt是h和t的投影矩阵,为了处理多个类别标签,M_rh表示为所有可能的类型矩阵的加权和。
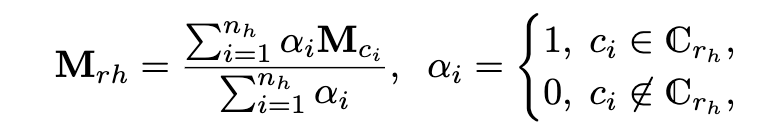
其中n_h>=1是h所属的类别数;c_i是其中的第i个类别;M_ci是c_i的投影矩阵;a_i是对应的权重;C_rh是头实体可以具有的与r相关的类型集合。为了进一步处理层次类别,M_ci表示为与c_i的所有子类别关联的投影矩阵的组成。使用两种类型的合成操作,如下:
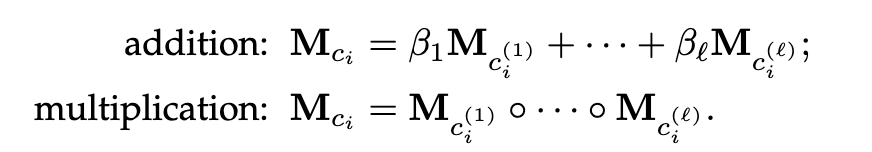
其中,c_i_(1),…,c_i_(l)是是层次结构中c_i的子集;M_ci_(1),…,M_ci_(l)为投影矩阵,beta_(1),…,beta_(l)是对应项的权重。M_rt的定义也是类似的。虽然TKRL在链路预测和三元组分类等下游任务中取得了较好的性能,但由于它将每个类别与特定的投影矩阵相关联,因此具有较高的空间复杂度。
实体类型也可以作为不同关系的头部和尾部位置的约束,例如关系DirectorOf的头实体的类型应该是人,尾实体的类型应该是电影作品。[77]和[26]试图在训练过程中施加这种约束,尤其是在反例的生成过程中。从训练中排除违反类型约束的反例,或者产生的概率很低。[93]对张量因式分解模型RESCAL施加了类似的约束。其思想是丢弃具有错误实体类型的无效事实,只分解由剩余事实组成的子张量。
看到后面,有点犯懒了,所以这部分是直接用的https://new.qq.com/rain/a/20190826A0N3ZI,大致就是论文的翻译
[77]D. Krompaß, S. Baier, and V. Tresp, “Type-constrained represen-
tation learning in knowledge graphs,” in Proc. 14th Int. Semantic
Web Conf., 2015, pp. 640–655.
[26]R. Xie, Z. Liu, and M. Sun, “Representation learning of knowl-
edge graphs with hierarchical types,” inProc. 25th Int. Joint Conf.
Artif. Intell., 2016, pp. 2965–2971.
[93]K.-W. Chang, W.-t. Yih, B. Yang, and C. Meek, “Typed tensor
decomposition of knowledge bases for relation extraction,” in
Proc. Conf. Empirical Methods Natural Language Process., 2014, pp.
1568–1579.
Relation Paths
关联路径即实体间的多跳关系。常被定义为一个关系序列:r1 -> r2 …-> rl,两个实体通过这个序列可以在图中连接。
例如, BornIn → LocatedIn is a path linking AlfredHitchcock to England, via an intermediate node Leytonstone.
关联路径包含丰富的语义线索,对知识图谱的补全非常有用。
关联路径再多重关系中研究已久了。例如,路径排序算法直接利用路径连接实体,作为一个特征(feature)来预测它们之间的潜在关系。最近(16年)他们已将其嵌入到了KGs,因此,一个关键的挑战是如何在相同的向量空间中表示这些路径以及实体和关系。一个直接的简单的解决方案是将路径表示为关系表示的一部分,因为路径的语义取决于所有这些关系。
下面是个简要的示意:
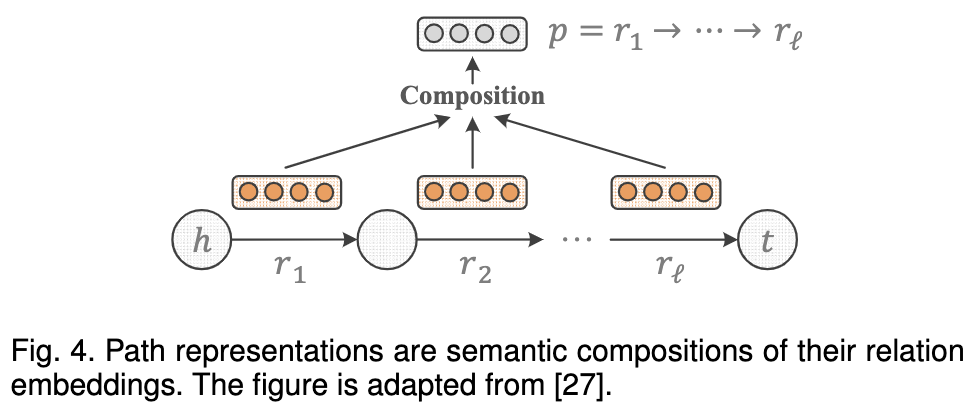
实际上,几乎所有以前的方法都使用组合策略来处理关系路径。典型的组合操作包括加法,乘法,以及RNN。
pTransE
pTransE[27]将TransE是TransE在关联路径的延伸。给定一个路径p = r1 → ··· → rℓ连接到h和t,以及组成关系的向量表示r_1,r_2,…r_l,PTransE考虑了三种类型的组合操作,即:
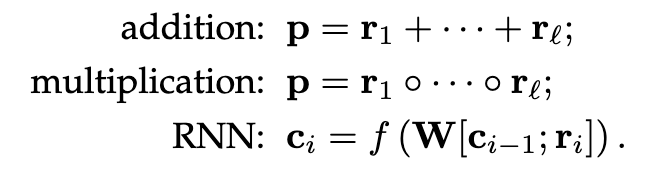
细节待补充
实验证明,通过进一步结合关联路径,pTransE在补全和关系抽取方面明显优于TransE。
Guu[28]提出了一种类似的框架,使实体对不仅和关系连接,还和关联路径连接。例如,给定一对实体(h, t)和路径p = r1 → ··· → rℓ ,则可以构造(h, p ,t)。通过构造这样的路径连接三元组,Guu对TransE和RESCAL做了拓展。二者定义的打分函数不同(这里略)。
在训练过程中,将路径连接三元组视为与那些关系连接的三元组相同。这种方法在回答KGs上的路径查询方面表现良好。
虽然引入关联路径提升了模型的效果,但也带来了复杂性的挑战。[27]的pTransE和[28]提出的框架都需要通过剪枝或者抽样来得到近似的结果。
为了实现有效的路径建模,[29]提出了一种动态规划算法,该算法可以将所有边界长度的关联路径结合起来。
关联路径的任务中,不仅“关系r”被建模,中间节点可能也会被组合的路径考虑到。
[27] Y. Lin, Z. Liu, H. Luan, M. Sun, S. Rao, and S. Liu, “Modeling
relation paths for representation learning of knowledge bases,”
in Proc. Conf. Empirical Methods Natural Language Process., 2015,
pp. 705–714.[28] K. Guu, J. Miller, and P. Liang, “Traversing knowledge graphs in
vector space,” in Proc. Conf. Empirical Methods Natural Language
Process., 2015, pp. 318–327.[29] K. Toutanova, V. Lin, W.-t. Yih, H. Poon, and C. Quirk, “Compo-
sitional learning of embeddings for relation paths in knowledge
base and text,” in Proc. 54th Annu. Meeting Assoc. Comput. Lin-
guistics, 2016, pp. 1434–1444.
Textual Descriptions
本节讨论对实体的文本描述的集成。实际上,在大多数KGs中,对于包含丰富语义信息的实体,有简明的描述。此外,实体描述除了存储在KGs以外,它还可以扩展到结合更多的一般文本信息,如发布的新闻和维基百科文章。下图显示了在FreeBase中对AlfredHitchcock和 Psycho描述信息。

嵌入带有文本信息的 KGs可以追溯到前面讲述的NTN模型,其中文本信息只是简单的用于初始化实体表示。具体来说,NTN首先从辅助新闻语料库中学习单词向量,然后通过对包含在其名称中的单词的向量求平均来初始化每个实体的表示。例如,AlfredHitchcock的嵌入是通过 “Alfred”和“Hitchcock”的平均单词向量初始化的。后来有人提出了一种类似的方法,它把实体表示为描述的平均词向量而不仅仅是它们的名称。由于这种方法将文本信息与KG事实分开,因此不能利用它们之间的交互信息。
joint model
Wang等人首先提出了一个联合模型,它可以在嵌入过程中更好地使用文本信息。其核心思想是使给定的KG与辅助文本语料库对齐,然后再联合进行KG嵌入和词嵌入。这样,实体/关系和词就是在同一个向量空间中表示的,因此它们之间的运算如内积(相似性)是有意义的。该联合模型具有三个组成部分:知识模型,文本模型和对齐模型。知识模型是将实体和关系嵌入到KG中。它是TransE的变体,损失L_k测量KG事实的拟合度。文本模型是在文本语料库中词嵌入,它是Skip-gram的变体,损失L_t测量对共现词对的拟合度。最后,对齐模型保证了实体/关系的嵌入,以及单词位于相同的空间中。还引入了不同的对齐机制,比如通过实体名称、维基百科以及实体描述对齐。将损失L_A定义为测量对齐的质量。然后,联合模型将三个损失最小化。
联合嵌入利用来自结构化的KGs和非结构化文本的信息。因此,可以通过彼此增强KG嵌入和词嵌入。此外,通过对这两种类型的信息进行对齐,联合嵌入还能够预测KG不包含的实体,即出现在web文本中但在KG不包括的短语。
DKRL(description-embodied knowledge representation learning)
Xie等人[32]提出了一种融合描述的知识表示学习模型,其目的是对TransE进行扩展以便更好地处理实体的描述。DKRL将实体e与两个向量表示相关联,即基于结构的e_s和基于描述的e_d。前者捕获KG事实表示的结构信息,而后者捕获实体描述表示的文本信息。基于描述的表示由组成词嵌入构成,通过连续的词袋编码器或卷积神经网络编码器来构造。给定一个事实(h,r,t),DKRL把评分函数定义为:
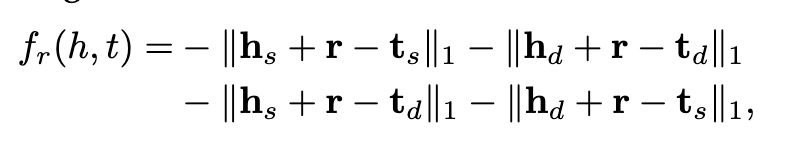
其中r是关系的向量表示,并共享基于结构的h_s/t_s和基于描述的h_d/h_d。然后,通过最小化Eq(2)中定义的排序损失,可以同时学习实体、关系和词嵌入。实验结果证明了DKRL相对TransE的优越性,特别是在超出KG包含实体的情况下。
TEKE
Wang等人最近提出了一种文本增强的KG嵌入模型,称为TEKE。给定一个KG和一个文本语料库,TEKE首先对语料库中的实体进行注释,并构造一个由实体和词组成的共现网络。然后,对于每个实体e,TEKE将其文本的上下文n(e)定义为它在共现网络中的邻域,即文本语料库中与实体频繁共现的词。对该实体进一步引入了文本上下文嵌入n(e),把它定义为n(e)中单词向量的加权平均值。对于事实(h,r,t)中的每一个关系r,TEKE将其文本上下文定义为h和t的共同邻域,即n(h,t)=n(h)∩n(t)。类似地,为该关系定义文本上下文嵌入为n(h,t)。然后将文本上下文嵌入结合到传统方法中,例如TransE,以学习更有表达能力的实体和关系表示,例如:
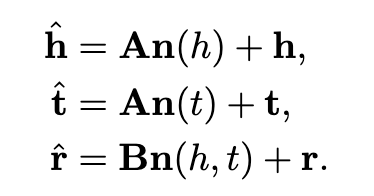
其中A,B是权重矩阵,h,t,r偏差向量。此扩展也适用于TransH和TransR。通过结合文本上下文嵌入,证明TEKE是优于原来的TransE、TransH和TransR模型。
Logical Rules
最后,我们考虑结合逻辑规则,特别是那些从一阶Horn子句来考虑的规则。
A Horn clause is a boolean formula, constructed according to the rules below. Let x be a variable from the set. Then a literal is a boolean expression which consists only of the variable by itself or of the variable negation: either x (positive literal) or ¬x (negative literal). A clause is a disjunction of one or more literals. A Horn clause is a clause with at most one positive literal.
例如∀x, y : HasWife(x, y) ⇒ HasSpouse(x, y)指出由关系HasWife连接的任何两个实体也应该由关系HasSpouse连接。这种逻辑规则包含丰富的背景信息,在知识获取和推理中得到了广泛的研究,通常基于马尔可夫逻辑网络。这儿有一些系统像WARMR,ALEPH和AMIE可以从KGs中自动提取逻辑规则。
Wang等人试图利用规则改善KG补全过程中的嵌入模型。在他们的研究中,通过利用嵌入模型生成的目标函数和规则的约束把KG补全当做为一个整数线性规划问题。以这种方式推断出的事实将是嵌入模型中最优先考虑的,并且符合所有规则。类似的,[24]介绍了通过马尔可夫逻辑网络的结合规则和嵌入模型的方法。然而,在[23]和[24]中,由于规则与嵌入模型分别建模,作为后处理的步骤,因此并不会有助于获得更好的嵌入。
[23] Q. Wang, B. Wang, and L. Guo, “Knowledge base completion
using embeddings and rules,” in Proc. 24th Int. Joint Conf. Artif.
Intell., 2015, pp. 1859–1865.[24] Z. Wei, J. Zhao, K. Liu, Z. Qi, Z. Sun, and G. Tian, “Large-scale
knowledge base completion: Inferring via grounding network
sampling over selected instances,” in Proc. 24th ACM Int. Conf.
Inf. Knowl. Manage., 2015, pp. 1331–1340.
KALE
Guo等人提出了一种将KG事实和逻辑规则同时嵌入的联合模型。这种方法的一个关键组成部分,称为KALE,是在一个统一的框架中表示和对事实和规则建模。具体来说,事实(h,r,t)被看作是一个基本原子,其真值被定义为:
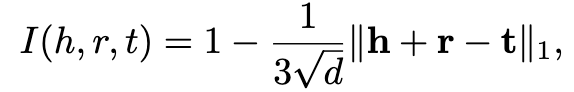
其中,d是嵌入向量的维度,I(h,r,t)∈[0,1] 是TransE评分函数的线性转换版本表示事实成立的可能性。逻辑规则首先被实例化为基本规则,比如可以把∀x, y : HasWife(x, y) ⇒ HasSpouse(x, y)转变为HasWife(AlfredHitchcock,AlmaReville) ⇒ HasSpouse(AlfredHitchcock,AlmaReville).然后,将基本规则可以解释为通过将基本原子与逻辑连接词(比如∧和⇒)组合而构造的复杂公式,并采用t-范数模糊逻辑进行建模。基本规则的真值是通过特定的基于t-范数的逻辑连接词,构成基本原子的真值的组合,比如:
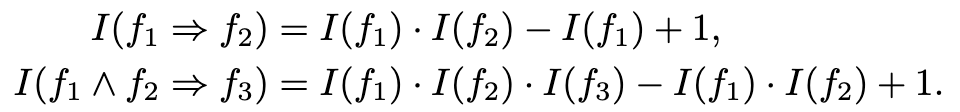
这个值也在[0,1]的范围内,表示在多大程度上满足了基本规则。以这种方式,KALE在一个统一的框架中表示事实和规则,分别是原子公式和复杂公式。在统一事实和规则之后,KALE最小化了两者学习实体和关系嵌入的全局损失。因此,所学习的嵌入不仅与事实兼容,而且与规则兼容,这对于知识获取和推理更为有效。
下图提供了该框架的简单图示:
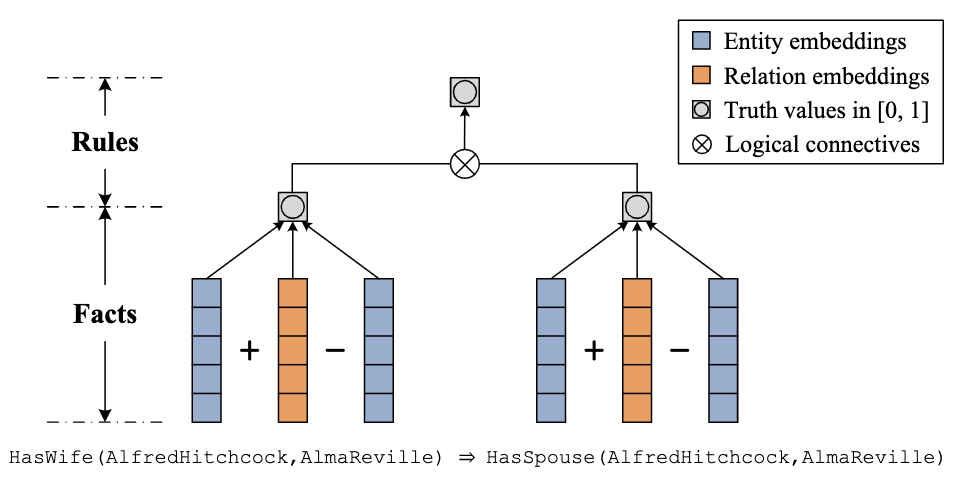
Rocktaschel等人设计了一个类似于KALE的模型。然而,在他们的工作中,是为实体对而不是单个实体引入向量嵌入,使其特别适用于关系提取。由于实体确实没有自己的嵌入关系,无法有效地发现未配对实体之间的关系。它和KALE都有一个缺点是:在学习它们的模型之前,它们必须将普遍量化的规则实例化为基本规则。该基本的过程可能在时间和空间上效率极低,尤其当KG中存在大量的实体且规则本身是复杂时或者规则本身就很复杂时。
要解决此问题,Demeester等人最近提出了一种扩展,其核心思想是利用逻辑正则化关系嵌入的影响避免接地(grounding)。例如,给定一个普遍量化规则HasWife(x, y) ⇒ HasSpouse(x, y)尝试只使用两个关系的嵌入HasWife和HasSpouse对其进行建模,而无需实例化在KG中的具体的实体x和y。然而,此策略仅适用于最简单形式的规则∀x, y : ri(x, y) ⇒ rj(x, y),并且不能推广到更复杂的规则。
利用其他信息
Entity Attributes
实体属性。Nickel等认为KGs中的关系可以表示实体(例如,AlfredHitchcock、HasWfe、AlmaReville)和实体属性(例如,AlfredHitchcock、性别、男性)之间的关系,但大多数KG嵌入技术没有明确区分关系和属性。以张量分解模型RESCAL为例。在这个模型中,每个KG关系被编码为张量的一个片段,无论它表示一个真关系还是一个属性。这种对属性的直接处理将显着地增加张量的维度,然而,这个张量中的大量条目将被浪费。为了解决这一问题,[22]建议明确区分属性和关系。关系仍然是用张量编码的,而属性则是在单独的实体属性矩阵中编码的。然后,将该矩阵与张量一起分解,以便同时学习实体、关系和属性的表示。类似的想法后来在平移距离模型中进行了研究。
[22] M. Nickel, V. Tresp, and H.-P. Kriegel, “Factorizing YAGO: Scal-
able machine learning for linked data,” in Proc. 21st Int. Conf.
World Wide Web, 2012, pp. 271–280.
Temporal Information
Jiang等[115]观察到KGs事实通常对时间是敏感的,例如(Alfredhtchock,Bornin,Leytonstone)发生在1899年,而(Alfredhtchock,Diedin,Belair)在1980年。基于这种观察,他们提出了时间感知嵌入模型。该模型的思想是在时间敏感的关系对上加入时间顺序约束,例如:Bornin和Deedin。给定这样的一对(r_i,r_j),先前的关系应该接近于随后的关系时间转换后的关系,即,M_r_i ≈ r_j,其中M为在关系之间的捕获时间顺序信息的转换矩阵。
在加入这样的时间顺序约束之后,[115]能够学习在时间上一致的关系嵌入。Esteban等人试图对KGs的时间演化进行建模。在他们的模型中,他们使用标记的四元组表示的事件比如(h,r,t,s;True)和(h,r,t,s;False),分别表明该事实在时间s出现和消失。然后将每个四元组建模为h、r 、t和s,其中s是时间特征向量。该模型在医学和传感器数据等动态领域表现良好。Trivdi等[117]最近提出,随着时间的推移,学习非线性进化的实体表示,以便在动态KGs上进行时间的推理。动态KG中的每个事实可以表示为四元组(h,r,t,s),表示头实体h与尾实体t在时间s上才会存在关系r。然后通过用时间点过程[118]来模拟事实的发生,用双线性评分函数得到实体间的多关系交互情况,以及利用深度递归神经网络学习非线性进化的实体表示。这种方法在链接预测,特别是时间预测方面表现很好。
[115] T. Jiang, T. Liu, T. Ge, L. Sha, S. Li, B. Chang, and Z. Sui,
“Encoding temporal information for time-aware link prediction,”
in Proc. Conf. Empirical Methods Natural Language Process., 2016,
pp. 2350–2354.
[117] R. Trivedi, H. Dai, Y. Wang, and L. Song, “Know-Evolve: Deep
temporal reasoning for dynamic knowledge graphs,” inProc. 34th
Int. Conf. Mach. Learn., 2017, pp. 3462–3471.
[118] D. R. Cox and P. A. W. Lewis, “Multivariate point processes,” in
Proc. 6th Berkeley Symp., vol. 3, 1972, pp. 401–448.
Graph Structures
Feng等人[119]提出了一种利用三种图结构学习实体和关系表示的图感知嵌入模型。第一个是邻域上下文,它实际上相当于在KG中观察到的三元组。第二个是路径上下文,和上面讨论的关系路径类似。最后一个是边缘上下文,在之前介绍的方法中都没有考虑到这一点。给定一个特定的实体,它的边缘上下文被定义为链接到该实体的所有类型的关系,仅仅基于这样的直觉,所有这些关系也都代表着这个实体。例如,AlfredHitchcock的边缘上下文可能包括BornIn、Deedin、HasWife和DirectorOf等关系,所有这些都表明AlfredHitchcock是一个人或者更准确地说他是一个导演。实验结果进一步证明了这些图结构建模的有效性。Jiang[121]等人建议从事实直接的上下文来估计其合理性。对于事实(h,r,t),将它的直接上下文定义为:(i)在三元组中h是头实体,(ii) 在三元组中h是尾实体,(iii) 在三元组中t是头实体,(iv) 在三元组中t是尾实体,(v)两个实体是h和t且具有任意关系的三元组。该研究表明,在预测多关系数据的链接是有效的。
[119] J. Feng, M. Huang, Y. Yang, and x. zhu, “GAKE: Graph aware
knowledge embedding,” in Proc. 26th Int. Conf. Comput. Linguis-
tics, 2016, pp. 641–651.
个人觉得这篇提出的第三种图结构是个不错的点,近几年也有一些文章围绕这方面展开。[121] X. Jiang, V. Tresp, Y. Huang, and M. Nickel, “Link prediction in
multi-relational graphs using additive models,” inProc. Int. Conf.
Semantic Technol. Meet Recommender Syst. Big Data, 2012, pp. 1–12.
其他相关学习方法介绍
另一条研究思路是将KG嵌入与其他关系结合在一起。例如,路径排序算法(PRA),它是采用不同类型的算法的方法。Dong[69]等人提出了通过融合系统将MLP与PRA相结合的方法。具体地, 在分别对这两种模型进行拟合后,它们使用MLP和PRA的输出作为标量特征,通过训练二分类器学习一个最终的融合层。他们发现融合这两种模型能够改善性能:融合系统的结果是:ROC曲线下的面积为0.911,而PRA是0.882 和MLP是0.884。
[122]设计了一个通用框架,将潜在变量模型和可观测变量模型结合起来(latent and observable variable models)。特别是,如果将Rescal与PRA结合,则打分函数变为:
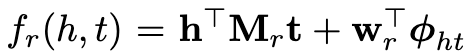
其中第一项是RESCALE评分函数和第二项是PRA评分函数,其中Φht是由路径特征组成的特征向量,w_r是这些特征的权值。这是一个联合模型,可以通过交替优化RESCAL参数和PRA参数来进行训练。在组合后,RESCAL只需对不能用PRA建模的“残差”进行建模,这需要较小的潜在维数,并要加快训练速度。
[69] X. Dong, E. Gabrilovich, G. Heitz, W. Horn, N. Lao, K. Murphy,
T. Strohmann, S. Sun, and W. Zhang, “Knowledge vault: A web-
scale approach to probabilistic knowledge fusion,” in Proc. 20th
ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2014, pp.
601–610.[112] T. Rockt ̈ aschel, M. Boˇ snjak, S. Singh, and S. Riedel, “Low-
dimensional embeddings of logic,” inProc. ACL Workshop Seman-
tic Parsing, 2014, pp. 45–49.
KG的embedding在下游任务中的应用
在KG中的应用
In-KG应用是在KG范围内进行的应用,在此范围内学习实体和关系嵌入。文章将介绍四个这样的应用程序,即链接预测、三元组分类、实体分类和实体解析。所有的这些应用都是从不同的角度和应用上下文对KG输入进行各种细化(例如补全或去重)。
link prediction
链接预测通常指的是预测与给定实体有特定关系的实体的任务,即给定(r,t)预测h或给定(h,r)预测t,前者可以表示为(?,r,t),后者为(h,r,?)。
例如(?, DirectorOf, Psycho) 预测电影的导演是谁, (AlfredHitchcock, DirectorOf, ?) 相当于预测那个特定的人导演的电影是什么。
这本质上是一个KG补全的任务,即将缺失的知识添加到图谱中。这个链接预测任务有时也称为实体预测或实体排序。类似的也可以用来预测两个给定实体之间的关系,即(h,?,t)通常称为关系预测。
通过事先学习实体和关系表示,链接预测可以通过一个简单的排序过程来实现。预测任务以(?,r,t)为例。为预测头实体,可以将KG中每个实体h作为候选答案,然后为每个实体计算f(h’,t)分数。一旦对KG进行了嵌入模型的训练,就可以使用所学习的嵌入和评分函数轻松地实现这一点,例如,如果使用TransE进行KG嵌入,则使用f(h,t)=-||h‘+r-t||1/2。将这些分数按下降顺序排列将得到一个候选答案的排序列表。例如,对于预测任务(?,DirectorOf,Psycho) ,可以使用这个排序过程生成一个有序列表。预测任务(h,r,?)或(h,?,t)也可以以同样的方式进行。
为了进行评估,通常的做法是将正确答案的排列顺序记录在有序列表中,以便查看是否可以将正确答案排列在错误答案之前。在前面提到的 (?, DirectorOf, Psycho)正确答案AlfredHitchcock排在第2。正确答案排序数越小表示性能越好。基于这些排序设计了各种评价标准,如平均排序(预测的排序数字的平均值)、平均倒数排序(倒数排序的平均值)、Hits@n(n个正确排序所占的比例)、AUC-PR(准确率-召回率曲线下的面积)。
triple classification
三元组分类在于验证三元组表示的事实(h,r,t)真假,例如, (AlfredHitchcock,DirectorOf, Psycho)归类为一个真的事实,而 (JamesCameron, DirectorOf, Psycho)则归类一个假的事实。同样,这个任务也可以看作是对KG输入的补全,在以往的研究中得到广泛的应用。
回顾一下,一旦在KG上学会了一个嵌入模型,我们可以计算任何三元组(h,r,t)的得分,只要h,t ∈ E和r ∈ R,例如,假设使用TransE学习KG嵌入,则可以使用f(h,t) = -||h+r-t||1/2 计算得分。三元组分类可以简单地在三元组得分的基础上进行。分数高的三元组往往是真的事实。具体地说,我们为每一个关系r引入一个阈值δr。然后从任何的事实关系,即(h,r,t),如果它的分数f(h,t)高于δr则视为真,否则则视为假。通过这种方法,我们得到了每一个关系的三元组分类器。传统的分类指标可以用来评估这个任务,例如微观和宏观的平均精度。由于对于每一个三元组实值分数都将与二进制标签一起输出,排序指标也可以在这里使用,例如平均精度均值。
entity classification
实体分类的目的是将实体划分为不同的语义类别,例如,AlfredHitchcock是一个人,Psycho是一部创造作品。由于在大多数情况下,关系编码实体类型(表示为IsA)包含在KG中,并且已经包含在嵌入的过程中,因此实体分类可以看作是一个具体的链接预测任务,即(x,IsA,?)。类似的预测和评估方法的具体细节可以看链接预测那一节,实体分类显然也是一个KG补全问题。
entity resolution
实体解析包括验证两个实体是否指的是同一个对象。在一些KGs中,许多节点实际上指的是相同的对象,例如,在Cora 数据集中,包含了作者、标题和地点字段的引用,作者或地点的名称可以用不同的方式编写。实体解析是删除这些重复的节点的任务。
Bordes等人考虑了这样一种场景,其中KG已经包含了一个关系,该关系声明两个实体是否相等(表示为EqualTo),并且已经学习了该关系的嵌入。在这种情况下,实体解析退化为三元组分类问题,即,判断三元组(x,EqualTo,y)是否成立或者这个三元组成立有多大的可能性。通过嵌入模型输出的三元组评分可以直接用于这种预测(详见三元组分类)。然而,这种直观的策略并不总是有效,因为并非所有的KG都编码EqualTo关系。
Nickel等人提出仅基于实体表示来执行实体解析。具体地,给定两个实体x, y和它们的向量表示x, y, 则x和y之间的相似性为:
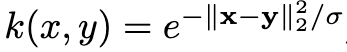
这个相似度评分用于度量x和y指向同一实体的可能性。即使在KG输入中没有编码EqualTo关系,新策略也可以起作用。AUC-PR是对于这种任务应用最广泛的评价指标。
实体解析,也常被称之为实体对齐(entity alignment)和实体匹配(entity matching),在知识融合中,主要用于消除异构数据中实体冲突的问题。
这里再区分一下实体对齐和实体消歧,其实二者的做法有很多类似。
实体消歧: 是用于解决同个实体名称在不同语句不同意义的问题。实体对齐: 是指多个异构数据源和实体,多源数据源的融合。
在KG之外的应用
Out-of-KG应用是那些突破KG输入边界并扩展到更广泛领域的应用。本文介绍了三种应用实例,包括关系抽取、问答和推荐系统。我们不寻求对这些任务进行系统性地概述或介绍最新的技术。相反,我们特别关注如何将KG嵌入应用于这些领域。我们希望它们能为KG嵌入的未来的应用提供新的视角。
Relation Extraction
关系抽取的目的是从已经检测到实体的纯文本中抽取关系事实。例如,从给定“Alfred Hitchcock directed Psycho”(Psycho)中可以检测到h=AlfredHitchcock和t=Psycho两个实体,一个关系抽取器应该预测这两个实体之间的关系是DirectorOf。关系抽取长期以来一直是自然语言处理中的一项重要任务,为扩展KGs提供了有效的方法。许多研究都试图利用KGs来完成这一任务,但通常作为远程监督来自动生成标记数据。但是这些方法仍然是基于文本的抽取,而忽略了KG自身推理新事实的能力。
最近,Weston等人提出将TransE与基于文本的抽取器相结合的方法,以便更好地进行关系抽取。具体来说,在训练阶段,他们从文本语料库中学习一个基于文本的抽取器,并从与该语料库对齐的KG中学习一个TransE模型。基于文本的抽取器对每个关系r与其文本提及m之间的相似性进行评分,即Stext(m,r)。这些评分可以用来预测它们的文本提及的关系,即证据来自文本语料库。与此同时,TransE模型对在KG中的每个缺失的的事实(h,r,t)的合理性进行打分。这些分数可以用来预测它们与KG中实体的交互关系,即证据来自KG。在测试阶段,给定两个实体h, t,以及所有与它们相关的关系Mht,首先使用基于文本的抽取器对进行预测得到r,然后对候选事实进行一个复合的评分计算,即:
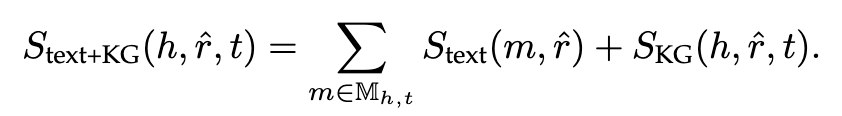
这个复合模型支持的预测不仅与文中提到的一致,而且与KG一致。实验结果进一步表明,与传统的基于文本的抽取器相比,采用TransE模型可以成功地改进传统的基于文本的抽取器。加入TransH和TransR后也观察到类似的改善。
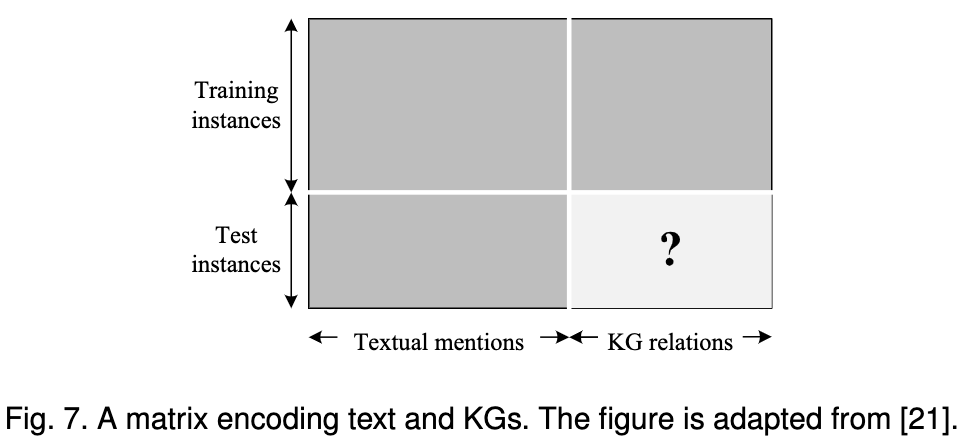
Riedel et al.[21]设计了一个不同的框架,通过将纯文本和KGs联合嵌入,来实现关系提取,在他们的工作中,文本和KGs被表示在同一个矩阵中。矩阵的每一行代表一对实体,每一列代表一个提及的文本或KG关系。如果两个实体与纯文本中的一个提到或与KGs中的关系同时出现,则将相应的条目设置为1,否则设置为0。对于训练实例(实体对),我们可以同时观察文本提及和KG关系,而KG关系作为重要的监督。但是对于测试实例,只有文本提到是可用的。然后,关系提取用于预测测试实该文提到,这项任务使用了协作过滤技术,它分解输入矩阵来学习实体对的向量嵌入和公斤关系。该框架还改进了传统的基于文本的提取器。下图给出了这个场景的一个简单插图:
Fan等[88]也提出了类似的观点关系提取方法。但在他们的工作中,第一矩阵中的一组列对应于文本特性并采用矩阵补全技术[128]代替矩阵分解技术。Chang等人[93]后来设计了一种基于张量的变体用三模张量编码纯文本和KGs,然后利用RESCAL模型分解张量。
[21] S. Riedel, L. Yao, A. Mccallum, and B. M. Marlin, “Relation
extraction with matrix factorization and universal schemas,” in
Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics: Human
Language Technol., 2013, pp. 74–84.[88] M. Fan, D. Zhao, Q. Zhou, Z. Liu, T. F. Zheng, and E. Y. Chang,
“Distant supervision for relation extraction with matrix comple-
tion,” inProc. 52nd Annu. Meeting Assoc. Comput. Linguistics, 2014,
pp. 839–849.
93] K.-W. Chang, W.-t. Yih, B. Yang, and C. Meek, “Typed tensor
decomposition of knowledge bases for relation extraction,” in
Proc. Conf. Empirical Methods Natural Language Process., 2014, pp.
1568–1579.[128] E. J. Cand` es and B. Recht, “Exact matrix completion via convex
optimization,” Foundations Comput. Math., vol. 9, no. 6, pp. 717–
772, 2009.
Question Answering
本文考虑一种特定的问答任务,给定一个自然语言表达的问题,从一个Kg中检索由三元组支持的答案。以下是一些例子:
Who directed Psycho? – AlfredHitchcock
(AlfredHitchcock, DirectorOf, Psycho)Where was A. Hitchcock born? – Leytonstone
(AlfredHitchcock, BornIn, Leytonstone)What was the nationality of A. Hitchcock? – England
(AlfredHitchcock, BornIn, Leytonstone)
(Leytonstone, LocatedIn, England)
KGs的使用简化了问题的回答,以结构化的格式组织了各种各样的答案。然而,由于自然语言的较大的变化性和KGs的巨大的规模,这仍然是一个具有挑战性的任务。
Bordes等人[11] [12]为这项任务引入了一个基于嵌入式的框架。该方法的核心思想是学习单词和KG成分的低维向量嵌入,使问题的表示和相应的答案在嵌入空间中相互接近。具体地说,让q表示一个问题和a表示一个候选答案。函数S(q,a),基于向量映射进行,目的是给问题答案之间的相似性进行评分,即
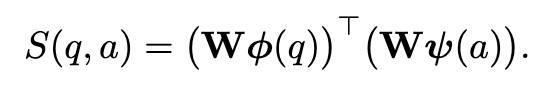
上式中W是一个包含单词、实体和关系嵌入的矩阵;Φ(q)和ψ(a)是两个稀疏向量,前者表示问题中出现的单词,后者表示答案中出现的实体和关系。WΦ(q)和Wψ(a)分别是问题和答案在嵌入空间中的向量表示。两者都是各自成分的嵌入组合,即词汇、实体和关系。如果问题问的是正确答案,S(.,.)生成一个高分,否则和较低的评分。给定一组由问题和正确答案配对组成的训练集,可以通过使用典型的成对排序优化来学习嵌入W,这使得一对正确的得分高于任何一对错误的得分。训练集可以通过众包机制创建,也可以通过在KGs上自动生成种子模式来创建。通过对W训练,在测试时,对于给定的问题q,预测答案为:
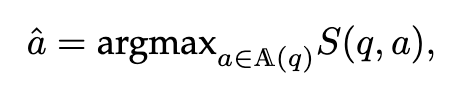
上式中A(q)是候选答案集。Bordes等人经验表明,这种直观的方法实现了较好的的结果,在不使用任何词典,或额外的步骤词性标注规则,语法或依赖项解析在训练最传统的问答系统。
[11] A. Bordes, J. Weston, and N. Usunier, “Open question answering
with weakly supervised embedding models,” in Proc. Joint Eur.
Conf. Mach. Learn. Knowl. Discovery Databases, 2014, pp. 165–180.[12] A. Bordes, S. Chopra, and J. Weston, “Question answering with
subgraph embeddings,” in Proc. Conf. Empirical Methods Natural
Language Process., 2014, pp. 615–620.
Recommender Systems
系统推荐向用户提供关于他们可能希望购买或检查的商品的建议。在不同的推荐策略中,将用户与商品之间的交互建模为用户与商品之间的即时表示的产品的协同过滤技术取得了显著的成功。然而,这样的技术并不总是有效,因为用户-项目交互可能非常稀疏。在这种情况下,将用户-物品交互和用户或物品的辅助信息相结合的混合推荐系统通常可以获得更好的性能。
Zhang等人[133]最近提出了一种混合推荐框架,该框架利用KG内的异构信息来提高协同过滤的质量。具体地说,他们使用存储在KG的三种类型的信息,包括结构性知识(事实三元组),文本知识(例如,一本书或一部电影的文本性的总结),和视觉知识(例如,一本书的封面或电影海报图片),为每项生成语义表示。为了对结构知识进行建模,采用了一种典型的KG嵌入技术,即TransR应用,它为每项学习结构表示。对于另外两种信息,采用叠加去噪自动编码器和叠加卷积自动编码器分别提取每项的文本表示和视觉表示。然后,为了进行协同过滤,将每个用户i表示为一个潜在向量u i,每一项j表示为一个潜在向量:
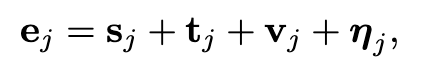
其中,sj、tj和vj分别是与该项相关联的结构表示、文本表示和视觉表示,而hj是一个偏移向量。然后将用户i对item j的偏好建模为两个潜在向量的乘积,即 uT_i*e_j。利用对优先级的排序优化来学习这些潜在向量。最后,在测试时,给定目标用户i,可以根据下面的排序标准进行item推荐:
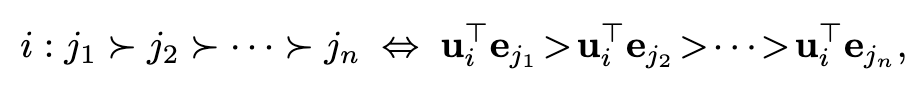
上式中i : js > jt表示用户i更喜欢项目js而不是jt。实验结果证明了从KG中学习的三种类型的表示方法在推荐系统中的有效性。
[论文本身链接][https://ieeexplore.ieee.org/document/8047276]
除论文本身,还参考了一些总结
[一个同学关于论文前半部分的总结][https://www.jianshu.com/p/438f479a1985]
[原文翻译版][https://new.qq.com/rain/a/20190826A0N3ZI],也是本博文主要“借鉴”对象,首发于公众号“专知”